







问题现象:
一套十几个TPS的系统被执行2分钟(00:30-00:32)的夜维(删除历史过期的数据)搞挂了。
初步分析:
通过应用日志,定位到应用处理都卡在了一条SQL语句上,这个SQL要更新一个包含4个CLOB列的表,有的update操作执行时间超过了10秒,形如,
update A set a=:1, b=:2, c=:3 ... where id=:10 and update_time=:11;
通过夜维日志,定位到在应用出现卡顿的时间内,夜维正在执行删除这张A表的操作,SQL中会接受删除日期和一次删除的条数作为参数,分别是90和10000,表示一次删除10000条90天以前的历史数据(一天大约20万),日志记录了一次删除10000条的用时,都在6-10秒内,和前几日的执行时间相比,基本一致,并未出现异常,
delete from A where update_time <= trunc(sysdate) - :1 and rownum <= :2
通过操作系统oswtop监控的信息,发现故障期间,数据库服务器的CPU idle曾降低到0%,正常时间段内,CPU idle通常是80%-90%,所以故障期间,应该是什么操作,极度消耗CPU。
通过数据库AWR,看到resmgr:cpu quantum排在榜首,
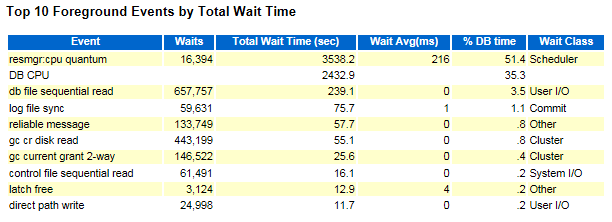
在故障时间段内,看到业务的update和夜维的delete操作等待事件的信息,尤其update操作,等待的就是resmgr:cpu quantum,

这个等待事件,参考了eygle的文章(https://www.eygle.com/archives/2011/07/events_resmgr_cpu_quantum.html),提示这个问题是和资源管理相关的,如果启用资源管理计划,就可能遇到这个问题。如果确认性能受到了资源管理期的影响,常规的解决方案是禁用资源管理,禁用缺省的维护计划(DEFAULT_MAINTENANCE_PLAN Metalink:786346.1)。
经过确认,每天00:00-02:00,启动了缺省的维护窗口,为了保障一些后台任务的执行,update等待resmgr:cpu quantum很可能是因为更新操作消耗了太多的CPU,触发了Oracle对update操作的资源限制,所以应该是正常现象,因此,找到update消耗更多CPU才是问题的关键。
通过SQL AWR,确认update语句的执行计划只有一个,而且用的IND
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3668
3668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









