





 本文介绍了如何在Ubuntu上安装Java环境(包括两种方法),然后利用Stanford OpenIE Python库解析文本,提取家庭关系三元组,并生成可视化图表。重点在于处理OpenIE输出的不完整信息并转换为标准形式。
本文介绍了如何在Ubuntu上安装Java环境(包括两种方法),然后利用Stanford OpenIE Python库解析文本,提取家庭关系三元组,并生成可视化图表。重点在于处理OpenIE输出的不完整信息并转换为标准形式。

(仅个人记录使用)
(Oracle VM VirtualBox, Ubuntu 20.04.1 LTS)
(Python 3.7, java-8-openjdk)
1. Need Java environment
wesley:Ubuntu 安装JDK (两方法,可切换)zhuanlan.zhihu.com
2. Install GraphViz (can generate graph.png)
$ sudo apt-get install graphviz3. Get the code (can firstly 'cd' to the dir you want)
$ git clone https://github.com/philipperemy/Stanford-OpenIE-Python.git4. Run
$ cd Stanford-OpenIE-Python
$ python3 main.py5. Expected results
|- {'subject': 'Barack Obama', 'relation': 'was', 'object': 'born'}
|- {'subject': 'Barack Obama', 'relation': 'was born in', 'object': 'Hawaii'}
|- {'subject': 'Richard Manning', 'relation': 'wrote', 'object': 'sentence'}
Graph generated: graph.png.
Corpus: According to this document, the city of Cumae in Ćolia, was, at an early period [...].
Found 1664 triples in the corpus.
|- {'subject': 'city', 'relation': 'is in', 'object': 'Ćolia'}
|- {'subject': 'Menapolus', 'relation': 'son of', 'object': 'Ithagenes'}
|- {'subject': 'Menapolus', 'relation': 'was Among', 'object': 'immigrants'}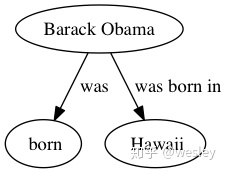
DETAILS
- Input text
text or input long article ('n' and 'r' will be removed)
with open('corpus/pg6130.txt', 'r', encoding='utf8') as r:
corpus = r.read().replace('n', ' ').replace('r', '')- Processing
client.annotate(text)or if do not need that much
client.annotate(corpus[0:50000])- Get the results
for triple in client.annotate(text):
print('|-', triple)like this:
|- {'subject': 'Barack Obama', 'relation': 'was', 'object': 'born'}
|- {'subject': 'Barack Obama', 'relation': 'was born in', 'object': 'Hawaii'}
|- {'subject': 'Richard Manning', 'relation': 'wrote', 'object': 'sentence'}- Generate graph (only based on the text)
graph_image = 'graph.png'
client.generate_graphviz_graph(text, graph_image)like this:
To generate more graph based on several sentences in 'corpus', for example:
for i, text in enumerate(corpus.split('.')):
graph_image = f'graph{i}.png'
client.generate_graphviz_graph(text, graph_image)FURTHER PROCESSING
For my own purpose, I need to get triples in form of (subject, relation, object), i.e.
Text: [Michael] is the proud father of the lovely [Donald]. [Dorothy]'s brother [Michael] and her went to get ice cream.
Triples: ('Donald', 'father', 'Michael'), ('Dorothy', 'brother', 'Michael')but actually, openIE gives:
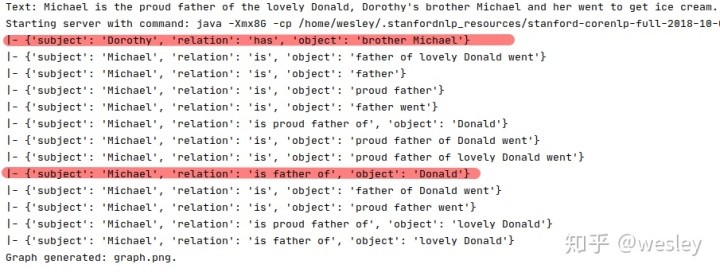
Therefore, I've modified the results it gives and get what I need:
- Remove '[' and ']', and remove comma ',' to integrate two sentences.
- Give the kinship beforehand
- Based on the results, to extract the triples (i.e. from those in red line)
- For those results are not obvious, try to guest by searching the closest Name
Now, from at most 20% up to at least 70% (only consider to get triples, not accuracy)
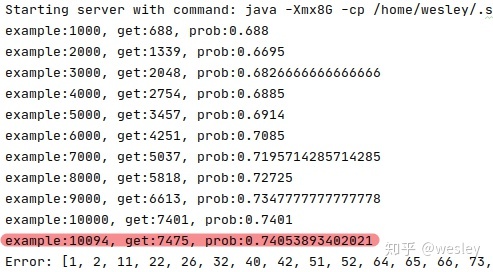
NOTE
- Stanford OpenIE is a Java implementation, and this is the python3 wrapper for it:
2. More information can be found here:
The Stanford Natural Language Processing Groupnlp.stanford.edu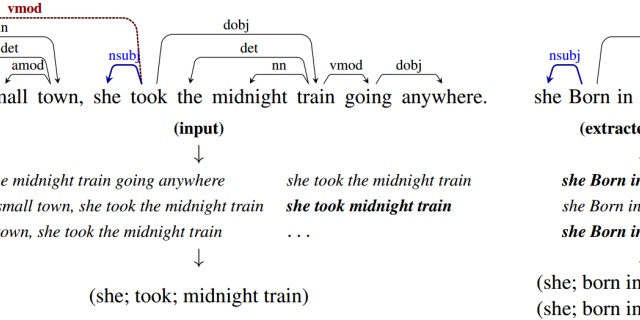
3. In that code, 'v1' is not available. (emm...)
CODE
(main.py)
(Not good enough, just record)
te = 0 # if test and print process, let te=1
te_ind = 52 # test example no.
path = "corpus/1.2,1.3_train.csv"
kinship = ['aunt', 'brother', 'brother-in-law', 'daughter', 'daughter-in-law', 'father',
'father-in-law', 'granddaughter', 'grandfather', 'grandmother', 'grandson', 'husband',
'mother', 'mother-in-law', 'nephew', 'niece', 'sister', 'sister-in-law', 'son',
'son-in-law', 'uncle', 'wife']
def get_closest_name(rel, lst, text, direction):
"""
# guest the object is the [ahead/next] closest NAME
:param rel: relation
:param lst: now we are in which lst, sub_lst or obj_lst
:param text: story text
:param direction: ahead or next
:return: Name
"""
dire = 0 if direction == 'ahead' else -1
for h in ['his', 'her']: # lots of situation with 'his/her'
if h in lst:
new_text = text.split(f'{h} {rel}')[dire].split(' ')
if not dire:
new_text = new_text[::-1]
for w in new_text:
if w.istitle():
return w
# if no 'his/her', we try to look around
new_text_1, new_text_2 = text.split(f'{rel}')[0].split(' '), text.split(f'{rel}')[-1].split(' ')
if not dire:
for w in new_text_1[::-1]:
if w.istitle():
return w
for w in new_text_2:
if w.istitle():
return w
else:
for w in new_text_2:
if w.istitle():
return w
for w in new_text_1[::-1]:
if w.istitle():
return w
return
with open(path, newline='') as f:
reader = csv.reader(f)
corr = 0
err = []
tri_lst = [] # save tri for all stories
with StanfordOpenIE() as client:
for ind, row in enumerate(tqdm(reader)):
# ind, story_, cstory_ = row[0], row[2], row[7]
cstory_ = row[7]
tri_one = [] # save tri for each story
if te and ind==te_ind:
print('Test here now...')
if ind > 0:
# Remove '[' and ']', and remove comma ',' to integrate two sentences.
if cstory_[-1] != '.':
cstory_ += '.'
cstory_ = cstory_.replace('[', '').replace(']', '') # .replace('.', ',', 1)
cstory_ = ','.join(cstory_.split('.')[:-1]) + '.'
if te: print(f'No.{ind}; Story: {cstory_}')
triples_corpus = client.annotate(cstory_)
for triple in triples_corpus:
flag = 0
if te: print('|-', triple)
sub_lst = triple['subject'].split(' ')
rel_lst = triple['relation'].split(' ')
obj_lst = triple['object'].split(' ')
if 'dad' in sub_lst:
sub_lst[sub_lst.index('dad')] = 'father'
if 'mon' in sub_lst:
sub_lst[sub_lst.index('mon')] = 'mother'
if 'dad' in rel_lst:
rel_lst[rel_lst.index('dad')] = 'father'
if 'mon' in rel_lst:
rel_lst[rel_lst.index('mon')] = 'mother'
if 'dad' in obj_lst:
obj_lst[obj_lst.index('dad')] = 'father'
if 'mon' in obj_lst:
obj_lst[obj_lst.index('mon')] = 'mother'
for w_o in obj_lst[::-1]:
if w_o.istitle():
name = w_o
break
else: name = None
if name and ('of' in rel_lst or rel_lst==['is']) and
(len(set(rel_lst) & set(kinship)) == 1 or len(set(obj_lst) & set(kinship)) == 1):
# is ... of situation, need exchange sub and obj
flag = 1
sub = name
rel = list((set(rel_lst) & set(kinship)) | (set(obj_lst) & set(kinship)))[0]
if sub_lst[0].istitle():
obj = sub_lst[0]
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'of !!! {tri}')
else: # if no name in sub_lst, try to guest
obj = get_closest_name(rel=rel, lst=obj_lst, text=cstory_, direction='ahead')
if obj:
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'of & guest !!! {tri}')
else: flag = 0
elif name and
(len(set(rel_lst) & set(kinship)) == 1 or len(set(obj_lst) & set(kinship)) == 1):
flag = 1
rel = list((set(rel_lst) & set(kinship)) | (set(obj_lst) & set(kinship)))[0]
obj = name
if sub_lst[0].istitle():
sub = sub_lst[0]
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'obj !!! {tri}')
else: # if no name in sub_lst, try to guest
sub = get_closest_name(rel=rel, lst=obj_lst, text=cstory_, direction='ahead')
if sub:
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'obj & guest !!! {tri}')
else: flag = 0
elif len(set(rel_lst) & set(kinship)) == 1 or len(set(obj_lst) & set(kinship)) == 1:
# if no name appear in obj_lst, try to guest
flag = 1
rel = list((set(rel_lst) & set(kinship)) | (set(obj_lst) & set(kinship)))[0]
if sub_lst[0].istitle():
sub = sub_lst[0]
obj = get_closest_name(rel=rel, lst=obj_lst, text=cstory_, direction='next')
if obj:
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'guest 3 !!! {tri})')
else: flag = 0
else:
flag = 0
if not flag: # if based on obj_lst cannot get triples, we try to look at sub_lst
for w_s in sub_lst[::-1]:
if w_s.istitle():
name = w_s
break
else:
name = None
if name and len(set(sub_lst) & set(kinship)) == 1:
rel = list(set(sub_lst) & set(kinship))[0]
if "'s" in sub_lst: # i.e. Guillermina 's father
sub = w_s
obj = get_closest_name(rel=rel, lst=sub_lst, text=cstory_, direction='next')
if obj:
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'sub & guest 1 !!! {tri})')
else:
obj = w_s
sub = get_closest_name(rel=rel, lst=sub_lst, text=cstory_, direction='ahead')
if sub:
tri = (sub, rel, obj)
tri_one.append(tri)
if te: print(f'sub & guest 2 !!! {tri})')
# else: flag = 0
if len(list(set(tri_one))) > 1: # 1.2,1.3_train.csv at least two triples
tri_lst.append(list(set(tri_one)))
corr += 1
else:
# print(f'No.{ind}; Story: {cstory_}')
# for triple in triples_corpus:
# print('|-', triple)
err.append(ind - 1)
if ind%1000 == 0:
print(f'example:{ind}, get:{corr}, prob:{corr/ind}')
print(f'example:{ind}, get:{corr}, prob:{corr / ind}')
print(f'Error: {err}')
# with open('corpus/err.txt', 'w') as ft:
# ft.write(str(err))
# python3 main.py > output.txtDATA
链接:https://pan.baidu.com/s/1sZxp0t6Q2EfRs175kUufSA
提取码:0826RUN (save results in output.txt)
$ python3 main.py > output.txt














 4439
4439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









