







Ceph之RADOS设计原理与实现读书笔记
随着云计算、大数据和人工智能逐渐成为信息时代的主旋律,Ceph正不断拓展自身的触角,从取代Swift成为OpenStack首选存储后端进入公众视野,到完美适配以Amazon S3为代表的公有云接口,再到征战下一个没有硝烟的虚拟化(技术)高地——容器。

作者:谢型果,严军
Ceph之RADOS设计原理与实现pdf txt mobi下载
Ceph之RADOS设计原理与实现(txt+pdf+epub+mobi电子书下载) - txtepub下载www.txtepub.com
Ceph之RADOS设计原理与实现阅读感悟
Ceph在设计之初被定位成用于管理大型分级存储网络的分布式文件系统。网络中的不同层级具有不同的故障容忍程度,因此也称为故障域。图2-1展示了一个具有3个层级(机架、主机、磁盘)的Ceph集群。
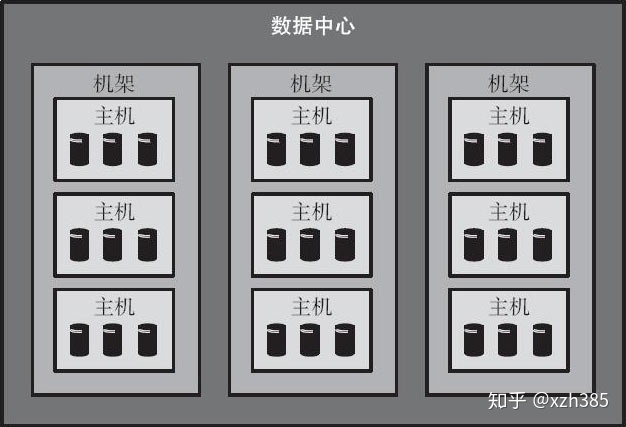
图2-1 具有3个层级的Ceph集群
在图2-1中,单个主机包含多个磁盘,每个机架包含多个主机,并采用独立的供电和网络交换系统,从而可以将整个集群以机架为单位划分为若干故障域。为了实现高可靠性,实际上要求数据的多个副本分布在不同机架的主机磁盘之上。因此,CRUSH首先应该是一种基于层级的深度优先遍历算法。此外,上述层级结构中,每个层级的结构特征也存在差异,一般而言,越处于顶层的其结构变化的可能性越小,反之越处于底层的则其结构变化越频繁。例如,大多数情况下一个Ceph集群自始至终只对应一个数据中心,但是主机或者磁盘数量随时间流逝则可能一直处于变化之中。因此,从这个角度而言,CRUSH还应该允许针对不同的层级按照其特点设置不同的选择算法,从而实现全局和动态最优。
在CRUSH的最初实现中,Sage一共设计了4种不同的基本选择算法,这些算法是实现其他更复杂算法的基础,它们各自的优缺点如表2-1所示。
表2-1 CRUSH基本选择算法对比

由表2-1可见,unique算法执行效率最高,但是抵御结构变化的能力最差;straw算法执行效率较低,但是抵御结构变化的能力最好;list和tree算法执行效率和抵御结构变化的能力介于unique与straw之间。如果综合考虑呈爆炸式增长的存储空间需求(导致需要添加元素)、在大型分布式存储系统中某些部件故障是常态(导致需要删除元素),以及愈发严苛的数据可靠性需求(导致需要将数据副本存储在更高级别的故障域中,例如不同的数据中心),那么针对任何层级采用straw算法都是一个不错的选择。事实上,这也是CRUSH算法的现状,在大多数将Ceph用于生产环境的案例中,除了straw算法之外,其他3种算法基本上形同虚设,因此我们将重点放在分析straw算法上。
顾名思义,straw算法将所有元素比作吸管,针对指定输入,为每个元素随机地计算一个长度,最后从中选择长度最长的那个元素(吸管)作为输出。这个过程被形象地称为抽签(draw),元素的长度称为签长。
显然straw算法的关键在于如何计算签长。理论上,如果所有元素构成完全一致,那么只需要将指定输入和元素自身唯一编号作为哈希输入即可计算出对应元素的签长。因此,如果样本容量足够大,那么最终所有元素被选择的概率都是相等的,从而保证数据在不同元素之间均匀分布。然而实际上,前期规划得再好的集群,其包含的存储设备随着时间的推移也会逐渐趋于异构化,例如,由于批次不同而导致的磁盘容量差异。显然,通常情况下,我们不应该对所有设备一视同仁,而是需要在CRUSH算法中引入一个额外的参数,称为权重,来体现设备之间的差异,让权重大(对应容量大)的设备分担更多的数据,权重小(对应容量小)的设备分担更少的数据,从而使得数据在异构存储网络中也能合理地分布。
将上述理论应用于straw算法,则可以通过使用权重对签长的计算过程进行调整来实现,即我们总是倾向于让权重大的元素有较大的概率获得更大的签长,从而在每次抽签中更容易胜出。因此,引入权重之后straw算法的执行结果将取决于3个因素:固定输入、元素编号和元素权重。这其中,元素编号起的是随机种子的作用,所以针对固定输入,straw算法实际上只受元素权重的影响。进一步地,如果每个元素的签长只与自身权重相关,则可以证明此时straw算法对于添加元素和删除元素的处理都是最优的。我们以添加元素为例进行论证。
1)假定当前集合中一共包含n个元素:
(e 1 ,e 2 ,…,e n )
2)向集合中添加新元素e n+1 :
(e 1 ,e 2 ,…,e n ,e n+1 )
3)针对任意输入x,加入e n+1 之前,分别计算每个元素签长并假定其中最大值为d max :
(d 1 ,d 2 ,…,d n )
4)因为新元素e n+1 的签长计算只与自身编号及自身权重相关,所以可以使用x独立计算其签长(同时其他元素的签长不受e n+1 加入的影响),假定为d n+1 ;
5)又因为straw算法总是选择最大的签长作为最终结果,所以:
如果d n+1 >d max ,那么x将被重新映射至新元素e n+1 ;反之,对x的已有映射结果无任何影响。
可见,添加一个元素,straw算法会随机地将一些原有元素中的数据重新映射至新加入的元素之中。同理,删除一个元素,straw算法会将该元素中全部数据随机地重新映射至其他元素之中。因此无论添加或者删除元素,都不会导致数据在除被添加或者删除之外的两个元素(即不相干的元素)之间进行迁移。
理论上straw算法是非常完美的,然而在straw算法实现整整8年之后,由于Ceph应用日益广泛,不断有用户向社区反馈,每次集群有新的OSD加入或者旧的OSD删除时,总会触发不相干的数据迁移,这迫使Sage对straw算法重新进行审视。原straw算法伪代码如下:
max_x = -1
max_item = -1
for each item:
x = hash(input, r)
x = x * item_straw
if x > max_x:
max_x = x
max_item = item
return max_item可见,算法执行的结果取决于每个元素根据输入(input)、随机因子(r)和item_straw计算得到的签长,而item_straw通过权重计算得到,伪代码如下:
reverse = rearrange all weights in reverse order
straw = -1
weight_diff_prev_total = 0
for each item:
item_straw = straw * 0x10000
weight_diff_prev = (reverse[current_item]–reverse[prev_item])*items_remain
weight_diff_prev_total += weight_diff_prev
weight_diff_next = (reverse[next_item]–reverse[current_item])*items_remain
scale = weight_diff_prev_total/(weight_diff_prev_total + weight_diff_next)
straw *= pow(1 / scale, 1 / items_remain)原straw算法中,将所有元素按其权重进行逆序排列后逐个计算每个元素的item_straw,计算过程中不断累积当前元素与前后元素的权重差值,以此作为计算下一个元素item_straw的基准。因此straw算法的最终结果不但取决于每个元素的自身权重,而且也与集合中所有其他元素的权重强相关,从而导致每次有元素加入集合或者被从集合中删除时,都会引起不相干的数据迁移。
出于兼容性考虑,Sage重新设计了一种针对原有straw算法进行修正的新算法,称为straw2。
straw2计算每个元素的签长时仅使用自身权重,因此可以完美反映Sage的初衷(也因此避免了不相干的数据迁移),同时计算也更加简单。其伪代码如下:
max_x = -1
max_item = -1
for each item:
x = hash(input, r)
x = ln(x / 65536) / weight
if x > max_x:
max_x = x
max_item = item
return max_item分析straw2的伪代码可知,针对输入和随机因子执行哈希后,结果落在[0,65535]之间,因此x/65536必然小于1,对其取自然对数(ln(x/65536))后结果为负值。进一步地,将其除以自身权重(weight)后,权重越大,结果越大(因为负得越少),从而体现出我们所期望的每个元素权重对于抽签结果的正反馈作用。
CRUSH基于上述基本选择算法完成数据映射,这个过程是受控的并且高度依赖于集群的拓扑描述——cluster map。不同的数据分布策略通过制定不同的placement rule来实现。placement rule实际上是一组包括最大副本数、故障(容灾)级别等在内的自定义约束条件,例如针对图2-1所示的集群,我们可以通过一条placement rule将互为镜像的3个数据副本(这也是Ceph的默认数据备份策略)分别写入位于不同机架的主机磁盘之上,以避免因为某个机架掉电而导致业务中断 。
针对指定输入x,CRUSH将输出一个包含n个不同目标存储对象(例如磁盘)的集合。CRUSH的计算过程中仅仅使用x、cluster map和placement rule作为哈希函数输入,因此如果cluster map不发生变化(一般而言placement rule不会轻易变化),那么结果就是确定的;同时由于使用的哈希函数是伪随机的,所以CRUSH选择每个目标存储对象的概率相对独立(然而我们在后面将会看到,受控的副本策略改变了这种独立性),从而可以保证数据在整个集群之间均匀分布。
cluster map是Ceph集群拓扑结构的逻辑描述形式。考虑到生产环境中集群通常具有形如“数据中心→机架→主机→磁盘”(参考图2-1)这样的层级拓扑,所以cluster map使用树这种数据结构来实现:每个叶子节点都是真实的最小物理存储设备(例如磁盘),称为device;所有中间节点统称为bucket,每个bucket可以是一些devices的集合,也可以是低一级的buckets集合;根节点称为root,是整个集群的入口。每个节点绑定一种类型,表示其在集群中所处的层级,也可以作为故障域,除此之外还包含一个集群唯一的数字标识。根节点与中间节点的数字标识都是负值,只有叶子节点,也就是device才拥有非负的数字标识,表明其是承载数据的真实设备。节点的权重属性用于对CRUSH的选择过程进行调整,使得数据分布更加合理。父节点权重是其所有孩子节点的权重之和。
表2-2列举了cluster map中一些常见的节点(层级)类型。
表2-2 cluster map常见的节点类型

需要注意的是,这里并非强调每个Ceph集群都一定要划分为如表2-2所示的11个层级,并且每种层级类型的名称必须固定不变,而是层级可以根据实际情况进行裁剪,名称也可以按照自身习惯进行修改。假定所有磁盘规格一致(这样每个磁盘的权重一致),我们可以绘制图2-1所示集群的cluster map,如图2-2所示。
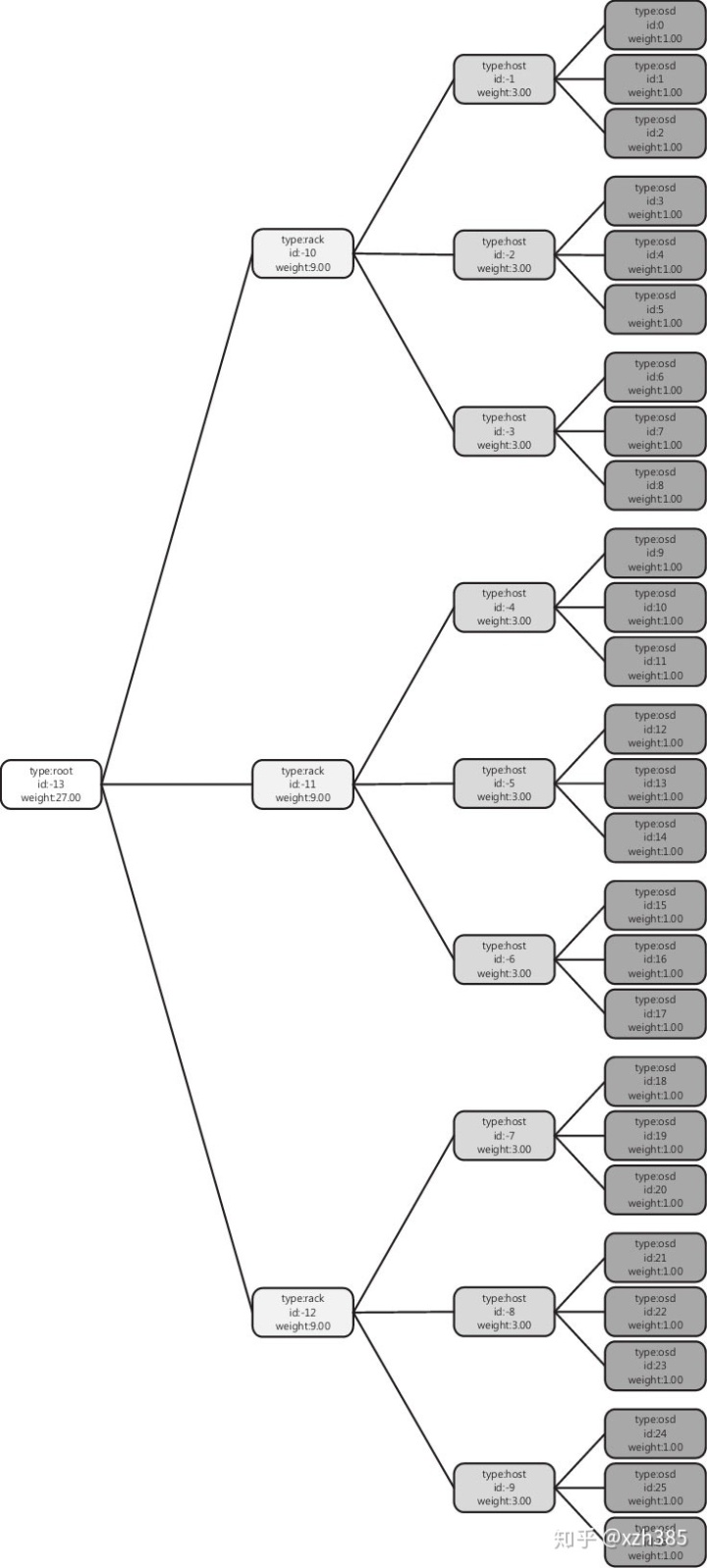
图2-2 图2-1所示集群
实现上,类似图2-2中这种树状的层级关系在cluster map中可以通过一张二维映射表建立。
<bucket, items>树中每个节点都是一个bucket(device也被抽象成为一种bucket类型),每个bucket都只保存自身所有直接孩子的编号。当bucket类型为device(对应图2-2中的os
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2320
2320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









