





一、概述
最近计划从数据库开始,将整个数据处理流程进行升级迭代,包括数据库、Python平台、Excel插件以及web管理和呈现界面。

因为仅对整个部门的20多人服务,MySQL性能已经足够,也不需要做主从库的设计,相对来讲整个流程搭建起来还是比较简单的。我是在职能部门做数据分析,所以也只是为部门同事和领导服务,如果是做面向用户的那种数据库应该会复杂很多,数据量也不在一个层级,肯定不能像我这样做。
为什么要重构整个数据处理流程?
目前的数据库是同事搭建的MySQL数据库,一开始只是做临时处理,结果数据量越来越大。数据库的功能也从临时库转变为数仓性质。由于一直没有改进的契机,数据库也一直延续着这种基本上没有架构和规范的情况。
上个月刚好重构了我自己负责的一个数据库,主要是把命名、字段和主键之类的优化了一下,对于数据表的整理也比较头大。恰好前两天刷知乎看到了介绍数仓的标准架构,即ODS、DWD、DWS、ADS四层数据架构,瞬间感觉这就是我想要的,于是查找相关资料考虑对数仓结构进行优化。考虑到目前在Excel插件中用C#处理数据的痛苦开发过程,前段时间也正好测试了Flask框架,索性不如直接搞个Python“中台”来处理数据,剥离插件的数据加工过程。
目前数据处理流程存在的问题

目前数据的来源是Python从BR系统导入、从其他系统导出为Excel文件再导入数据库。数据的处理也是Python、MySQL和Excel都有,数据的呈现主要是用的VBA取数到Excel。
MySQL数据库没有开启日志记录,当然即使开启了也没什么意义,对数据库的操作比较乱。整个数据库表的结构比较杂乱,表设计也不是很规范。由于部分表行数达到几千万行,超出了MySQL的单表处理能力,导致这些表运行也比较缓慢。
二、数仓
数据库是数据的起点和终点,所以整个数据处理流程的建设应该是从数据库开始,因为我自己负责的一个小数据库字段相对规范,使用到的程序比较熟悉,改起来也方便。所以整个数据库的修改先拿自己的数据库开刀,然后采用新库和旧库并行的方式逐步对其他数据库和数据表进行迁移。
1. 数仓架构
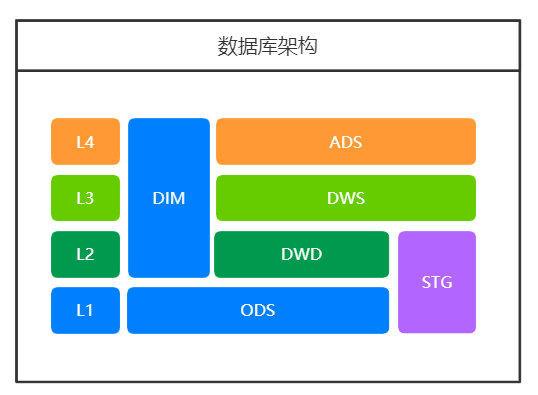
网上有很多资料介绍标准的四层数仓架构,但是在具体应用中肯定不能生搬硬套。除了标准的四层和维度层,增加STG层是因为有一些我们从系统中获取到的数据,是可以不用清洗直接使用的标准化数据。这种数据放在ODS层和DWD层都不太合适。
2. 数仓规范
关于数仓的详细规划后面会单写一个文档,这里简单说一下开发规范。关于MYSQL数据库的开发规范可以参考官方文档https://dev.mysql.com,如果使用的不是MySQL也可以去参考相应的文档。
数据库除了字段名要规范,字段类型、长度和主键的设置都是要重点考虑的。这些对数据库的速度也会有很大的影响。
在数据量较大时要考虑分库分表,这个没有具体的标准。网上看的说阿里巴巴的java开发手册写的行数超过500万或者大小超过2g就需要进行分库分表,我认为可以参考。目前我们有两三张表需要进行分表,后面也会按照一定规则去拆分。
三、Python中台
使用Flask写一个中台,也做网站的后端,刚开始可以直接用jinjia2+layui做前端。后期有时间可以剥离前端页面,前端用react/vue+bootstarp写,Flask只写后端程序,封装成API供前端调用。
之所以选择做这个,是因为上个月自己也尝试了做flask,当时已经实现了标准的页面布局,也用echarts做了一些图,后面应该只用搞定部署就没问题了。
整体结构
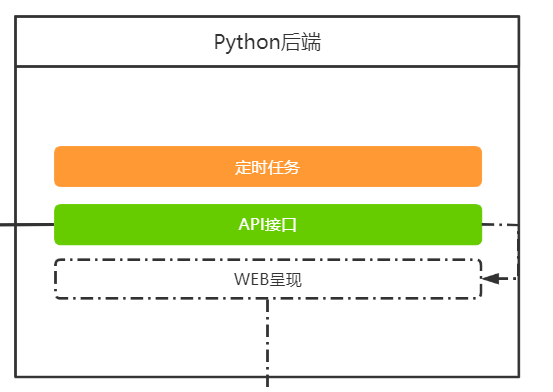
因为有一些数据是用Python爬取的,需要定时处理,所以需要做个定时任务部分。程序还比较多,每天/每周/每月都有。
除了web前端部分,还有Excel需要API接口。因为数据需要做一些简单处理才能最终呈现,所以也通过Python来做,VSTO插件从Python后端获取json数据,再写入表格。在Python中也对操作进行记录。
四、web前端

一开始做web是为了数据可视化呈现的。公司也购买了帆软,但是BI软件再强大也没有直接撸web自由。既然都已经用Python了想着索性直接全部自己实现,echarts还是很香的。
后续就发掘了更多的可能性,比如跟同事沟通发现可以自己写一套打标签的web系统,当然这个工程量比较大,应该在后期再实现。一些工程量比较小的项目也比较有意义,比如对整个数据体系以及Excel插件的实时监控,可以及时发现Bug并修正。
也可以对Python运算过程进行控制,有一些比较固化的程序,不定期执行的,可以放到WEB中操作,不用每次打开IDE执行。
五、Excel插件

这个属于传统项目了,目前有两个插件,一个是VBA做的,有一些自定义公式和快捷工具。还有一个是VSTO插件,做数据的填报上传和历史数据查询。除此之外还有一些分散的带宏Excel做一些个性化的数据处理,这部分后面打算拆分到插件中去。
插件其实是我们整个数据处理过程中非常重要的一部分。除了高频使用的自定义公式之外,还有一个原因是即使是从web导出的数据后续也需要用Excel来做简单处理,所以直接在Excel中打开可以跳过“下载—打开”这一步。
当然Excel插件的权限控制也是必要的。
六、总结
整个流程中涉及到的知识点基本都已经上手做过,也有很多细节需要在后续的项目进展中不断学习。比如flask项目如何部署到windows服务器,以及VSTO自定义公式和插件如何打包成一个程序。
这个优化过程预计会耗费大量的时间,因为目前使用数据库的程序还比较多,改别人的代码可能需要花时间去理解。我给自己的期限是预计明年6月份之前搞定大部分程序,做出成果。
专栏同样在语雀知识库同步,知识库链接:
数据系统优化之路 · 语雀www.yuque.com
VBA的专栏也会继续更的,这个专栏相当于是对工作内容的总结。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









