






文献信息:朱斐,吴文,伏玉琛,刘全.基于双深度网络的安全深度强化学习方法[J].计算机学报,2019,42(08):1812-1826.
原文链接:http://cjc.ict.ac.cn/online/onlinepaper/42-8-10-201981695624.pdf
摘要:
深度强化学习利用深度学习感知环境信息,使用强化学习求解最优决策,是当前人工智能领域的主要研究热点之一。然而,大部分深度强化学习的工作未考虑安全问题,有些方法甚至特意加入带随机性质的探索来扩展采样的覆盖面,以期望获得更好的近似最优解。可是,不受安全控制的探索性学习很可能会带来重大风险。针对上述问题,提出了一种基于双深度网络的安全深度强化学习(Duel Deep Network based Secure Deep Reinforcement Learning, DDN-SDRL)方法。DDN-SDRL方法设计了危险样本经验池和安全样本经验池,其中危险样本经验池用于记录探索失败时的临界状态和危险状态的样本,而安全样本经验池用于记录剔除了临界状态和危险状态的样本。DDN-SDRL方法在原始网络模型上增加了一个深度Q网络来训练危险样本,将高维输入编码为抽象表示后再解码为特征;同时提出了惩罚项描述临界状态,并使用原始网络目标函数和惩罚项计算目标函数。DDN-SDRL方法以危险样本经验池中的样本为输入,使用深度Q网络训练得到惩罚项。由于DDN-SDRL方法利用了临界状态、危险状态及安全状态信息,因此Agent可以通过避开危险状态的样本、优先选取安全状态的样本来提高安全性。DDN-SDRL方法具有通用性,能与多种深度网络模型结合。实验验证了方法的有效性。
- 引言
- 背景意义
但是,目前很多人工智能的方法没有充分地做到控制风险、增加安全性,甚至有些方法在求解过程中特意加入了带有随机性质的探索性学习。而不受安全限制的探索性学习很可能会带来重大风险。如果在现实世界的任务中直接应用强化学习的方法,让Agent进行“试错式”探索学习,所做出的决策就有可能使系统陷入危险状态。强化学习的安全性问题引起了越来越多的关注。
安全深度强化学习是一个较新的研究内容。传统深度强化学习中,经典的DQN采用函数逼近的方法进行训练,为了去除训练过程中样本的相关性,DQN使用经验重放(ExperienceReplay)的机制,以等概率的方式抽取样本更新网络。然而无差别地从经验池中采样并不能体现样本的区分度,很难辨别“好”的样本和“差”的样本,很有可能出现导致Agent陷入危险状态的样本再次被用于网络训练的情况。绝大部分深度强化学习方法没有采取预防机制来避免Agent陷入危险状态。因此,必须限制Agent无约束的探索以保障安全性。
- 本文贡献
针对上述问题,本文提出基于双深度网络的安全深度强化学习(DualDeepNetworkBasedSecureDeepReinforcementLearning,DDN-SDRL)方法。DDN-SDRI方法通过分离历史经验训练导致Agent陷入危险状态的经验样本,使其重新组成新的经验池,有效地甄别了导致Agent陷入危险状态的样本经验;在原有网络的基础上再增加一个深度网络,采用新增的深度网络对新经验池样本进行训练,充分利用了提取出的样本;将训练结果作为惩罚项改进目标函数.DDN-SDRL方法具有较好的通用性,能与DQN、DuDQN、DRQN等网络相结合,并在Atari2600游戏环境中表现良好。
2基于双深度网路的安全深度强化学习
本文提出一种基于双深度网络的安全深度强化学习方法。整体模型由两个网络构成,即在原始网络模型(如DQN、DRQN、DuDQN等)中增加一个深度网络,用以训练临界于危险状态的临界样本和处于危险状态的危险样本,并采用双经验池方法,增加临界样本和危险样本经验池,充分利用其经验.该模型将高维输入编码为抽象表示然后再解码为特征。本节以实验环境Atari2600为例分析各个网络功能及网络间关系。
- 安全深度强化学习
为了将安全强化学习概念引入深度强化学习,定义相关名词:
定义1:当Agent进入某个状态导致任务失败时,将该状态定义为危险状态,记为
定义2.在危险状态
定义3.在安全距离d范围之内的状态定义为临界状态.
在本文的实验中,安全距离定义为m。,临界状态是Agent在游戏失败的前m帧状态,危险状态是Agent在游戏失败时的状态。
- 模型结构及分析
基于双深度网络的安全深度强化学习方法采用双网络模型架构,其中,增加的深度网络模型用于训练Agent历史遭遇的临界状态和危险状态。训练结果用于惩罚Agent的动作值函数。新加入的DQN对临界状态进行有针对性的训练,从而使得临界状态样本得到充分利用,减少Agent再次陷入危险状态的次数。使用双网络模型有两方面优点:(1)双网络模型充分利用了历史数据,使Agent效地避免再次陷入危险状态,增加了安全性,加快了训练速度;(2)通过额外训练临界状态与危险状态并改进动作值函数,使得目标函数避免朝危险状态方向收敛。目标函数的改进提升了Agent探索的安全性。基于双深度网络的安全深度强化学习方法如算法1所示。


DDN-SDRL方法将Agent与环境交互过程中产生的样本分为临界样本、危险样本和一般样本,其中,临界样本为从Agent任务失败开始的倒数m帧,危险样本为处于危险状态的样本。这两种样本存储在经验回放单元
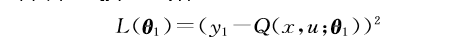
其中,
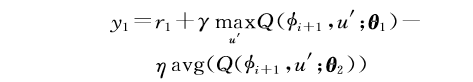
式中
DDN-SDRL方法改变了目标函数(增加了惩罚项),相应地,最优函数也会随之改变。然而,DDN-SDRL方法针对性地训练了临界样本,在危险状态边缘的状态所训练得到的最优策略会受到较大影响,使得函数避免陷入局部最优,因此可以有效限制Agent向危险状态方向探索。此外,由于安全样本距离危险状态边缘较远,目标函数惩罚项对其影响较小,保证了算法的稳定性。
- 网络训练过程
经过预处理的图像再由卷积神经网络提取特征,卷积过程为:
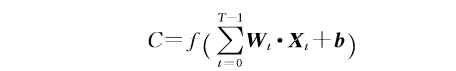
本文网络模型采用了3层卷积神经网络,在每层网络后又进行了非线性变换,提取图像特征。由于池化(Pooling)操作会使得提取得到的特征忽视位置信息,而在实验环境中位置信息也会对奖赏产生较大影响,因此,DDN-SDRL方法在通过卷积神经网络提取特征后未进行池化操作.
在网络的全连接层中,DDN-SDRL方法通过两层全连接层以完成最终的从状态到动作的映射。对于有m个输入节点n个输出节点的全连接层而言,其更新过程可以表示为
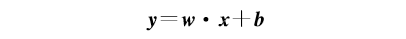
网络最终输出值为动作值函数,在DDN-SDRL方法中,以其均值作为惩罚项.
3实验结果及分析
- 实验平台及参数设置
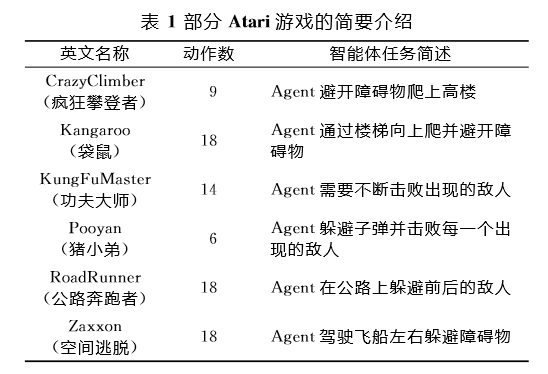
本文采用的游戏环境是基于人工智能公司OpenAIgym工具包中的Atari2600游戏实验平台。Atari2600游戏主要包括射击类、战略类、体育竞技类等方面的策略游戏,为研究人员提供了种类多样的实验环境。实验采用的处理器为Intei7-7820X(八核),主频为3.6GHz,内存为16GB。由于模型中大多用到了卷积运算和矩阵运算,因此使用了GTX1080Ti图形处理器对模型进行辅助加速运算。本文在Atari2600游戏中选取了6个游戏进行评估,表1为相关游戏任务的简要介绍。
为了更好地比较各方法的优劣,实验中每一种游戏都使用了相同的参数设置。鉴于在将强化学习方法应用于深度学习问题时,会导致不稳定现象的发生。本文在实验中采用了一些措施以保证模型的稳定性,主要包括:(1)由于Agent根据Q值选择动作所消耗的时间远大于网络传播时间,为了平衡两者差异,采用跳帧技术来缓和,即在每4帧状态下都采取相同的动作,并以累积奖赏作为总奖赏,每过4帧再根据ε-贪心策略选择下一个动作,若在跳帧过程中出现终止状态则实验结束;(2)在Atari2600游戏环境中,不同游戏的奖赏范围波动较大,这会造成较大的得分差异,因此,实验中将正奖赏设为+1,负奖赏设为-1,其余不变。这样不仅可以更方便快捷地在不同算法间进行比较,而且简化了奖赏的设置,可以明确动作带来的优劣,使得判断更加简明;(3)为了防止策略陷入局部最优,提升算法稳定性,将损失函数进行裁剪:损失值在区间[-1,1]之外的取损失值的绝对值;损失值在[-1,1]之内的则采用上述损失函数进行随机梯度下降操作。
实验中所有模型均采用均方根随机梯度下降方法(RootMeanSquarePropagation,RMSProp)来更新网络参数。为了降低动能,RMSProp方法中的动量系数设置为0.95.经验回放单元最大存放100万个样本。由于训练开始阶段没有充足的样本数量,不能够满足样本多样性的要求,因此,在训练的前50000步,Agent根据随机策略生成足够的样本分别保存到经验回放单元D和
- 实验结果及分析
在强化学习中,通常使用累积奖赏作为评判策略优劣的标准。由于深度学习训练周期长、训练数据庞大,训练效果不稳定,通常利用一个情节所获得的累积奖赏作为评估标准,通过分阶段统计每个情节奖赏大小评估模型优劣。在实验中,分别选择DQN、DuDQN 和DRQN网络模型作为原始网络,将DDN-SDRL应用到上述3种网络模型中,形成带安全机制的DQN、带安全机制的DuDQN 和带安全机制的DRQN,分别记为DQN-SE、DuDQN-SE和DRQN-SE。
图1-6图对比了3种原始网络(DQN、DuDQN 和DRQN)与3种带安全机制的网络(DQN-SE、DuDQN-SE和DRQN-SE)在六种游戏中的训练结果。图中纵坐标为平均每情节奖赏值,横坐标为训练情节数。
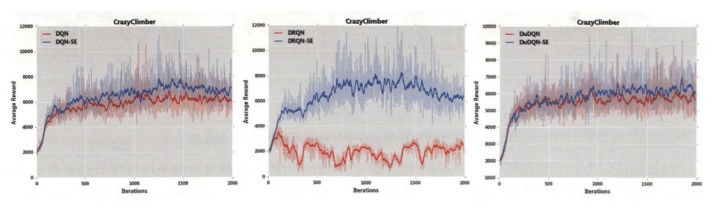
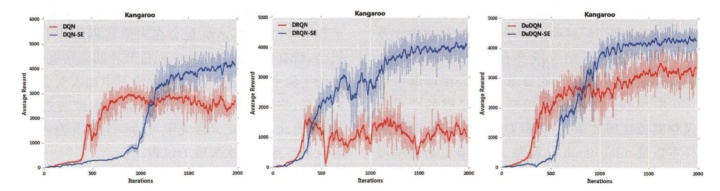
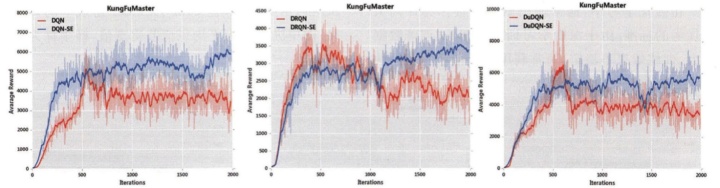
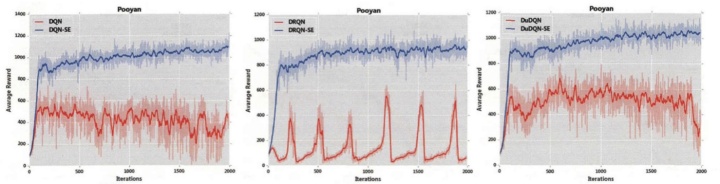
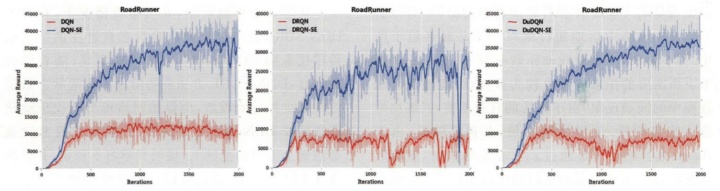
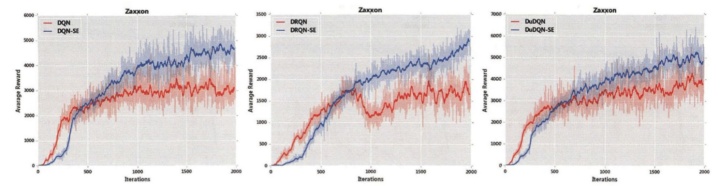
通过对比实验,可以分析得到适用DDN-SDRL方法的环境所具备的特点,主要包括:(1)在Agent探索的环境中存在较多可表示的导致游戏失败的状态,由于DDN-SDRL是针对临界和危险状态样本进行训练的模型,环境中导致危险状态的可能越多,其改进能力越强;(2)在一个情节中的危险状态与完全安全状态之间存在着较大的间隔。由于网络输入状态是Agent在学习过程中的灰度图像,若危险性状态与完全安全状态间隔较小,图像区分度也变得较低,这会使得DDN-SDRL对危险状态和安全状态的区分造成偏差,进而影响训练结果;(3)在动作较少的环境中,DDN-SDRL可以通过自我训练快速提高Agent的表现,反之,对于存在较多动作的环境,DDN-SDRL在训练开始阶段可能存在着训练效果不明显的状况,随着训练的推进,训练效果会逐渐改善,最终效果优于原始模型。为了直观表示DDN-SDRL的最终效果,实验统计了模型在不同训练阶段产生的危险状态数量。
图7显示了随着训练的不断进行,各个模型在不同训练阶段产生危险状态的数量。纵坐标代表平均每阶段产生的危险状态数量。
好的网络模型应该在测试阶段依然有良好的表现,Agent会根据训练好的策略执行任务也能获得优秀的表现。本文在2000个训练阶段结束后对训练所得的模型进行测试。在测试中,步长设置为10个阶段,每个阶段有10000个时间步,Agent的行为策略为ε-贪心策略,ε设为0.05。本文对每一个模型进表2给出了各模型在6个游戏中的测试结果
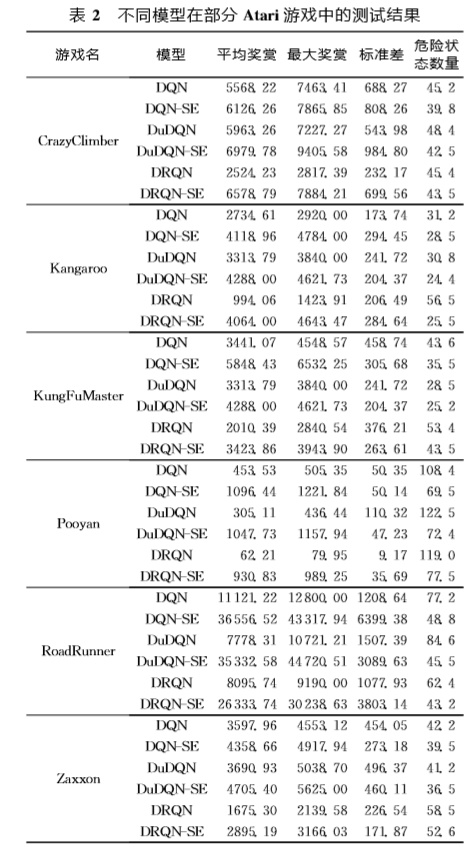
从表2中可以看出,利用了DDN-SDRL方法的模型在测试后的最高奖赏和平均奖赏指标中都是最高的,即DQN-SE、DuDQN-SE和DRQN-SE这3种模型表现分别优于DQN、DuDQN 和DRQN。采用了DDN-SDRL的网络模型在测试阶段遭遇的灾难性数量也是最少的,说明在模型中增加了安全性限制后,可以减少带来灾难性状态的选择,使得控制决策更为安全有效。此外,DDN-SDRL在3种不同的网络模型中均取得较好的效果,也体现出模型具有一定的通用性。
值得注意的是,测试结果中不同游戏环境表现出的标准差差别较大,而获得平均奖赏较大的模型其标准差也较高。多种因素造成了该现象,其中一个重要的原因就是模型训练结果有一定的波动,强化学习的探索性导致其训练无法达到十分精确的结果,最终导致在测试阶段的波动。而获得平均奖赏较高的模型,其相对波动更大。因此,测试结果表现出平均奖赏较大的模型标准差较大。
4结论:
以DQN模型为代表的深度强化学习方法已经在基于视觉的深度强化学习问题中取得了突破。然而这些网络模型并没有考虑实际环境中对Agent及所控制对象的保护。在实际环境中,由于成本问题,不能使Agent无限制地陷入危险状态。为了避免Agent在训练过程中陷入危险状态,本文提出一种基于双深度网络的安全深度强化学习方法。DDN-SDRL方法通过建立双经验池分离临界样本,并使用DQN网络对临界样本进行针对性训练;另一方面,目标函数加入惩罚项,对Agent的探索进行适当的限制。本文通过6个Atari 2600游戏实验验证了DDN-SDRL方法的有效性,并在DQN、DuDQN 和DRQN这3种网络模型中应用了DDN-SDRL方法。实验表明,加入了DDN-SDRL方法的网络模型在游戏平均每情节奖赏中具有优势。而成功应用于3种深度强化学习模型则说明DDN-SDRL方法具有较强的泛化能力。此外,针对训练结束后的模型进行测试的结果也表明,利用了DDN-SDRL方法的网络模型在应用任务中具有较好的稳定性。然而,加入了DDN-SDRL方法的网络模型在训练中依然存在着波动范围大、训练不稳定的现象。因此,下一步将针对模型的稳定性开展研究,通过进一步改进算法,达到减小方差并提升稳定性的效果。
5个人总结与思考
强化学习本质上是一种“试错”,在不断地尝试中获取经验,好的经验得到神话,差的经验得到衰减。但是,正是因为这种机制,强化学习需要通过大量的训练来搜索最优策略,并且为了尽可能地不要陷入局部最优,需要始终保持一定的探索性,从而可以探索到新的策略。在一些游戏中,这种方式还可以实现,因为游戏可以不断重复,并且失败的成本很低。但是对于一些现实中的问题,比如自动驾驶、对抗博弈等一些场景,失败的成本很高,因此需要高效地从曾经的错误中进行学习。
而这篇文章,引入了错误样本经验池,用于单独训练一个网络,并将其输出作为惩罚项,从而减少了危险状态的出现次数。个人理解,这种方式可以看作是有一个人专门在旁边监督,在行动者可能步入较差的状况中时进行提醒,从而避免再次犯错。这方面的研究在很多实际中的应用是很广的。
6参考文献

















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









