






本文知识点:
- 什么是逻辑回归?
- 逻辑回归为什么用 sigmoid 函数?
- 逻辑回归为什么用极大似然函数?
什么是逻辑回归?
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。

所以此时需要这样的形状的模型会比较好

那么怎么得到这样的模型呢?
这个模型需要满足两个条件 大于等于0,小于等于1
大于等于0 的模型可以选择 绝对值,平方值,这里用 指数函数,一定大于0
小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了

再做一下变形,就得到了 logistic regression 模型

通过源数据计算可以得到相应的系数了

最后得到 logistic 的图形
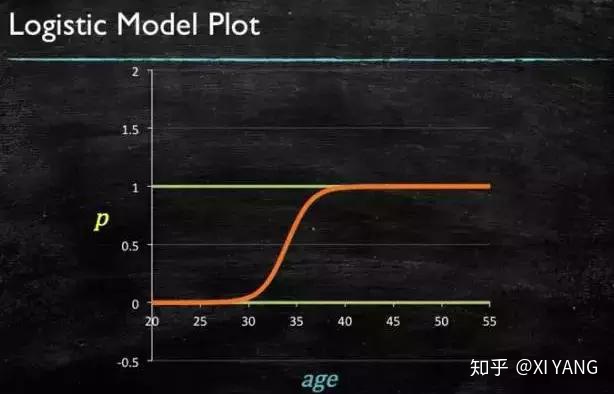
逻辑回归为什么用 sigmoid 函数?
假设我们有一个线性分类器:

我们要求得合适的 W ,使 0-1 loss 的期望值最小,即下面这个期望最小:
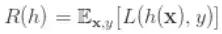
一对 x y 的 0-1 loss 为:
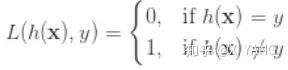
在数据集上的 0-1 loss 期望值为:

由 链式法则 将概率p变换如下:
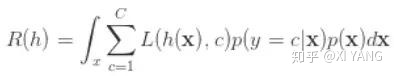
为了最小化 R(h),只需要对每个 x 最小化它的 conditional risk:

由 0-1 loss 的定义,当 h(x)不等于 c 时,loss 为 1,否则为 0,所以上面变为:

又因为
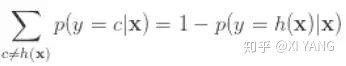
所以:
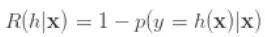
为了使 条件风险 最小,就需要 p 最大,也就是需要 h 为:
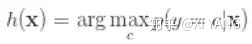
上面的问题等价于 找到 c*,使右面的部分成立:

取 log :
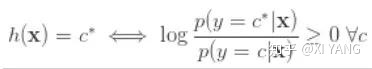
在二分类问题中,上面则为:
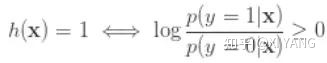
即,我们得到了 log-odds ratio !
接下来就是对 log-odds ratio 进行建模,最简单的就是想到线性模型:
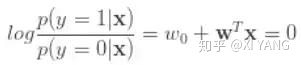
则:
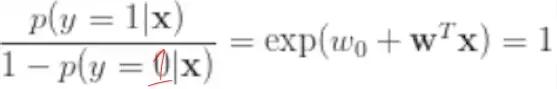
于是得到 sigmoid 函数:
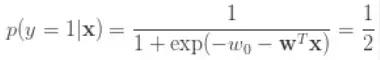
由此可见,log-odds 是个很自然的选择,sigmoid 是对 log-odds 的线性建模。
逻辑回归为什么用极大似然函数?
Logistic regression 用来解决二分类问题,
它假设数据服从伯努利分布,即输出为 正 负 两种情况,概率分别为 p 和 1-p,
目标函数 hθ(x;θ) 是对 p 的模拟,p 是个概率,这里用了 p=sigmoid 函数,
所以 目标函数 为:
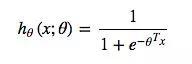
损失函数是由极大似然得到,
记:
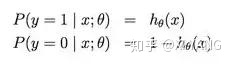
则可统一写成:

写出似然函数:
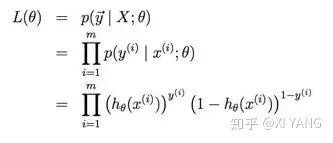
取对数:
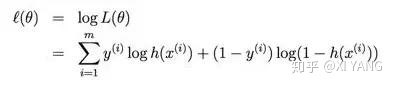
求解参数可以用梯度上升:
先求偏导:
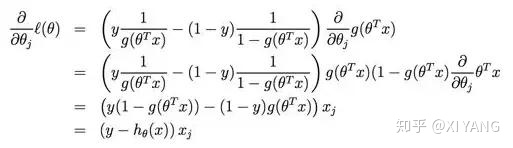
再梯度更新:
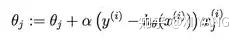
常用的是梯度下降最小化负的似然函数。
那么为什么逻辑回归要使用极大似然函数呢?
- 因为我们想要让 每一个 样本的预测都要得到最大的概率,即将所有的样本预测后的概率进行相乘都最大,也就是极大似然函数.
- 对极大似然函数取对数以后相当于对数损失函数,由上面 梯度更新 的公式可以看出,对数损失函数的训练求解参数的速度是比较快的,而且更新速度只和x,y有关,比较的稳定。
- 为什么不用平方损失函数呢,如果使用平方损失函数,梯度更新的速度会和 sigmod 函数的梯度相关,sigmod 函数在定义域内的梯度都不大于0.25,导致训练速度会非常慢。而且平方损失会导致损失函数是 theta 的非凸函数,不利于求解,因为非凸函数存在很多局部最优解。















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









