







 本文探讨了精神疾病检测中自然语言处理(NLP)的主要趋势,包括使用机器学习和深度学习方法。传统机器学习模型如SVM和深度学习模型如CNN、RNN、Transformer被用于文本分析。数据集来源包括社交媒体、电子病例等,特征包括语言模式、统计信息和情感特征。主要挑战涉及数据质量和数量、模型性能和不稳定性、以及可解释性和伦理问题。
本文探讨了精神疾病检测中自然语言处理(NLP)的主要趋势,包括使用机器学习和深度学习方法。传统机器学习模型如SVM和深度学习模型如CNN、RNN、Transformer被用于文本分析。数据集来源包括社交媒体、电子病例等,特征包括语言模式、统计信息和情感特征。主要挑战涉及数据质量和数量、模型性能和不稳定性、以及可解释性和伦理问题。
引言:
本文研究内容:
精神疾病检测的主要NLP趋势和方法是什么?
在传统的基于机器学习的模型中,哪些特征被用于心理健康检测?
哪些神经结构通常用于检测精神疾病?
精神疾病NLP的主要挑战和未来方向是什么?
数据:
1.社交网络内容
Yates等人建立了一个名为“Reddit Self-reported depression Diagnosis”(RSDD)24的抑郁症数据集,其中包含约9k名抑郁症用户和10万名对照用户。同样,CLEF风险2019共享任务25也提出了一个基于Reddit平台的厌食症和自残检测任务。
2.电子病例
3.访谈转录
主要数据集包括DAIC-WoZ抑郁症数据库35(包含142名参与者的转录)、avid -语料库36(包含48名参与者)和精神分裂症识别语料库37(来自109名参与者)。
4.问卷调查
5.个人叙述
方法:
1.机器学习
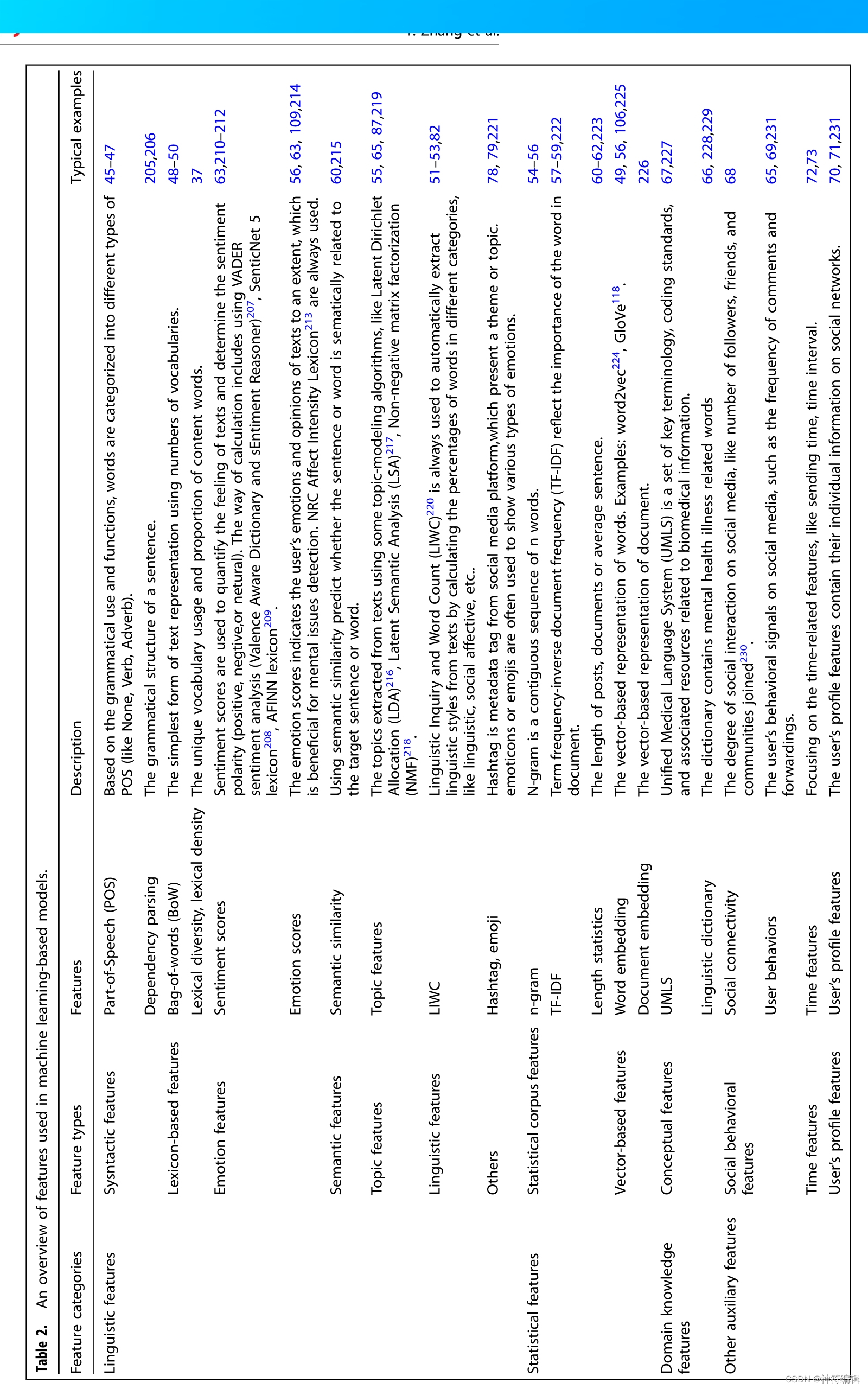
传统的机器学习方法如支持向量机(SVM)、自适应增强(AdaBoost)、决策树等已被用于NLP下游任务。为了训练一个好的ML模型,选择主要的贡献特征是很重要的,这也有助于我们找到疾病的关键预测因子。图1显示了机器学习中常用特性的概述。我们进一步将这些特征分为语言特征、统计特征、领域知识特征和其他辅助特征。最常用的特征主要是基于基本的语言模式(词性(POS) 45-47,词袋(BoW) 48-50,语言查询和词计数(LIWC) 51-53)和统计(n-gram54-56,词频-逆文档频率(TF-IDF) 57-59,句子或段落长度60 - 62),因为这些特征可以很容易地通过文本处理工具获得,并广泛应用于许多NLP任务。此外,情感和话题特征已被实证证明对精神疾病的检测是有效的63 - 65。特定领域的本体、字典和社交网络中的社会属性也有提高准确性的潜力[65 - 68]。对社交媒体数据进行的研究通常利用其他辅助特征来辅助检测,例如社会行为特征(65,69)、用户个人资料(70,71)或时间特征(72,73)。机器学习模型是基于各种提取特征的组合而设计的。大多数基于机器学习方法的论文使用监督学习,其中他们描述了一种或多种用于检测精神疾病的方法:SVM26, 74-77, Adaptive Boosting(AdaBoost)71,78 - 80, k-近邻(KNN)38,81 - 83,决策树(Decision Tree) 84 - 87,随机森林(Random forest) 75,88 - 90, Logistic模型树(LMT)47,47,91,92,朴素贝叶斯(NB)64,86,93,94, Logistic回归(Logistic regression) 37,95 - 97, XGBoost38,55,98,99,以及一些结合多种方法的集成模型[75,100 - 102]。这种监督式学习的优势在于模型能够从标记数据中学习模式,从而确保更好的性能。然而,在高质量水平上标记大量数据既耗时又具有挑战性,尽管有一些方法可以帮助减少人工注释负担103。因此,我们需要使用其他不依赖于标记数据或只需要少量数据的方法来训练分类器。
从未标记数据中发现模式的无监督学习方法,例如聚类数据55,104,105,或使用LDA主题模型27。然而,在大多数情况下,我们可以应用这些无监督模型来提取用于开发监督学习分类器的附加特征56,85,106,107。在所有论文中,很少有论文108,109使用了半监督学习(从大量未标记数据中训练的模型作为附加信息),包括统计模型ssToT(半监督主题随时间建模)108和经典的半监督算法(YATSI110和LLGC111)。
2.深度学习
根据不同分类层结构的结构,我们将基于深度学习的方法分为以下几类:基于卷积神经网络(CNN)的方法(17%),基于递归神经网络(RNN)的方法(36%),基于Transformer的方法(17%)和结合多个不同结构的神经网络的混合方法(30%),如图2所示。

a.CNN-based方法
标准的CNN结构由卷积层和池化层组成,然后是全连接层。一些研究(122 - 127)利用标准CNN构建分类模型,并结合LIWC、TF-IDF、BOW和POS等其他特征。为了捕获情感信息,Rao等人提出了基于CNN128的分层MGL-CNN模型。Lin等人设计了一个结合图模型的CNN框架来利用tweet内容和社交互动信息129。
b.RNN-based方法
rnn的架构允许将之前的输出用作输入,这在使用诸如文本之类的顺序数据时是有益的。一般来说,长短期记忆(LSTM)130和门控循环(GRU)131网络模型可以有效地解决传统RNN的梯度消失问题132。有许多基于LSTM或GRU的研究(例如,133,134),其中一些研究(135,136)利用了LSTM和GRU。注意机制从文本中发现重要的单词信息。一些人还使用基于LSTM或GRU结构的分层注意网络来更好地利用不同层次的语义信息138,139。
此外,还介绍了许多其他深度学习策略,包括迁移学习、多任务学习、强化学习和多实例学习(MIL)。Rutowski等人利用迁移学习在开放数据集上预训练模型,结果表明了预训练的有效性。Ghosh等人开发了一种深度多任务方法142,将情绪识别建模为主要任务,将抑郁检测建模为次要任务。实验结果表明,多任务框架可以提高联合学习时所有任务的性能。在抑郁检测中也使用了强化学习(143,144),通过选择指标柱,使模型更加关注有用的信息,而不是嘈杂的数据。MIL是一种机器学习范式,旨在从训练集的袋标签中学习特征,而不是从单个标签中学习特征。Wongkoblap等人使用MIL来预测抑郁任务的用户145,146。
c.transformer-based方法
变压器体系结构147能够使用注意和递归来解决长期依赖关系。Wang等人提出了C-AttentionNetwork148采用变压器编码器块,具有多头自注意和卷积处理。Zhang等人也提出了带有多头自我注意的TransformerRNN[149]。此外,许多研究人员利用基于变压器的预训练语言表示模型,包括bert150、151、DistilBERT152、Roberta153、ALBERT150、BioClinical BERT用于临床记录31、XLNET154和GPT模型155。这些基于bert的模型的使用和发展证明了大规模预训练模型在精神疾病检测应用中的潜在价值。
d.混合型方法。
一些结合多个神经网络的方法已被用于精神疾病的检测。例如,CNN和LSTM模型的混合框架156-160能够同时获得局部特征和长依赖特征,其性能优于单独使用的CNN或LSTM分类器。Sawhney等人提出了STATENet161,这是一个时间感知模型,它包含一个单独的tweet转换器和一个基于plutchik的emotion162转换器,共同学习语言和情感模式。受到使用子情感表示的性能提升[163]的启发,Aragon等人提出了一种由子情感嵌入、CNN、GRU以及注意机制组成的深度情感注意模型[164],Lara等人也提出了deep Bag of sub-emotions (DeepBose)模型[165]。此外,Sawhney等人引入了PHASE模型166,该模型通过一种新的时间敏感情感LSTM和双曲图卷积网络(Hyperbolic Graph Convolution networks)来学习用户的时间情感进展167。它还通过使用BERT对情绪和异质社交网络图进行微调来学习用户的时间情感谱。
评价指标:
评估指标用于比较不同模型在精神疾病检测任务中的表现。有些任务可以看作是一个分类问题,因此最广泛使用的标准评价指标是准确率(AC)、精度(P)、召回率(R)和F1分数(F1) 149,168-170。同样,ROC曲线下面积(AUC-ROC)60,171,172也被用作分类指标,可以衡量真阳性率和假阳性率。在一些研究中,它们不仅可以检测出精神疾病,还可以对其严重程度进行评分——122,139,155,173。因此,有时需要平均误差指标(例如,平均绝对误差,均方误差,均方根误差)173和其他新指标(例如,分级精度,分级召回率,平均命中率,平均接近率,总体抑郁水平之间的平均差异)139,174来指示数据集中预测严重程度与实际严重程度之间的差异。同时,考虑到精神疾病检测的及时性,其中早期发现对早期预防具有重要意义,提出了一个称为早期风险检测误差的误差度量标准175来衡量决策的延迟。
讨论:
数据量和质量:本综述中涉及的大多数方法使用监督学习模型。这些方法的成功归功于可用的训练数据集的数量。这些训练数据集通常需要人工注释,这通常是一个耗时且昂贵的过程。然而,在精神疾病检测任务中,没有足够的标注公共数据集。为了训练可靠的模型,数据集的质量是很重要的。一些数据集有注释偏差,因为注释者不能确认与疾病相关的明确行为已经发生(例如,如果实际发生自杀),并且只能在预定义的注释规则的约束下对它们进行标记。此外,一些不平衡的数据集有许多负面实例(没有精神障碍的个体),这不利于训练全面和稳健的模型。因此,探索如何使用少量标记的训练数据或不使用训练数据来训练检测模型是很重要的。半监督学习176将少量标记数据和大量未标记数据合并到训练过程中,可用于促进注释177或在标记数据稀缺时提高分类性能。此外,非监督方法也可以应用于精神障碍的检测。例如,无监督主题建模(178)增加了结果的可解释性,并有助于提取潜在特征以开发进一步的监督模型(178)。
性能和不稳定性:有一些模型不稳定的原因,包括类不平衡、有噪声的标签、极长或极短的文本样本文本。由于不同的写作风格和语义异构性,在不同数据源的数据集上进行训练时,性能不稳定。因此,一些检测模型的性能并不好。随着深度学习技术的进步,各种学习技术的出现加速了NLP的研究,如对抗训练181、对比学习182、联合学习183、强化学习184和迁移学习185,这些技术也可以用于精神疾病检测任务。例如,预训练的基于transformer的模型可以转移到Spanish186中的厌食症检测中,并且可以使用强化网络来找到最能反映精神状态的句子。其他新兴技术,如注意力机制(attention mechanism) 187、知识图(knowledge graph) 188和常识推理(commonsense reasoning) 189,也可以用于文本特征提取。此外,特征丰富和数据增强对于获得可比较的结果是有用的。例如,许多研究使用多模态数据资源,如image191-193和audio194-196,其性能优于单模态基于文本的模型。
可解释性:心理健康表征学习的目标是了解心理疾病的原因或解释因素,以提高检测性能和授权决策。对一个成功模型的评估不仅依赖于性能,还依赖于其可解释性(197),这对于指导临床医生不仅理解从文本中提取的内容,而且理解某些预测背后的推理具有重要意义(198 - 200)。基于深度学习的方法利用特征提取和复杂的神经网络结构进行疾病检测,取得了良好的效果。然而,它们仍然被视为黑盒子,无法解释预测结果。因此,在未来的工作中,深度学习模型的可解释性将成为一个重要的研究方向
伦理考虑:在使用与心理健康有关的文本数据时,讨论伦理问题更为重要,因为个人数据的隐私和安全非常重要,而健康数据特别敏感。在研究过程中,研究者应遵循类似于Bentan et al.引入的指导原则202的严格协议,以确保数据在医疗保健研究中得到正确的应用,同时保护隐私,避免进一步的心理困扰。此外,当使用一些公开可用的数据时,研究人员需要获得机构审查委员会和人类研究伦理委员会的伦理批准203,204


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









