









StanfordCoreNLP中token踩过的坑
本文使用的是StanfordCoreNLP 4.4.0,可以从下面网站中download
https://stanfordnlp.github.io/CoreNLP/history.html
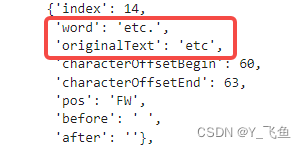
1. annotate中的word和originalText并不一致
originalText才是我们需要的token
import json
from stanfordcorenlp import StanfordCoreNLP
CORENLP_HOME = r"D:\Software\StanfordCoreNLP\stanford-corenlp-4.4.0"
client = StanfordCoreNLP(CORENLP_HOME, lang="en", memory='8g')
sentence = "Minicomputers, supercomputers, disk drives, CRT, CRU, etc., etc."
p = json.loads(client.annotate(sentence, properties={"annotators":"pos","outputFormat": "json"}))
original_text = [tok['originalText'] for tok in p['sentences'][0]['tokens']]
word = [tok['word'] for tok in p['sentences'][0]['tokens']]
p['sentences'][0]['tokens']
print("originalText:", original_text)
print("word:", word)
print("word_tokenize: ", client.word_tokenize(sentence))

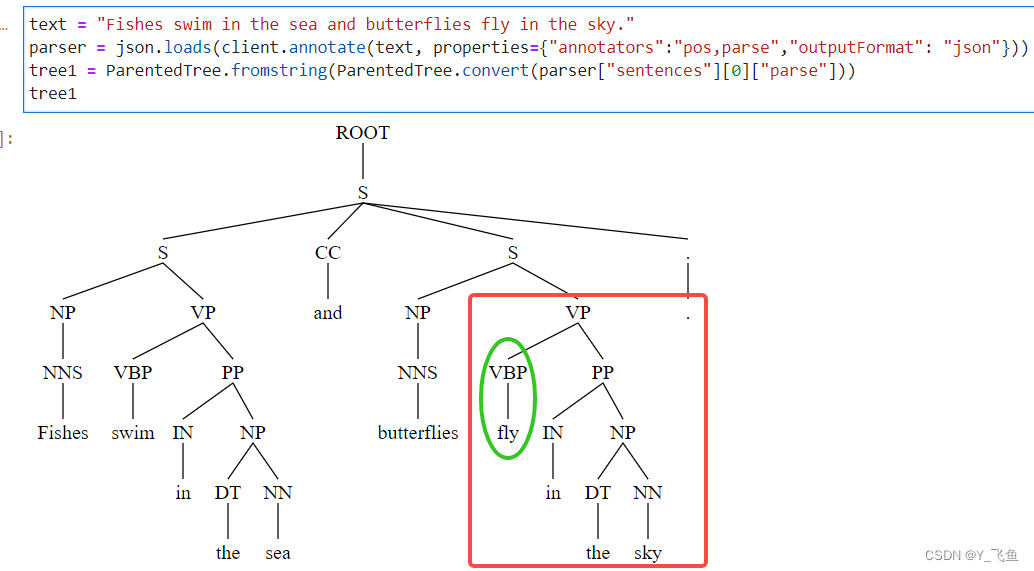
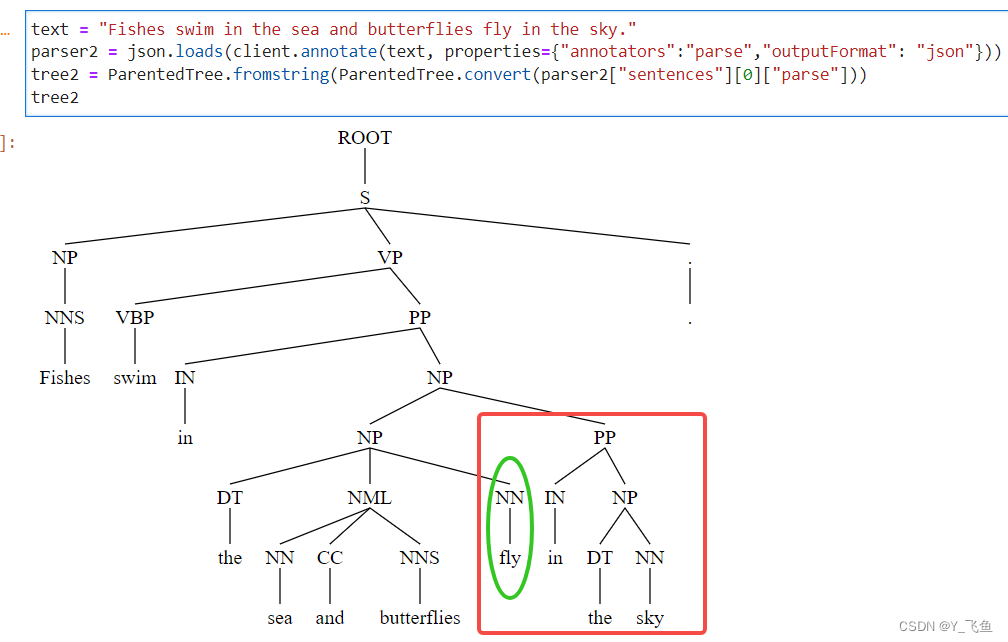
2. annotate使用parse一定要添加pos,否则parse tree是错误的
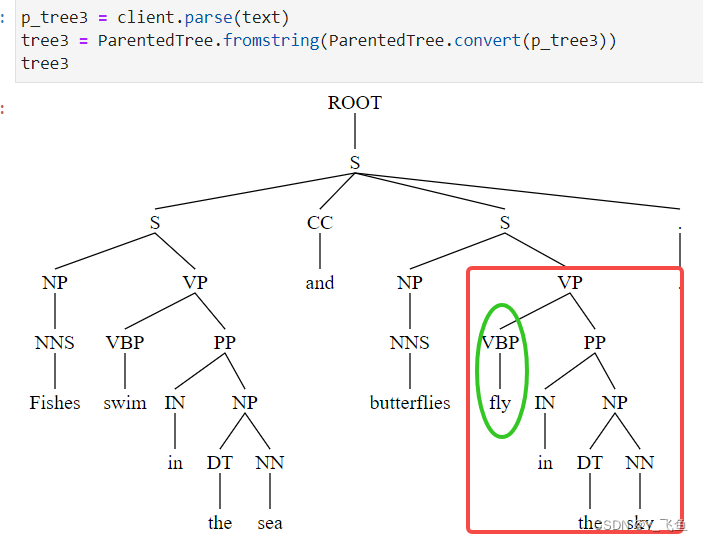
note:stanfordcorenlp使用annotate时,如果需要parse tree,则一定要添加pos,否则得到的parse tree是错误的。同时,也可以使用client.parse(text)
from stanfordcorenlp import StanfordCoreNLP
from nltk.tree import ParentedTree
import json
text = "Fishes swim in the sea and butterflies fly in the sky."
parser1 = json.loads(client.annotate(text, properties={"annotators":"pos,parse","outputFormat": "json"}))
tree1 = ParentedTree.fromstring(ParentedTree.convert(parser1 ["sentences"][0]["parse"]))
tree1
parser2 = json.loads(client.annotate(text, properties={"annotators":"parse","outputFormat": "json"}))
tree2 = ParentedTree.fromstring(ParentedTree.convert(parser2["sentences"][0]["parse"]))
tree2
p_tree3 = client.parse(text)
tree3 = ParentedTree.fromstring(ParentedTree.convert(p_tree3))
tree3

















 4287
4287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









