





GAN系列 - 自注意力生成对抗网络SAGAN(Self-Attention Generative Adversarial Networks )
GAN如何利用注意力来提高图像质量呢,例如注意力如何提高语言翻译和图像字幕的准确性?例如,图像字幕深度网络聚焦在图像的不同区域以生成字幕中的单词(Image Caption)。

下面突出显示的区域是网络聚焦的关注区域,用于生成特定单词。

Motivation
对于使用ImageNet系列结构训练的GAN模型,它们擅长处理有大量纹理(风景,天空)的类型,但在结构类型上表现更差。例如,GAN可以很好地渲染狗的皮毛,但对于狗的腿来说会很糟糕。虽然卷积filters擅长分析空间局部性信息,但是感知区域可能不足以覆盖较大的结构。我们可以增加filter的大小或深度网络的深度,但这将使GAN更难训练。
或许,我们可以应用注意力attention的概念。例如,为了细化眼睛区域的图像质量(左图中的红点),SAGAN仅使用中间图形中的高亮区域上的 feature map区域。如下所示,该区域具有更大的感受视野,并且上下文context更聚焦且更有相关性。右图显示了另一个例子,嘴部区域(绿点)。

Design
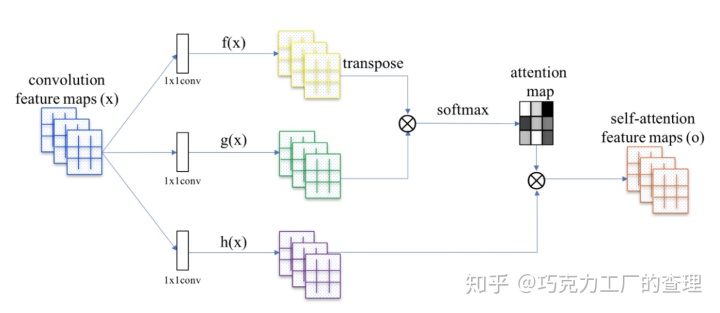
对于每个卷积层,
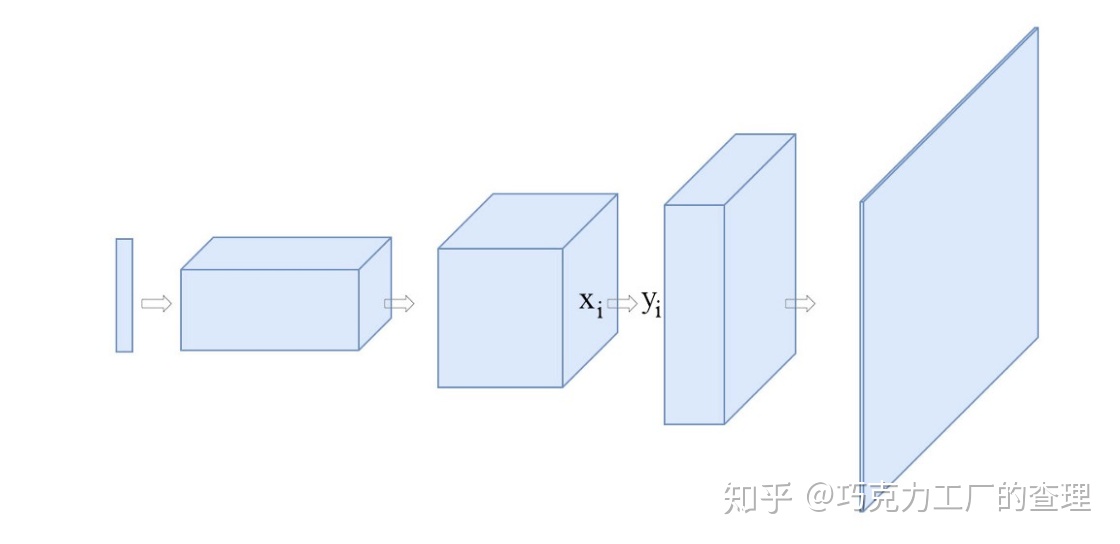
我们通过自注意力机制计算,用一个额外的term Ø 改进每一个空间位置输出。
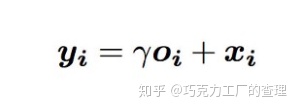
其中x是原始图层输出,y是新输出。
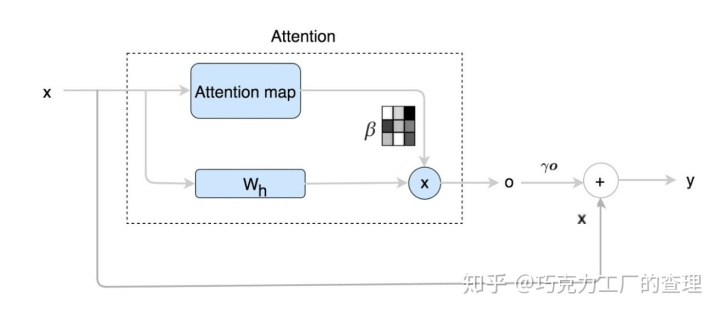
(Note,将自注意力机制应用于每个卷积层。)
自注意力机制的组成部分
- 计算attention map β,同时
- 计算自注意力的输出。
Attention map
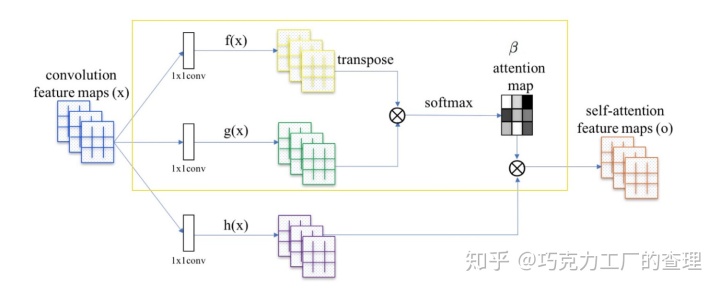
我们用Wf和Wg(这些是要训练的模型参数)乘以x,并使用它们,用以下公式计算attention map β:

对于每个空间位置,创建一个用作mask的attention map。βij被解释为在渲染位置j时位置i的影响。

Attention output
接下来,我们将Wh(也要训练的模型参数)乘以x,并将其与attention map β合并,以生成self-attention feature map 的输出o。

该卷积层的最终输出是:
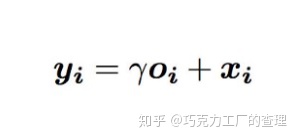
其中γ被初始化为0,因此模型将首先探索局部空间信息,然后用自注意力机制来改进。
Loss function
SAGAN使用hinge loss来训练网络:
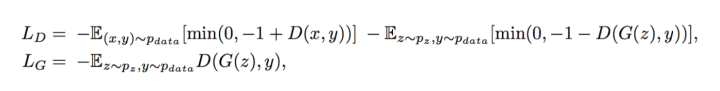
Implementation
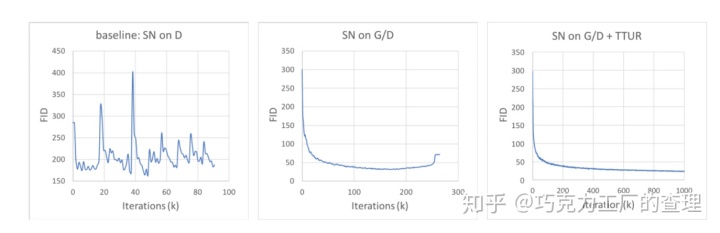
自注意力不仅适用于生成器generator。生成器generator和鉴别器discriminator都使用自注意力机制。为了提升训练,在鉴别器discriminator和生成器generator中分别使用不同的学习率(本文称为TTUR)。此外,谱归一化spectral normalization (SN)用于提高GAN训练的稳定性。这是FID中的性能指标(越低越好)。
引用
自注意力生成对抗网络SAGAN
https://arxiv.org/pdf/1805.08318.pdfarxiv.org














 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









