






虽然现在日志存储和分析系统非常发达(例如ELK等),但我们仍然难以避免直接登录到服务器上通过shell对服务器的日志进行分析。今天,我们就以Nginx的访问日志为例,为大家介绍一下常用的日志分析脚本片段。有了这些脚本片段,稍加修改就可以用在自己的日常工作中。下面是本文作为示例的日志片段截图。

图1. 日志格式截图
如下是其中一条日志文本。
111.206.221.47 - - [14/Oct/2018:20:58:52 +0800] "POST /wp-admin/admin-ajax.php HTTP/1.1" 200 10 "http://www.itworld123.com/2016/09/30/%E4%BD%A0%E6%98%AF%E5%A6%82%E4%BD%95%E5%B0%86%E4%B8%80%E4%B8%AA-html-%E5%85%83%E7%B4%A0%E6%B7%BB%E5%8A%A0%E5%88%B0-dom-%E6%A0%91%E4%B8%AD%E7%9A%84/" "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)"
http状态码及统计
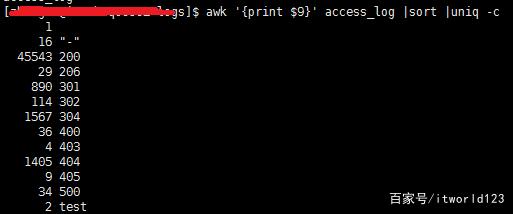
获取日志所有请求的状态码,并统计每个状态码的数量。这里主要用到了3个命令,awk、sort和uniq。其中awk用于从每一行中提取指定的列(本文是第9列,具体看上面日志截图);sort命令实现对awk处理后内容的排序;uniq命令用于删除重复行,而且参数-c在每列旁边显示该行重复出现的次数,因此就出现了某种状态码出现的总次数。
cat access_log |awk '{print $9}' | sort |uniq -c
或者
awk '{print $9}' access_log | sort |uniq -c
截取某段时间的日志
有时候会服务器在某段时间出现了问题,因此需要分析这段时间的日志,通过下面命令就可以截取指定时间段的日志。如下是截取2018年10月21日早7点30分到早7点38分的日志。为了保证本文的简洁性性,本文不在截取结果的截图。
cat access_log |awk '$4 >="[21/Oct/2018:07:30:00" && $4 <="[21/Oct/2018:07:38:00"'
获取访问源IP及访问量
在Web服务高负载情况下,我们经常需要统计一下产生负载的来源,这时候就需要统计一下访问本Web服务的源IP信息。下面命令用于统计某一天的访问源IP及访问量。
cat access_log | grep "21/Oct/2018" | awk '{print $1}' | sort | uniq -c | sort -nr
分析某个IP访问的目标路径及访问量
确定某些特殊的源IP之后,我们需要进一步确认其访问的路径,以便于分析其访问的特性,进一步确认产生问题的根源。下面脚本用于分析某个IP访问的本Web服务的路径信息。
cat access_log | grep "21/Oct/2018" | grep "220.243.136.111" |awk '{print $11}' | sort | uniq -c | sort -nr
上述命令中的grep用于进行特征过滤,上例中用于过滤IP为220.243.136.111的访问。而该命令可以通过选项v进行反向过滤,也就是不包含该特征的内容。例如下面是表示请求中不包含HEAD请求。
cat access_log | grep "21/Oct/2018" | grep "220.243.136.111"| grep -v HEAD |awk '{print $11}' | sort | uniq -c | sort -nr
统计本Web服务的热点文章
有时候我们需要统计本Web服务器中最热的前N条文章(或者URL)。这时可以用如下脚本完成。这里用了一个新的命令head,该命令用于取出所有文本中的前10行。而head前面的命令已经都做过介绍,前面的命令组合用于对Web的访问路径进行统计,并按访问量的多少进行排名。这样,再结合head命令就可以去除访问最热的前10个URL。
cat access_log | grep "21/Oct/2018" | awk '{print $11}' | sort | uniq -c | sort -nr |head -n 10
查看耗时最高的访问
在Web服务器每个请求都有一定的耗时,有时候会出现网站访问速度慢的情况。由于每个网页都由很多文件构成,因此又不清楚到底是加载那个文件导致网站网页加载太慢。这时就需要对每个文件的加载情况进行分析。如下命令用户分析耗时最高的前10个文件。
cat access_log | grep "21/Oct/2018" | awk '{print $10}' | sort -nr |uniq |head -n 10
这些脚本是基本脚本,学会这些脚本后,通过简单的调整和组合就可以实现更为复杂的功能。具体如何熟悉这些内容的使用只能结合实践。后面大家多多练习吧,希望大家能尽快熟悉Shell的使用。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









