







1. 分区数越多越好吗?吞吐量会越高吗
在一定条件下,分区数量和吞吐量成正比,分区数和性能也是成正比的。
为什么说查过一定限度,就会对性能造成影响呢,原因如下:
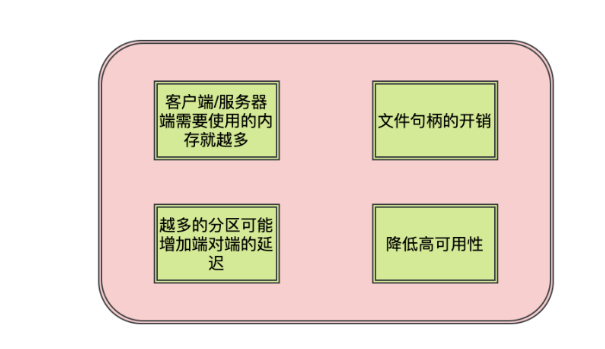
- 客户端/服务端的需要使用更多的内存
- 服务端在很多组件中都维护了分区级别的缓存,分区数越大缓存成本越大。
- 消费端的消费线程数和分区数挂钩的,分区数越大,消费线程越多,线程开销越大
- 生产者发送消息有缓存的概念,会为每个分区缓存消息,当积累到一定程度或者时间时会将消息发送到分区,分区越多,缓存越大
- 文件句柄的开销
每个partition都会对应磁盘文件系统的一个目录,在kafka的数据日志文件目录中,每个日志数据都会分配两个文件,一个索引文件,一个数据文件。每个broker会为每个日志段文件打开一个index文件句柄和一个数据文件句柄。因此随着partiton增多,句柄需求也更多,可能超过linux配置的句柄数量限制
3.越多的分区可能增加端到端的延迟
kafka会将分区HW之前的消息暴露给消费者。分区越多则副本之间的同步数量越多,默认情况下,每个broker从其他broker节点进行数据副本复制时,该broker节点只会为此分配一个线程,该线程需要弯沉该broker所有partition数据的复制,增加耗时
4.降低可用性
分区越多,恢复时间越长,可用性变差
2. 如何增强消费者的消费能力
1. 可以增加topic的分区数,并同时提升消费组的消费者数量,消费者数=分区数
2. 如果是消费者消费不及时,可以采用多线程进行消费,且优化业务方法流程
3. 消费者与topic的分区分配策略有哪些
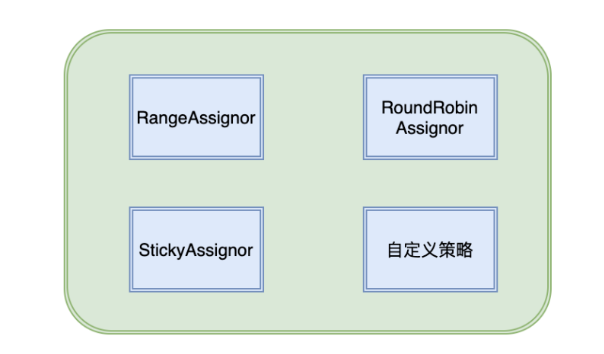
RangeAssignor分配策略
该分配策略是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后分区按照跨度来进行平均分配,尽可能保证分区均匀的分配给所有消费者
对于每个topic会将消费者按照名称的字典顺序拍寻,按序分配,因此靠前的可能多分配一个分区
RoundRobinAssignor 分配策略
该分配策略是按消费者组内的消费者及消费者订阅的所有主题的分区按照字典排序,然后轮询分配给每个消费者
StickyAssignor分配策略
这种分配策略有两个目的
- 分区的分配尽可能均匀
- 分区的分配尽可能与上次的分配相同
自定义分区分配策略
通过实现org.apache.kafka.clients.consumer.internals.PartitionAssignor接口
4. kafka控制器是什么,有什么作用
在kafka集群中会有一个或多个broker,其中有一个会被选举为控制器,它负责管理整个集群中所有分区和副本的状态,kafka集群中只能有一个控制器
- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本
- 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息
- 当某个topic增加分区数量时,由控制器负责分区的重新分配
5. kafka控制器时怎么选举的
kafka中的控制器选举工作依赖于Zookeeper,成功竞选成为控制器的broker会在Zookeeper中创建controller临时节点
每个broker启动时会取尝试读取controller节点的brokerid值,如果读取到的brokerid 不为-1,表示已经有其他broker竞选成功。
如果controller节点不存在,或者节点数据异常。那么就会尝试创建controller节点,创建成功的broker就会成为控制器
6. kafka为什么这么快
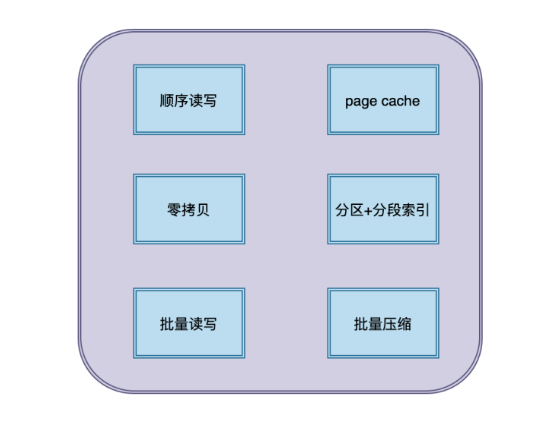
- 顺序读写
磁盘分为顺序读写与随机读写,随机读写慢,顺序读写性能高
2. Page Cache
为了优化读写性能,kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存,而不是jvm空间内存
3. 零拷贝
kafka使用了零拷贝技术,也就是直接将数据从内核空间的读缓冲区直接拷贝到内核空间的socker缓冲区,然后再写入到NIC缓冲区,避免了在内核空间和用户空间之间穿梭
4. 分区分段+索引
kafka的message是按topic分类存储的,topic中的数据又是按照一个个partition即分区存储到不同broker节点,每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的
通过这种分区分段的设计,kafka的message实际上是分布式存储在一个个小的segment中,为了进一步优化又为分段后的数据建立了索引文件。就是文件系统上的.index文件。这样不仅提高了效率也提高了并行度
5. 批量读写
kafka数据读写也是批量的而不是单条的,这样可以避免在网络上频繁传输单个消息带来的延迟和宽带开销
6. 批量压缩
kafka把所有消息变成一个批量的文件,并且进行合理的批量压缩,减少网络IO,通过mmap提高I/O速度,写入数据的时候由于单个Partition是末尾添加,所以速度最优;读取数据的时候配合sendfile直接读取
7. 什么情况下kafka会丢失消息
kafka有三次消息传递的过程
- 生产者将消息发送给broker
- broker同步消息并持久化
- broker将消息传递给消费者
这其中每一步都有可能丢失消息
- 生产者发送数据:
当acks为0,只要服务端写消息时出现任何问题,都会导致消息丢失
当acks为1,生产者发送消息,只要leader副本成功写入消息,就表示成功。这种方案的问题在于,当返回成功后,如果leader副本和follower副本还没有同步时,leader节点挂了,那么选举新的leader后,消息也就丢失了
- Broker存储数据:
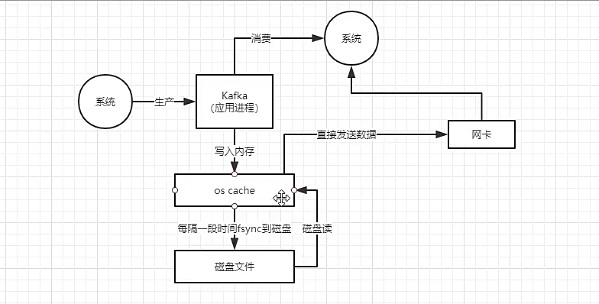
kafka通过Page Cache 将数据写入磁盘
Page Cache就是当往磁盘文件写入的时候,系统会先将数据流写入缓存中,但是什么时候将缓存数据写入文件是由操作系统决定的,如果此时宕机,也会丢失消息
- 消费者消费数据:
在开启自动提交offset时,只要消费者消费到消息,那么就会自动提交偏移量,如果业务还没来得及处理,数据也会丢失















 2138
2138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









