






数仓使用数据库构建
数仓的作用简单来说就是存储数据和读取数据。
绝大部分情况下,数据是结构化的,因此存储数据使用数据库,使用SQL语言进行数据处理。
多维分析
多维分析是指使用数据的场景,查询时组合维度属性和指标,输出特定组合维度下的指标值。
数仓的基本要求是提供多维分析能力。即对于高度聚合的数据可以快速获得结果,例如查看过去一年的去重用户数。
多维分析是从使用者角度看数仓应该提供的能力,而OLAP系统是指具有多维分析能力的系统,相对立的概念是OLTP系统,提供的能力是即时查询。
例如常见的分析行为有:切片,切块,旋转,上卷,下钻,这些操作在没有数据仓库时也能做(数据湖),但是会消耗大量资源且有大量重复劳动,而数仓是提前将这些分析所需数据计算好,在使用时能快速响应。
数据库不只有构建数仓的功能,其更常用的是为业务提供数据存储和查询,前者是OLAP,后者是OLTP。
OLTP是读写量少,要求速度快,保证事务,OLAP是读数据量大,没有写操作,不要求实时。
关于分布式和单机数据库
在OLTP领域,分布式和单机数据库是两个非常不同的领域,短期内不可能出现分布式完全替代单机数据库的情况。因为分布式情况下事件顺序无法确认先后,无法保证事务,建立跨机器二级索引困难,强一致性下只能提供单台机器读写性能,这些问题无法克服。
当前分布式数据库在业务上,只能用于对数据准确性要求不高的业务,或者只提供单机性能但稳定性更高的系统。
在OLAP领域,分布式和单台数据库在构建数仓时没有大区别,只是数据量的不同,即单机数据库和分布式都可以构建OLAP系统。
当前因为各行业数据量快速增长,目前大量OLAP系统采用分布式环境构建。
底层数据使用星型模型
用于OLTP的数据库一般使用范式建模,满足范式时,数据冗余少。
但是实时查询时使用外键进行多次关联会导致速度变的非常慢,例如用户浏览表和用户点击表做关联时,因为两张表数据量过大导致关联查询速度极慢,也可能导致内存不足。
当然业务数据库不会发生大表关联的操作,业务数据库都是直接取部分数据,最多使用二级索引过滤非主键字段。这是因为业务数据库以快速准确的响应为最高优先级,而数仓对查询耗时的要求相对低一些。
OLAP则有大量的大表关联聚合操作,且大表关联后的数据又会用于和其他表做关联聚合(嵌套join)。使用单机数据库时有可能导致内存不足,当下一般使用分布式存储和处理数据。
用于OLAP的数据库使用星型模型,即大表提前关联融合好,产出的表叫宽表或者事实表,与宽表关联的维表数据量都是极少的。以单张事实表为中心,周围是几张小维度表,这是每一个主题的底层数据结构。
星型模型使用空间换时间,提前将事实表和维度表准备好,不进行实时关联。例如要分析用户购物转化主题,则将用户的浏览和实际购买关联,一般浏览数据远大于购买数据,在事实表中购买数据其实是有大量重复的。
什么是主题建模
主题建模是数仓整体建设中的一个环节,数仓建设主要步骤有:数据提取,数据清洗,主题建模,应用层开发,数据接口这几个步骤。
每一个主题的底层由一张事实表和多张维度表组成。
事实表中,除了和维表进行关联的字段外,其余字段为原子指标。
事实表使用维表的属性进行聚合后,产生结果聚合表。
结果聚合表中,除了聚合的维度外,其余字段为衍生指标,即通过原子指标计算而来的指标。
理论上,一个主题包括一个事实表和多个维度表,以及一个结果聚合表。工程实践中可能会有多个事实表,但关联后可以看抽象做一张事实表。工程实践中出于优先级或者性能考虑,可能会将结果切分为多个结果聚合表。
理论上,主题建模是穷尽所有维度属性和指标的组合,以及原子指标到衍生指标的计算逻辑,提供任何维度属性下任意衍生指标的查询。但是在工程实践中,是无法穷尽所有组合的,甚至仅计算考虑到的组合也会远远大于存储和计算的承受能力。
工程实践中,主题建模是对原始数据、原始业务理解的基础上,将数据归类为多个主题,将其中重要的原子指标和重要维度属性进行组合,产出部分维度属性组合下的衍生指标。
主题建模是对数据的分类,这需要对某个领域甚至某个公司内数据特征有深刻理解。主题建模最大的壁垒也在于此,这部分长期来看无法自动化。清晰的主题规划往往是数仓设计成败的关键。
主题建模优势
与主题建模相对的,是按需输出数据,按照产品的需求出对应指标。当然在产出指标前,会查看之前是否产出过相同或者相关指标,如果有的话,会复用之前的数据。
这种按需出指标的方式相比主题建模而言,优势是更加灵活,需求不必等待多维分析数仓建立完成即可开始,前期开发周期短。
主题建模是提前将维度和指标的全集定义好,出尽可能多的维度属性和指标的组合,即全集中的一个子集。
优势在于简洁和稳定,与产品需求解耦,不会随产品需求增加而将数仓变得臃肿,可维护性好,长远来看性能上也更好。
数据清洗和主题建模关系
这两者应该在设计时分开。
- 数据清洗是指对原始数据中的字段进行解析优化,最终形成的事实表。
- 主题建模是指建立快速响应的多维分析体系,以满足产品、分析师对数据读取的需求,从事实表转化结果聚合表。
当原始数据结构复杂时,数据清洗可能无法直接使用SQL进行清洗。并且各个领域下,各个产品的原始数据结构差距很大,一般清洗工作都需要定制化处理,且复用性不高。
这里只描述主题建模的流程。
事实表与主题
事实表是不再需要进行任何清洗操作,只包含维度值和指标的表,一般在数仓分层中为DWD层,特殊情况下也会是DWS层(来自其他主题的结果聚合表)。
主题是无关乎事实表中的维度,而是从指标中抽象出来的,是对事实表所有指标的一个抽象概括。例如事实表是单日单店单品的销售信息,那么主题代表的是销售信息。
事实表要尽可能宽,尽可能容纳此主题下所有指标,如果有新指标需求,则动态添加指标。当前所有数据库都支持动态添加字段的操作。
但是事实表太宽可能导致后续计算资源不足,如果需要拆分事实,拆分事实表的过程即拆分子主题,每个子主题尽可能将未来不会组合计算新指标,并且每个子主题都有业务意义。
- 例如单日单店单品的指标,分为面向顾客的主题和面向仓库的主题,面向顾客的主题包含销售、转化等子主题,面向大仓的主题包含订货、退货等子主题。
- 事实表的拆分涉及行业知识,需要对垂直行业有深入理解才能对主题进行切分。
- 对事实表的拆分不明确,即主题不明确,会导致后续资源的浪费或者维护成本的提高。因为后续可能出现衍生指标需要两个主题出的情况,那么需要再新出一个综合主题。
主题的命名
主题命名建议使用事实表中维度名(主键),加上对事实表指标的抽象进行命名,例如事实表是单日单店单品维度的,指标为销售相关信息,那么主题可以命名为sales_store_goods。
主题的名字应当包含所有信息且简短,一般情况下,不把日期作为主题名称的一部分,因为日期往往是一个默认的维度,可以在维护主题元数据的wiki上增加一列事实表的日期粒度。
主题与分层的关系
主题和分层没有必然联系,一般主题是从DWD层聚合到DWS层,事实表位于DWD层,结果聚合表位于DWS层。但是有些情况下,在某个主题内,DWS层的表也会作为这个主题下的事实表,用于聚合衍生指标。
数据流向在分层体系中不是单向的,即有可能从DWD到DWS,再到DWD。但是在一个主题内,数据流肯定是单向的,即从事实表到结果聚合表。
某些情况下,事实表的某个指标来源复杂,来自某个DWS表的某个字段。但是从主题的角度来看,主题不关心事实表字段来源,只把携带原子指标的表看做底层事实表。例如商品的是否新品是事实表的一个指标,但需要从另一个新品主题的结果聚合表中获取。
原子指标和衍生指标
事实表中的指标为原子指标,这个定义无特殊作用,只表明此主题下其他指标(衍生指标)都根据这些指标计算而来。
事实表中的指标因为口径不同,可能导致难以理解,需要在原子指标定义时明确好指标含义,后续聚合形成的指标也会自动保持口径一致。
不允许对事实表中的原子指标进行修改,只允许增加原子指标。
衍生指标的计算逻辑可能会非常复杂,此时需要考虑拆分结果聚合表。
维度表
维度表包含维度值和维度属性,其中维度值是和事实表关联的主键,维度属性是此维度所属的分类。
维度表是属于主题的,理论上一个维度表只服务于一个主题,在工程实践中可以多个主题共用某一个维度表。例如多个主题共用同一张日期维度表。
维度的属性一般位于维度表中,但有时维度也会转变为事实表中的指标。例如是否新品即可以做维度,统计新品和非新品的销量,也可以作为指标,统计对应分类下,新品的总数量。作为指标时需要提前将维度属性写入事实表中。
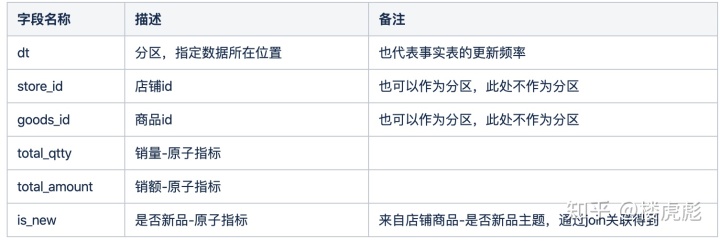
这里使用一种“垂直”的维度表,这种维度表可以让最终生成的SQL代码非常简洁,可用于自动化生成SQL。维度表一共分为四类信息,直接映射为四个字段,即维度表只有四个字段。
- dt:运行周期相关,与运行时间一一对应。维度表和事实表更新频率应该运行周期相同。例如每天的例行任务,维表的日期字段应该为当天或者昨天,维表应该每天更新一次。如果运行周期为分钟,则理论上每分钟都需要产生一个维表,但是工程上可以复用长周期更新的维表。
- 维度名称,用于关联事实表中的维度值,名称不固定,一般与维度表名对应,例如维度表名为dim_store,则此处设置为store_id,里面的值是维度值。
- dim_name:维度属性名称,是维度值所对应的属性名称,即传统维度表中的列名,例如店铺维度下,其中一个属性名称为店铺类型。维度名称的数量是此维度表分类的总数量。
- dim_value:维度属性值,是维度名称对应的取值,例如店铺维度表中,维度属性名称为店铺类型,值为自营店、非自营店。
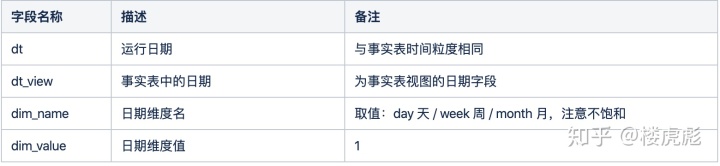
日期维度表
必须将日期也作为一张普通的维度表,日期维度表格式与普通维度表格式相同。需要区分运行日期和事实表中日期字段的概念。
实践中往往只有一个运行日期,但是事实表的日期是一个范围。事实表主键则是运行日期“周围”的一些日期,因为此维表和事实表做关联时,事实表中的日期其实是包含一段时间范围的。
例如运行日期是以天为周期,而每天需要取事实表的当月范围内数据作为一个“临时视图”,此时视图中的日期不只有运行日期,而是与日期维度表中的维度值相对应的日期值。
维度属性名称是这个视图日期对应的属性,例如第几周,是否假期等。而维度属性值固定为1,代表此日期是维度名称代表的属性。
之所以维度属性值固定为1,是因为维度属性名称是不饱和的。一般的维表中,不同维度值对应的维度属性名称都大部分情况下是相同的,例如店铺维表,每个店铺id都包含N个维度属性,而日期维度表不同,例如视图日期是否“在当周时间范围内”,那些不在当周范围内的日期一般不需要统计,所以没有维度属性为0的情况。
注意不饱和性不是日期维表的特征,其他维表也有可能出现维度属性不饱和,只是日期维表出现的较多。
举例,对于某个运行时间dt,不是所有事实表主键都有对应值。例如,"视图日期"维度名称为dt_view,对于运行时间dt=2020-01-01,有天周月的聚合需求,则dt_view的取值不会小于2019-12-01。
日期维表会有不固定数量的维度名称,例如,"视图日期"维度名称为dt_view,对于运行时间dt=2020-01-01,有天周月的聚合需求,dt_view=2019-12-31可以取值为周、月,因为对运行时间dt而言,2019-12-31这个日期在求周指标和月指标时需要用到,dt_view=2020-01-01可取值为天、周、月,dt=2019-12-01可以取值为月,因为对dt而言,2019-12-01这个日期只有在月指标时需要用到。
结果聚合表
结果聚合表中包含各类维度属性的组合,以及按照维度聚合、计算后的衍生指标。
理论上,一个主题只生成一张结果聚合表,可以使用不同分区来区分不同维度下的指标。
工程实践中,不同维度值下数据量存在较大差异,数据量级差距过大的数据存放在一个分区内会导致查询速度变慢,因此需要将维度属性作为分区键。
只有一个结果表的缺点是无论做什么查询,都需要增加where条件筛选维度分区,但是这和分为多个结果表的查询所耗费精力是等价的,因为多表时也需要主题+维度找到对应的数据表。
聚合表的命名规范为dws+主题+运行周期。这里需要注意结果表的主键其实已经扩充为维表所有维度之和,但是工程上一般维度总数很大,不适合做表名。
例如单日单店单品的销售主题,产生的结果聚合表有单月单店大类、单周全店单品等不同维度组合,无法使用聚合后的维度作为表名。
一个主题下只有一个结果表,这能避免表名中描述维度组合,因为只要确定所属主题的来源事实表,即默认所有维度组合指标都在对应结果聚合表中,从而使找表工作更加便捷。
只有一个结果表的更深层次原因是,所有粒度的表应该都从原始的事实表出,例如事实表为天粒度,一般会认为可以天粒度聚合到周粒度再聚合到月粒度,但实践中往往会产生部分指标无法从上一层的聚合指标再聚合得到,典型如需要去重统计的指标。
一个实例来解释以上的内容
以电商行业的销售主题为例,建立多维分析指标,简化指标数量和维度数量后,流程如下:
事实表 dwd_sales_store_goods_di
属于dwd层,主题为单日单店单品-销售,其中维度(主键)为store_id+goods_id+dt,是天级别增量数据(date increase),字段如下
维度表 dim_store 店铺维表

备注:
一个store_id对应多个店铺维度名,例如一个store_id对应dim_name=type时,dim_value=0,dim_name=store_level时,dim_value=3。
在此样例中,认为一个店铺id对应三个dim_name,但是此数仓建设理论上不强制对应的数量。
建议绝大部分维度表增加dim_name=all选项,这是为了方便出“所有店铺的某个品类销量”这类指标。
维度表 dim_goods 商品维表
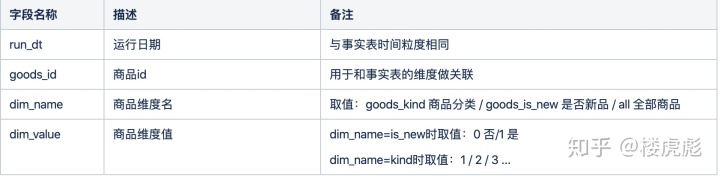
维度表 dim_dt 日期维表
举例说明,其中某几行数据如下

结果聚合表 dws_sales_store_goods_di
属于dws层,为销售(sales)主题,其中维度发生改变,从事实表的店铺+商品+扩展为维表中的所有维度属性,是天级别增量数据(date increase),尽管其中内容有月度指标,字段如下

SQL:
只使用一个SQL来生成结果聚合表。

代码自动生成
因为此处SQL格式严格规范,可以通过事实表和维度表的元数据自动生成SQL,即SQL语句可以自动生成。
还可以加入自动生成调度任务和DAG的逻辑,使整个主题的产出完全自动化。
向后兼容
兼容性主要体现在三个方面:
原子指标、衍生指标的增长:需要增加结果表的schema,所有数据库是兼容的,产生结果表的SQL修改其中读取事实表的查询,可以向后兼容
维度属性的增长:在维度表中增加具体的维度属性即可,不需要其他修改。
维度的增长:产生结果表的SQL增加新的维度表,结果表的schema也进行相应修改。
数据量膨胀
样例中产生了所有维度和指标的组合,和kylin原理类似,容易导致数据量膨胀。
可以进一步优化SQL解决问题,具体是将其中子查询进行限制。限制的方式有以下几种:
对事实表的指标进行限制,有些事实表的指标可能短期内不会使用,可以只提取部分关键字段,这样能减少结果聚合表产生的列数量。未来可以动态添加原子指标。
对维度属性进行限制,某些维度属性暂时不需要产出指标,可以在子查询中进行屏蔽,后续有需要再打开,不需要修改SQL和结果表即可兼容。
对维度表进行限制,某些维度暂时不需要分析,可以在SQL中不进行关联,后续有需求再增加连接。
总结
ONE SOURCE, ONE SQL, ONE TABLE
一个主题只能有一张来源的事实表,通过一个SQL即生成所有目标维度下的指标,最终只形成一张结果聚合表。
某些情况下提供一个API用于访问,不过一个API会导致权限系统复杂等问题,此处不考虑。
其他思考
日期也需要制作一张维度表
在生成结果聚合表之前,所访问的事实表和维度表都不是全量表,是一段时间周期内表的一张视图,这张视图包含了此次要参与计算的所有数据内容。
在生成这个中间视图时,会使用日期字段,这往往会让开发人员对时间分区字段特殊对待。
其实分区字段在SQL语句中和普通字段没有区别,将日期字段作为普通维度是可行的。但可以作为维度的是视图中的日期字段,因为这个日期也需要进行聚合。
所不同的是,因为视图中的日期是过多的,因此日期维度需要承担额外的过滤工作,例如视图中某个日期,有“相对运行日期而言,是否属于周”这个维度,理论上应该取值0和1,但实际只有在周内的日期才有这个维度。
维度表的两种形式讨论
维度表存在两种形式,一种如上所述,另一种是常见的“拍平”形态,即维度表主键+各个维度值。
这两者没有本质区别,只是在生成代码的简洁程度不同。
如果采用拍扁形式,则需要使用grouping set来进行聚合,SQL代码会相对比较复杂。但是扁平方式的可读性更好,通过schema即可得知维表结构。
公平性问题
在聚合任务中,不同维度组合是公平进行的,但是需求上可能部分维度组合的优先级更高。
解决办法是对SQL再包一层,SQL改为可动态传入参数形式,从而将一个SQL切分为多个SQL,将更高优先级的维度组合放在外部SQL的前部。
注意此处如果将所有维度都进行拆分,会造成重复读取数据量过大,导致资源消耗的极大增加。需要平衡所需切分的维度组合,不能切分过细。
DWS到DWA
某些情况下,主题也可以从DWS层到DWA层,前提是形成视图的逻辑基本,例如只是从原来取一段连续时间改为取同环比的时间。
如果项目中所需要出的DWA指标近乎包含所有排列组合,那么可以考虑使用这套框架。
业界工具的讨论
Kylin使用聚合所有维度的形式,提供了毫秒级响应多维查询的需求。但是资源消耗巨大,主要是存储资源。
MPP使用现场计算,将数据导入缓存等方式进行加速。同样资源消耗巨大,主要是计算资源。
以上产品是两个极端,如果有开发能力,建议采用中间状态,即按照多维分析的标准进行设计,在设计完成后,不产出所有维度组合的指标,但可以平滑的进行升级,产出更多指标。
任务深度过深
任务深度过深是难以管理的,主题建模需要在任务深度和任务内部复杂度上做平衡。
主题不能局限于细节,例如五分钟、一小时、半天、一天、一周、一个月、一年都作为一个主题,会造成任务深度过深。
主题不能太粗糙,例如上述时间粒度都集中在一个主题,会导致有些分钟粒度的指标在月维度下没有必要产出。
主题的粗细划分需要对业务原始数据有深刻理解。














 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









