






拜托,别再问我桶排序了!!!
桶排序(Bucket sort)或所谓的箱排序,是一个排序算法。
桶排序(Bucket sort),工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量.
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中.
主要思路
- 设置固定的空桶数目
- 将原始数组数据放到对应的空桶Bucket x中
- 将每个不为空的桶采用稳定排序算法进行排序
- 拼接不为空的桶中的数据,就可以得到最终的结果了
关键步骤
- 扫描待排序数据A[N],对于元素A[i],放入对应的桶X
- A[i]放入桶X,如果桶X已经有了若干元素,可以使用插入排序,将arr[i]放到桶内合适的位置
详细步骤
- 设置一个定量桶的个数BucketNum,并使用这个数初始化一个数组,元素的类型可以是链表或者数组。
- 计算出待排序数组的最大值Max和最小值Min
- 使用最大值减去最小数除以桶的个数并向上求整,得到划分区间的divider(即(Max-Min+1)/BucketNum)
- 遍历待排序数组,取每个元素除以divider并向下取整,放入对应的桶里面
- 遍历桶数组,对每个桶进行排序,这里排序算法不限,可以采用计数排序,快排,插入都可以。
- 最终顺序合并每个桶数组,便得到整体有序的数组。
过程描述
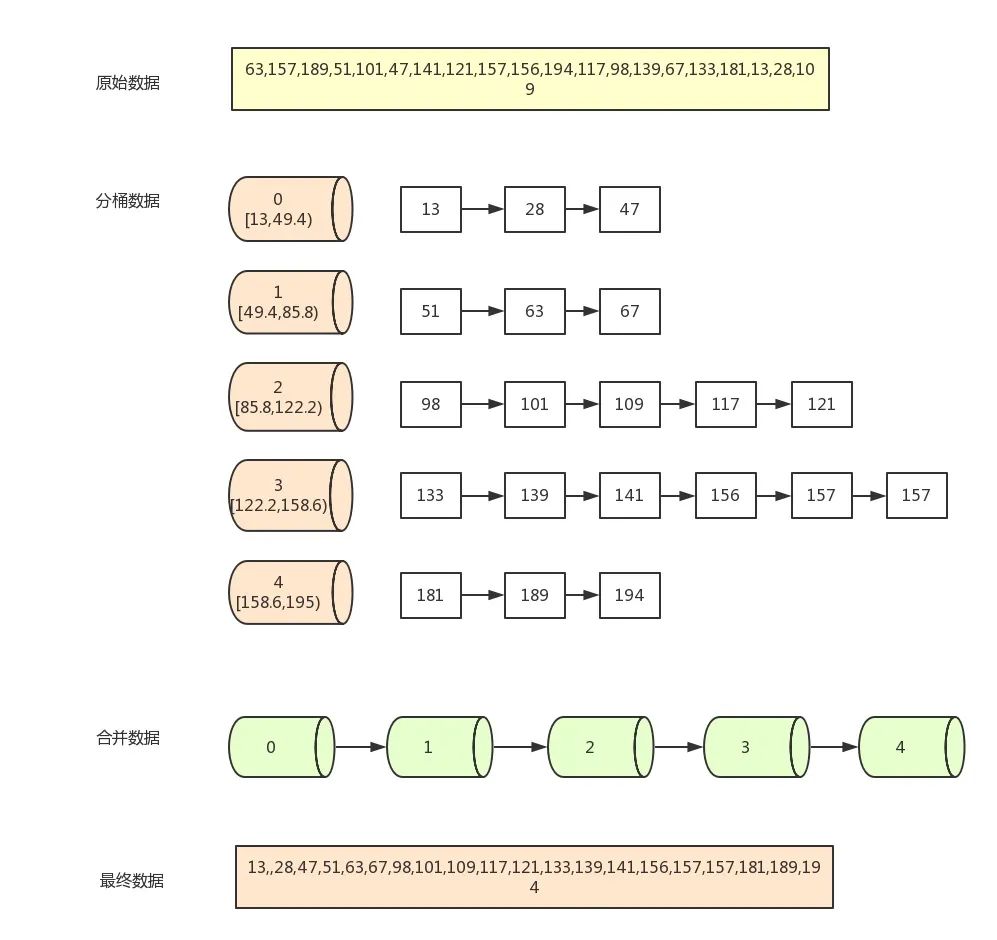
假设一组数据(20长度)为:
[63,157,189,51,101,47,141,121,157,156,194,117,98,139,67,133,181,13,28,109]
现在需要按5个分桶,进行桶排序,实现步骤如下:
- 找到数组中的最大值194和最小值13,然后根据桶数为5,计算出每个桶中的数据范围为(194-13+1)/5=36.4
- 遍历原始数据,(以第一个数据63为例)先找到该数据对应的桶序列Math.floor(63 - 13) / 36.4) =1,然后将该数据放入序列为1的桶中(从0开始算)
- 当向同一个序列的桶中第二次插入数据时,判断桶中已存在的数字与新插入的数字的大小,按从左到右,从小打大的顺序插入。如第一个桶已经有了63,再插入51,67后,桶中的排序为(51,63,67) 一般通过链表来存放桶中数据,当然也可以使用数组
- 全部数据装桶完毕后,按序列,从小到大合并所有非空的桶(如0,1,2,3,4桶)
- 合并完之后就是已经排完序的数据
实现
伪代码
bucketSort(array[]){
for i =1 to len(array){
将array[i]放入对应的桶B[X];
}
for i= 1 to len(Bucket){
采用某种排序算法,对该桶内元素进行排序
}
将B[X]中的所有元素,按顺序合并,排序完毕;
}
代码实现
我的github项目地址
- 桶采用数组的实现方式
下面是我的实现代码:
package sort
import (
"fmt"
"math"
)
// 遍历一次获取一个数组中的最大值和最小值
func getMaxAndMin(array []int) (max int, min int) {
max = array[0]
min = array[0]
for _, v := range array {
if v > max {
max = v
}
if v min = v
}
}
return
}
// 采用数组实现
func BucketSort(array []int) {
arrayLen := len(array)
if arrayLen 1 {
return
}
// 设置桶数量
bucketNum := 5
bucketArray := make([][]int, bucketNum)
//获取数组的最大值和最小值
max, min := getMaxAndMin(array)
if max == min {
return
}
// 计算出每个桶的值区间大小,记得+1
bucketSpace := float64(max-min+1) / float64(bucketNum)
// 遍历原始数组,按范围把数组元素一次放入对应的桶中
for _, v := range array {
// 向下取整
bucketId := int(math.Floor((float64)(v-min) / float64(bucketSpace)))
bucketArray[bucketId] = append(bucketArray[bucketId], v)
}
//对每个桶采用排序算法进行排序,并且合并
var sortArray = make([]int, 0)
for index, bucket := range bucketArray {
// 这里我们采用插入排序算法
InsertSort(bucket)
sortArray = append(sortArray, bucket...)
}
//替换原数组
copy(array, sortArray)
return
}
- 桶采用链表的实现方式
下面是我实现的代码:
package sort
import (
"fmt"
"math"
)
// 遍历一次获取一个数组中的最大值和最小值
func getMaxAndMin(array []int) (max int, min int) {
max = array[0]
min = array[0]
for _, v := range array {
if v > max {
max = v
}
if v min = v
}
}
return
}
// 桶采用链表实现
func BucketSort1(array []int) {
arrayLen := len(array)
if arrayLen 1 {
return
}
// 设置桶数量,并且初始化每个桶
bucketNum := 5
bucketArray := make([]*LinkNode, bucketNum)
for i := 0; i bucketArray[i] = &LinkNode{} //初始化头指针
}
//获取数组的最大值和最小值
max, min := getMaxAndMin(array)
if max == min {
return
}
// 计算出每个桶的值区间大小,记得+1
bucketSpace := float64(max-min+1) / float64(bucketNum)
// 遍历原始数组,按范围把数组元素一次放入对应的桶中
for _, v := range array {
// 向下取整
bucketId := int(math.Floor((float64)(v-min) / float64(bucketSpace)))
linkHead := bucketArray[bucketId] //取出链表头指针
curNode := linkHead.Next
curNodePreNode := linkHead
if linkHead.Next == nil {
linkHead.Next = &LinkNode{Data: v}
continue
}
//遍历进行比较并插入
var find = false
for curNode != nil {
if v >= curNode.Data {
curNodePreNode = curNode
curNode = curNode.Next
continue
}
newNode := &LinkNode{Data: v}
curNodePreNode.Next = newNode
newNode.Next = curNode
find = true
break
}
if !find {
curNodePreNode.Next = &LinkNode{Data: v}
}
}
//合并桶
var sortArray = make([]int, 0)
for _, bucketLink := range bucketArray {
var tmp []int
// 遍历链表
curNode := bucketLink.Next
for curNode != nil {
tmp = append(tmp, curNode.Data)
curNode = curNode.Next
}
//fmt.Printf("bucketId:%v | array is:%v\n", bucketId, tmp)
sortArray = append(sortArray, tmp...)
}
copy(array, sortArray)
return
}
测试案例
我们采用过程描述中的数组序列,可以看到经过合并前,每个桶里面的数据如下示(采用数组和链表结果是一致的):

桶排序的使用场景
桶排序的适用场景非常明了,那就是在数据分布相对比较均匀或者数据跨度范围并不是很大时,排序的速度还是相当快且简单的。
但是当数据跨度过大时,这个空间消耗就会很大;如果数值的范围特别大,那么对空间消耗的代价肯定也是不切实际的,所以这个算法还有一定的局限性。同样,由于时间复杂度为 O(n+m),如果 m 比 n 大太多,则从时间上来说,性能也并不是很好。
但是实际上在使用桶排序的过程中,我们会使用类似散列表的方式去实现,这时的空间利用率会高很多,同时时间复杂度会有一定的提升,但是效率还不错。
我们在开发过程中,除了对一些要求特别高并且数据分布较为均匀的情况使用桶排序,还是很少使用桶排序的,所以即使桶排序很简单、很快,我们也很少使用它。
桶排序更多地被用于一些特定的环境,比如数据范围较为局限或者有一些特定的要求,比如需要通过哈希映射快速获取某些值、需要统计每个数的数量。但是这一切都需要确认数据的范围,如果范围太大,就需要巧妙地解决这个问题或者使用其他算法了。
复杂度
时间复杂度
空间复杂度为O(n)
空间复杂度
桶排序中,需要创建M个桶的额外空间,以及N个元素的额外空间。所以桶排序的空间复杂度为 O(N+M)
稳定性
桶排序中,假如升序排列,a已经在桶中,b插进来是永远都会a右边的(因为一般是从右到左,如果不小于当前元素,则插入改元素的右侧),所以桶排序是稳定的。
PS: 当然了,如果采用元素插入后再分别进行桶内排序,并且桶内排序算法采用快速排序,那么就不是稳定的
总结
通过上面的学习,我们发现桶排序时间复杂度为线性,那么是不是就能替代例如快排、归并这种时间复杂度为O(nlogn)的排序算法呢?
答案是否定的,桶排序的应用场景十分严苛,首先,数据应该分布比较均匀。讲一种较坏的情况,如果数据全部都被分到一个桶里,那么桶排序的时间复杂度是不是就退化到O(nlogn)了呢?其次,要排序的数据应该很容易分成m个桶,每个桶也应该有大小顺序。
总体来说,在适合的场景使用恰当的排序算法,才能够发挥最大作用。
参阅
排序算法之桶排序的深入理解以及性能分析















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









