






sharding-jdbc简介
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等。
理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle,SQLServer,DB2等数据库的计划。
Sharding-JDBC定位为轻量级java框架,使用客户端直连数据库,以jar包形式提供服务,未使用中间层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。SQL解析使用Druid解析器,是目前性能最高的SQL解析器。
具体的介绍可以上它的文档那里看看,简单归纳起来就是,它是一个增强版的JDBC,对使用者透明,逻辑代码什么的都不用动,它来完成分库分表的操作;然后它还支持分布式事务(不完善)。看起来很不错的样子。
下面用个小例子来看一下分库分表的使用。使用的是SpringBoot,mybatis,DBCP连接池。
1.新建一个springboot项目
ArtifactId为sharding-jdbc-manualConfiguration.自己配置好目录结构。
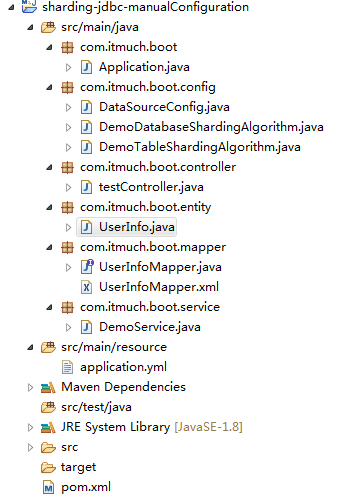
2.pom.xml
4.0.0
com.itmuch.boot
sharding-jdbc-manualConfiguration
0.0.1-SNAPSHOT
jar
sharding-jdbc-manualConfiguration
http://maven.apache.org
org.springframework.boot
spring-boot-starter-parent
1.5.9.RELEASE
UTF-8
UTF-8
1.8
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.1
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
io.shardingjdbc
sharding-jdbc-core
2.0.3
org.springframework.boot
spring-boot-devtools
commons-dbcp
commons-dbcp
mysql
mysql-connector-java
com.alibaba
fastjson
1.2.47
org.springframework.boot
spring-boot-maven-plugin
简单提一下:
这里主要是这个依赖
io.shardingjdbc
sharding-jdbc-core
2.0.3
它是当当网开源的sharding-jdbc,当然这个不重要啦!
顺便说一下:
commons-dbcp
commons-dbcp
我是用的DBCP数据库连接池,这里的druid连接池被我注掉了,当然你也可以使用它,把DBCP注掉。它们都差不多。我想很多其他博友应该有写。大家找找看咯!
在这里我要吐槽下:TMD,CSDN博客上面的文章叫什么东西啊,我读过几次,在上面down下来的代码都是不能运行的,然后在博客园上面再找相同内容的东西,一比对,发现很明显的配置漏洞。我也是无语了。
所以我是推荐咱博客园的文章的,大家都很优秀!!!
application.yml
我们是手动配置数据源,那这里我们可以上面都不用谢了呀!直接放个空文件得了,当然你如果不想使用8080端口,想在这里配置一下当前项目的使用端口号,你可以在这里配置下咯!!!
数据库
我们要准备三个数据库user_0,user_1,user_2,每个数据库里准备两张表user_info_0,user_info_1.一共使用六张一样一样的表。
DROP TABLE IF EXISTS `user_info_0`;CREATE TABLE `user_info_0` (
`user_id` bigint(19) NOT NULL,`user_name` varchar(45) DEFAULT NULL,`account` varchar(45) DEFAULT NULL,`password` varchar(45) DEFAULT NULL,PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- ----------------------------
-- Table structure for user_info_1
-- ----------------------------
DROP TABLE IF EXISTS `user_info_1`;CREATE TABLE `user_info_1` (
`user_id` bigint(19) NOT NULL,`user_name` varchar(45) DEFAULT NULL,`account` varchar(45) DEFAULT NULL,`password` varchar(45) DEFAULT NULL,PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Application.java
@SpringBootApplication
@EnableAutoConfiguration(exclude= { DataSourceAutoConfiguration.class})public classApplication {public static voidmain(String[] args) {
SpringApplication.run(Application.class, args);
}
}
启动类嘛,我们都一样!不不不。。。注意了,多了个注解,看到它要干嘛了吗?它要把自动配置数据源的功能排除掉。
这里你要是看过我前面的文章“为什么用springboot”中的springboot自动配置的原理,这个东西,so easy啦!
testController.java
@RestControllerpublic classtestController {
@Resource
UserInfoMapper userInfoMaper;
@Resource
DemoService demoService;
@GetMapping("insert/{id}")publicString insertData(@PathVariable Long id) {
demoService.demo();return "success";
}
@GetMapping("get/{id}")publicString getData(@PathVariable Long id) {
UserInfo userInfoByUserId=demoService.getUserInfoByUserId(id);
System.out.println("得到的结果为:" +JSON.toJSON(userInfoByUserId));returnJSON.toJSON(userInfoByUserId).toString();
}
}
对外接口,我们提供两个吧,向数据库插入数据传的id没用,我传了玩儿的!!!
插入的内容请看下面的service.
DemoService.java
@Servicepublic classDemoService {
@Resource
UserInfoMapper userInfoMapper;public static Long userId = 100L;public voiddemo() {
System.out.println("Insert--------------");for (int i = 1; i <= 100; i++) {
UserInfo userInfo= newUserInfo();
userInfo.setUserId(userId);
System.out.println(userId);
userInfo.setAccount("Account" +i);
userInfo.setPassword("pass" +i);
userInfo.setUserName("name" +i);
userId++;
userInfoMapper.insert(userInfo);
System.out.println("第" + i + "条");
}
System.out.println("over..........");
}publicUserInfo getUserInfoByUserId(Long id) {returnuserInfoMapper.selectByPrimaryKey(id);
}
}
我们就试验向数据库插100条数据咯,再提供下查询方法。哦哦,Entity在下面
UserInfo.java


1 public classUserInfo {2 privateLong userId;3
4 privateString userName;5
6 privateString account;7
8 privateString password;9
10 publicLong getUserId() {11 returnuserId;12 }13
14 public voidsetUserId(Long userId) {15 this.userId =userId;16 }17
18 publicString getUserName() {19 returnuserName;20 }21
22 public voidsetUserName(String userName) {23 this.userName = userName == null ? null: userName.trim();24 }25
26 publicString getAccount() {27 returnaccount;28 }29
30 public voidsetAccount(String account) {31 this.account = account == null ? null: account.trim();32 }33
34 publicString getPassword() {35 returnpassword;36 }37
38 public voidsetPassword(String password) {39 this.password = password == null ? null: password.trim();40 }41 }
点击展开
UserInfoMapper.java
@Mapperpublic interfaceUserInfoMapper {/*** This method was generated by MyBatis Generator. This method corresponds to
* the database table user_info
*
* @mbg.generated Tue Mar 13 23:47:19 CST 2018*/
intinsert(UserInfo record);/*** This method was generated by MyBatis Generator. This method corresponds to
* the database table user_info
*
* @mbg.generated Tue Mar 13 23:47:19 CST 2018*/
intinsertSelective(UserInfo record);/*** This method was generated by MyBatis Generator. This method corresponds to
* the database table user_info
*
* @mbg.generated Tue Mar 13 23:47:19 CST 2018*/UserInfo selectByPrimaryKey(Long userId);/*** This method was generated by MyBatis Generator. This method corresponds to
* the database table user_info
*
* @mbg.generated Tue Mar 13 23:47:19 CST 2018*/
intupdateByPrimaryKeySelective(UserInfo record);/*** This method was generated by MyBatis Generator. This method corresponds to
* the database table user_info
*
* @mbg.generated Tue Mar 13 23:47:19 CST 2018*/
intupdateByPrimaryKey(UserInfo record);
}
因为是用mybatis的逆向工程自动生成的,东西多余了点。懒得删了。但是注意下,类名上面的@Mapper注解是我加的。
这里我展开说一下,我在网上看到很多人在springboot项目中使用Mybatis作为持久层框架的时候,都不这么用。都是在resource根目录下面建一个文件夹mapper,然后把所有的XXXMapper.xml文件放到里面,XXXMapper.java还是放到com...mapper中不变。然后在启动类上面添加一个针对这个com...mapper文件夹的@ComponentScan(“com...mapper”)注解。还要在根目录resource下面配置mybatis-config.xml文件。更有甚者,居然有人在application.properties文件或application.yml文件中配置mybatis的东西,例如:
mybatis:
mapper-locations: classpath:mybatis/mapper/*.xml
type-aliases-package: com.sun.shard.bean
虽然springboot也能支持这样使用,但是我是不建议也不喜欢这样的风格,因为你想啊,我们为什么要用springboot?不就是想尽量少写点配置嘛,把这些繁琐的东西交给springboot来做就得了!要不然springboot出mybatis-spring-boot-starter这个启动器干啥!
对了,大家想了解为啥,建议大家自己看下源码,你加了mybatis-spring-boot-starter这个依赖,在Maven Dependencies下面找到
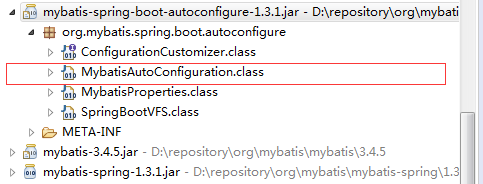
看明白这个类,基本就没啥东西了。
扯远了,我们继续我们的分库分表。
UserInfoMapper.xml
1 <?xml version="1.0" encoding="UTF-8"?>
2
3
4
5
10
11
12
13
14
15
16
21 user_id, user_name, account, password22
23
24
29 select30
31 from user_info32 where user_id = #{userId,jdbcType=BIGINT}33
34
35
40 insert into user_info (user_id, user_name, account,41 password)42 values (#{userId,jdbcType=BIGINT}, #{userName,jdbcType=VARCHAR}, #{account,jdbcType=VARCHAR},43 #{password,jdbcType=VARCHAR})44
45
46
51 insert into user_info52
53
54 user_id,55
56
57 user_name,58
59
60 account,61
62
63 password,64
65
66
67
68 #{userId,jdbcType=BIGINT},69
70
71 #{userName,jdbcType=VARCHAR},72
73
74 #{account,jdbcType=VARCHAR},75
76
77 #{password,jdbcType=VARCHAR},78
79
80
81
82
87 update user_info88
89
90 user_name = #{userName,jdbcType=VARCHAR},91
92
93 account = #{account,jdbcType=VARCHAR},94
95
96 password = #{password,jdbcType=VARCHAR},97
98
99 where user_id = #{userId,jdbcType=BIGINT}100
101
102
107 update user_info108 set user_name = #{userName,jdbcType=VARCHAR},109 account = #{account,jdbcType=VARCHAR},110 password = #{password,jdbcType=VARCHAR}111 where user_id = #{userId,jdbcType=BIGINT}112
113
点击展开
到这里我们一套流程算是下来了。接下来是重点,手动添加数据源配置。
DataSourceConfig.java
1 @Configuration2 @MapperScan(basePackages = "com.itmuch.boot.mapper")3 public classDataSourceConfig {4
5 @Bean(name = "shardingDataSource")6 DataSource getShardingDataSource() throwsSQLException {7 ShardingRuleConfiguration shardingRuleConfig;8 shardingRuleConfig = newShardingRuleConfiguration();9 shardingRuleConfig.getTableRuleConfigs().add(getUserTableRuleConfiguration());10 shardingRuleConfig.getBindingTableGroups().add("user_info");11 shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(12 new StandardShardingStrategyConfiguration("user_id", DemoDatabaseShardingAlgorithm.class.getName()));13 shardingRuleConfig.setDefaultTableShardingStrategyConfig(14 new StandardShardingStrategyConfiguration("user_id", DemoTableShardingAlgorithm.class.getName()));15 return newShardingDataSource(shardingRuleConfig.build(createDataSourceMap()));16 }17
18 @Bean19 TableRuleConfiguration getUserTableRuleConfiguration() {20 TableRuleConfiguration orderTableRuleConfig = newTableRuleConfiguration();21 orderTableRuleConfig.setLogicTable("user_info");22 orderTableRuleConfig.setActualDataNodes("user_${0..2}.user_info_${0..1}");23 orderTableRuleConfig.setKeyGeneratorColumnName("user_id");24 returnorderTableRuleConfig;25 }26
27 private MapcreateDataSourceMap() {28 Map result = new HashMap<>();29 result.put("user_0", createDataSource("user_0"));30 result.put("user_1", createDataSource("user_1"));31 result.put("user_2", createDataSource("user_2"));32 returnresult;33 }34
35 private DataSource createDataSource(finalString dataSourceName) {36 BasicDataSource result = newBasicDataSource();37 result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());38 result.setUrl(String.format("jdbc:mysql://localhost:3306/%s", dataSourceName));39
40 result.setUsername("root");41 result.setPassword("root");42 returnresult;43 }44
45 }
这个数据源配置类大家也看到了,并不复杂,你看啊,我们准备了三个数据库user_0,user_1,user_2;每个数据中准备了两张相同的业务表user_info_0和user_info_1.带着这个信息去看这个类,不用多说。
DemoDatabaseShardingAlgorithm.java
public class DemoDatabaseShardingAlgorithm implements PreciseShardingAlgorithm{
@Overridepublic String doSharding(Collection collection, PreciseShardingValuepreciseShardingValue) {for(String each : collection) {if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 3 + "")) {returneach;
}
}throw newIllegalArgumentException();
}
}
顾名思义,这是分库算法,根据选择的字段(上面DataSourceConfig.java第12行我们选的字段是user_id)对3取余。
DemoTableShardingAlgorithm.java
public class DemoTableShardingAlgorithm implements PreciseShardingAlgorithm{
@Overridepublic String doSharding(Collection collection, PreciseShardingValuepreciseShardingValue) {for(String each : collection) {if (each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) % 2 + "")) {returneach;
}
}throw newIllegalArgumentException();
}
}
顾名思义,这是分表算法,根据选择的字段(上面DataSourceConfig.java第14行我们选的字段也是user_id)对2取余。
测试
代码就这么多,启动application.java类,我们访问localhost:8080/insert/1试试。
然后看数据库:我们之前建的三个库,共六张表,四张表都是17条记录,两张表里面分别有16条,一共100条。根据user_id判断,没有重复的,那基本哦了呀!
代码地址:https://gitee.com/fengyuduke/my_open_resources/blob/master/sharding-jdbc-manualConfiguration.rar














 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









