








1
写在前面
在上一篇文章《计算机视觉那些事 | 深度学习基础篇(上)》中我们从基本的神经网络开始,介绍了从单层感知机到多层感知机(MLP),从前向传播到反向传播,以及常用激活函数的相关内容。在这篇文章中,我们会对深度学习中常用的损失函数和梯度下降优化算法进行介绍。同时,我们将进一步从全连接神经网络过渡到卷积神经网络,介绍卷积的相关知识。
2
常见的损失函数
在神经网络中,由于非线性激活函数的引入,使得通过求解法来寻找最优化的网络结构参数变得非常困难。因此网络参数需要通过梯度下降法进行多次迭代更新才能达到一个较优的组合。
在这个过程中,损失函数起到了举足轻重的作用。因为我们首先需要根据损失函数计算网络输出值(预测值f(X))与实际标签值(目标值Y)之间的误差,从而给网络的参数优化指明一个方向。有了合适的损失函数,配合梯度下降算法和反向传播就可以实现对网络参数的迭代优化。
在实际应用中,常用的损失函数主要有以下几种类型。
1)0-1损失函数
0-1损失函数是指样本的预测值与目标值相等则为0,否则为1,数学表达式如下所示:

在上一篇文章介绍的感知机中,一般所用的损失函数就是这种0-1损失函数。有时候为了留出一定的余地,会适当放开条件,从而得到以下表达式:
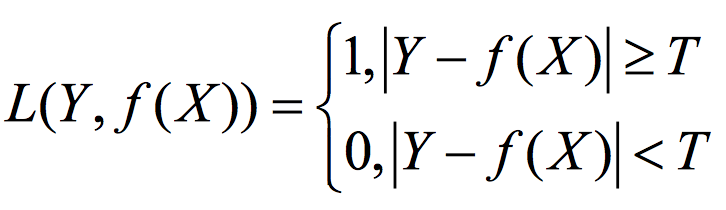
2)绝对值损失函数和平方损失函数
绝对值损失函数如下式所示,该损失函数常用于对收敛结果有严格要求的场合,比如目标检测中对物体大小和位置的预测、图像翻译任务中网络输出图像的计算等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2622
2622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









