





学习A星算法的实现,要先将迪杰斯特拉算法研究清楚。
A*相对于迪杰斯特拉算法不同点在于,加了一个启发系数,极大降低了搜索空间,提高算法效率,没有这个算法估计很多游戏的NPC寻路都跑不动。
迪杰斯特拉算法在寻找下个点时,选择标准为:
open列表中,距离起点最近的点。即:起点到该点的距离最短
最佳优先搜索算法在寻找下个点时,选择标准为:
open列表中,距离终点最近的点。即:起点到该点的距离最短
A*算法在寻找下个点时,选择标准为:
open列表中,起点到该点的距离 + 该点到终点的直线距离 之和 最短。
Dijkstra算法寻路过程:
在Dijkstra算法中,需要计算每一个节点距离起点的总移动代价。同时,还需要一个优先队列结构。对于所有待遍历的节点,放入优先队列中会按照代价进行排序。
在算法运行的过程中,每次都从优先队列中选出代价最小的作为下一个遍历的节点。直到到达终点为止。
我们可以看到,它总是广度遍历去找目标点;
当无障碍物时,就像水波一样向四周荡漾(左图),当有了障碍物时,他能围绕障碍物荡漾(右图)。
最佳优先搜索算法寻路过程:靠近目标点优先
在一些情况下,如果我们可以预先计算出每个节点到终点的直线距离,则我们可以利用这个信息更快的到达终点。
其原理也很简单。与Dijkstra算法类似,我们也使用一个优先队列,但此时以每个节点到达终点的距离作为优先级,每次始终选取到终点移动代价最小(离终点最近)的节点作为下一个遍历的节点。这种算法称之为最佳优先(Best First)算法。
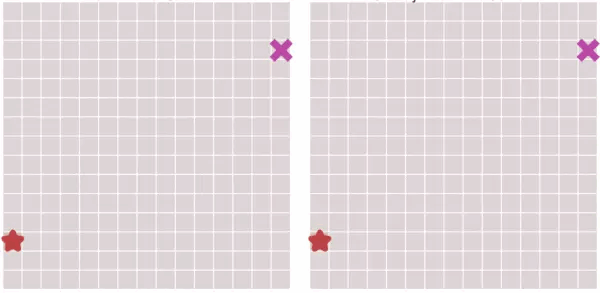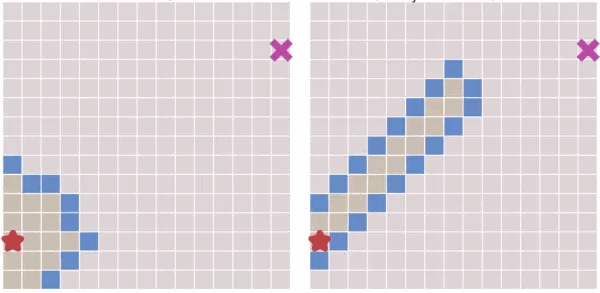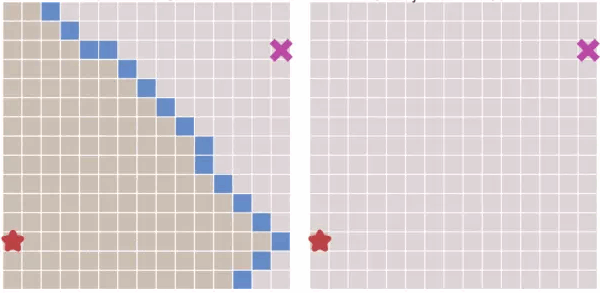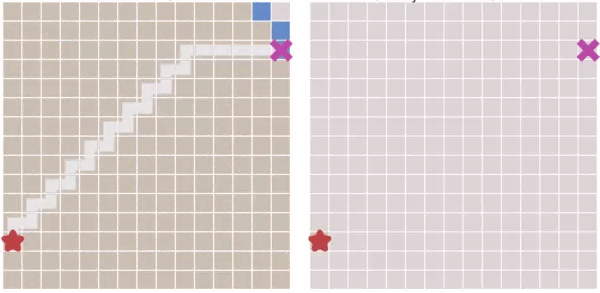
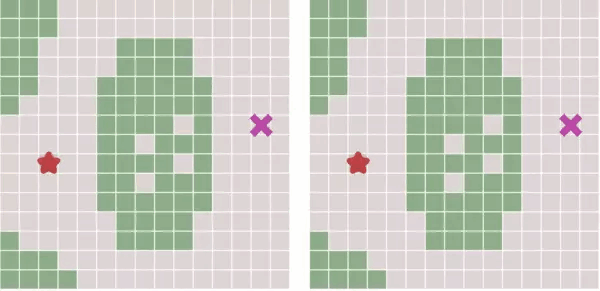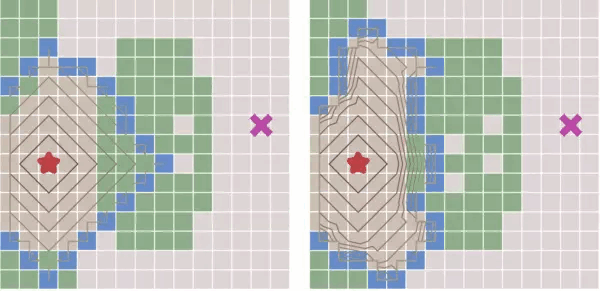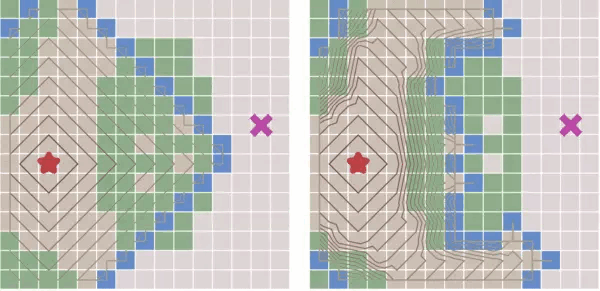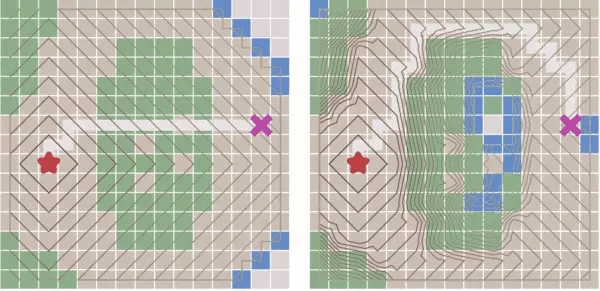
上图是迪杰斯特拉算法和最佳优先算法,在无障碍物下的对比。
我们可以看到,在没有障碍的情况下,最佳优先的速度很快,而迪杰斯特拉算法还 是波浪形的去搜索。
当有障碍物的情况下,迪杰斯特拉算法和最佳优先算法的寻路过程对比:
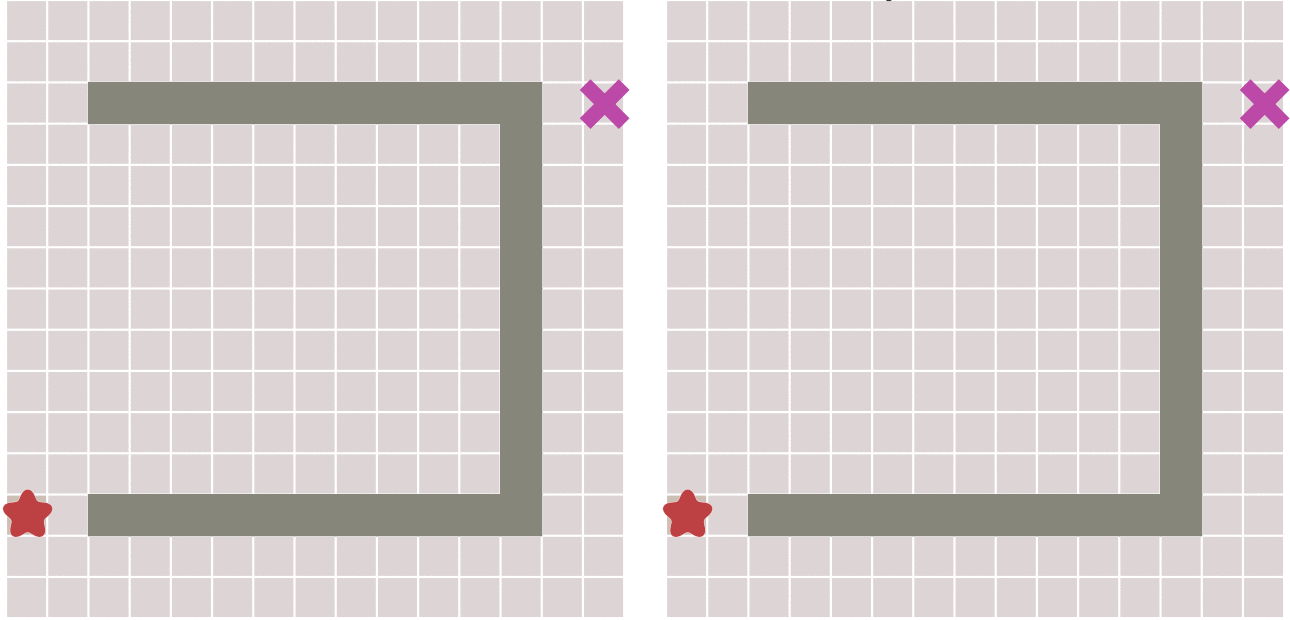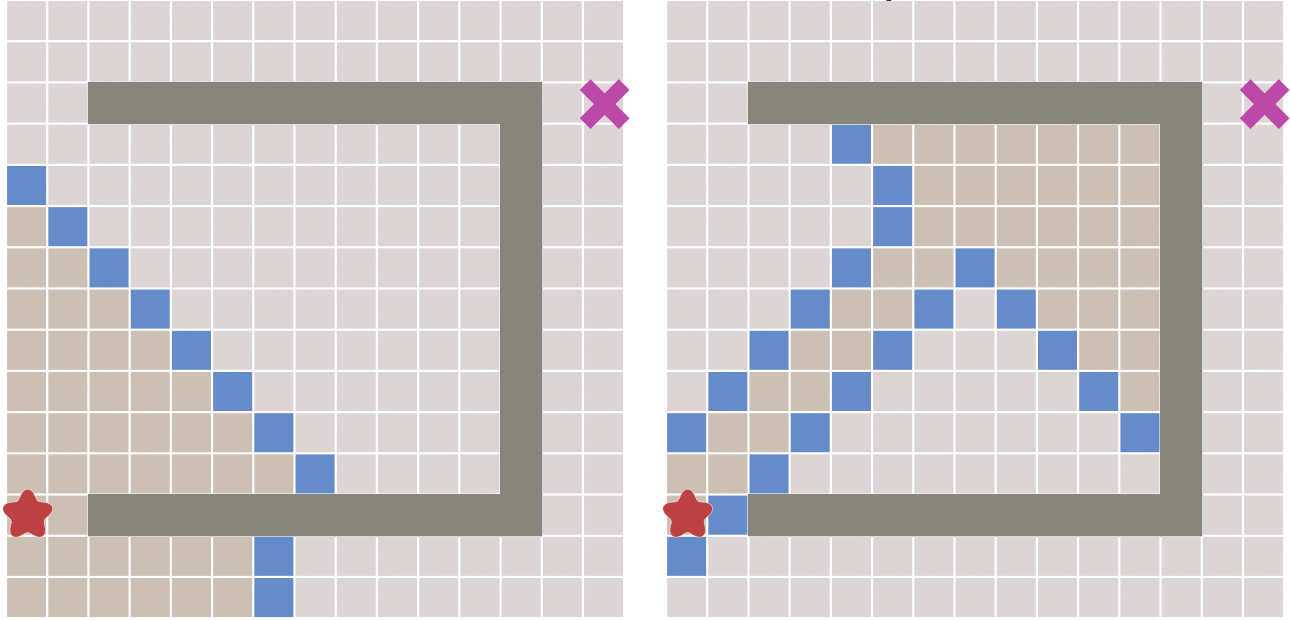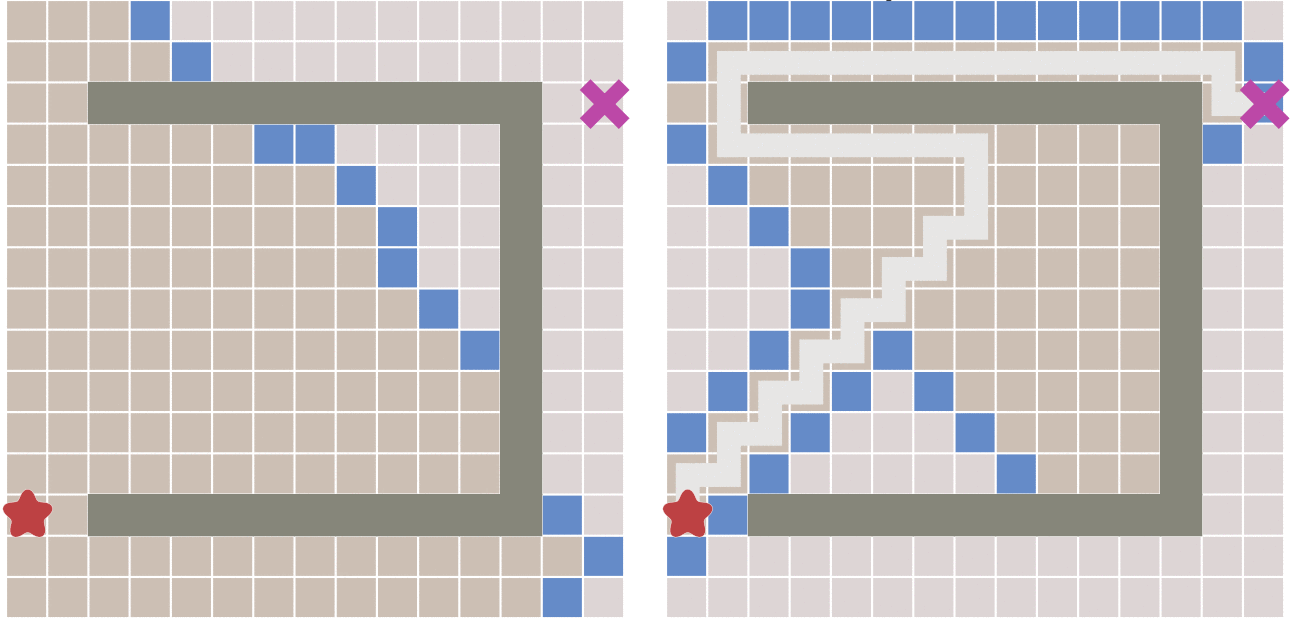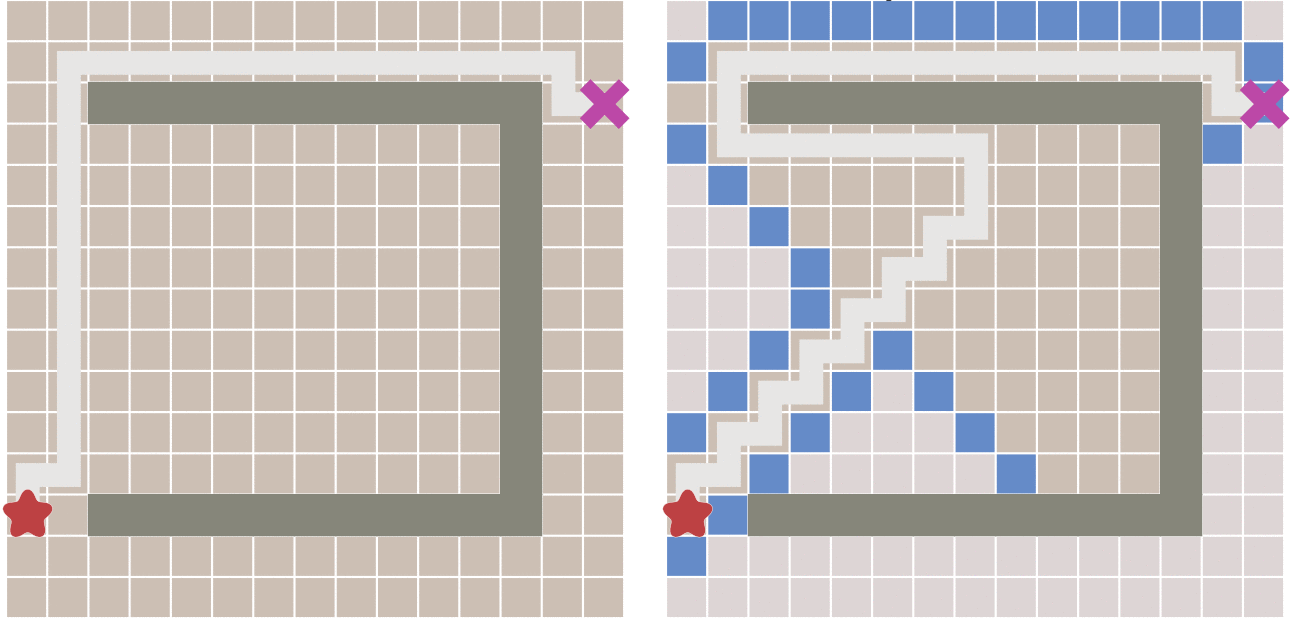
我们可以看到,当遇到障碍时,最佳优先算法 大体趋势会沿着起点到终点的直线为对称轴,左右来回寻点。
从上图可以看出,和 迪杰斯特拉算法相比,最佳优先算法得到的最终路径不一定是最短路径
有点向大门内的狗狗一样,望着门外的陌生人来回左右踱步狂吠。
迪杰斯特拉算法 和 最佳优先算法 的 联系
迪杰斯特拉算法:计算寻路的过程是圆圈向外扩散,比较耗,但是最终路径是最短的路径;
最佳优先算法:计算过程是目标导向型的,过程比较快,但是遇到障碍物时,最终路径不一定是最短的路径;
A*搜索算法
有了上述的两种算法之后,开始正式引入A*算法。
A*就好像结合了上述两种算法的结合体一样,它是根据:起点到该点的距离 + 该点到目标点的距离 之和 来寻路的。
即:
f(n)=g(n)+h(n)
其中:
- f(n) 是节点n的综合优先级。当我们选择下一个要遍历的节点时,我们总会选取综合优先级最高(值最小)的节点。
- g(n) 是节点n距离起点的代价。
- h(n) 是节点n距离终点的预计代价,这也就是A*算法的启发函数。
A*算法在运算过程中,每次从优先队列中选取$f(n)$值最小(优先级最高)的节点作为下一个待遍历的节点。
另外,A*算法使用两个集合来表示待遍历的节点,与已经遍历过的节点,这通常称之为open_set和close_set。
完整的A*算法描述如下:
* 初始化open_set和close_set;
* 将起点加入open_set中,并设置优先级为0(优先级最高);
* 如果open_set不为空,则从open_set中选取优先级最高的节点n:
* 如果节点n为终点,则:
* 从终点开始逐步追踪parent节点,一直达到起点;
* 返回找到的结果路径,算法结束;
* 如果节点n不是终点,则:
* 将节点n从open_set中删除,并加入close_set中;
* 遍历节点n所有的邻近节点:
* 如果邻近节点m在close_set中,则:
* 跳过,选取下一个邻近节点
* 如果邻近节点m在open_set中,则:
* 判断节点n到节点m的 F(n) + cost[n,m] 值是否 < 节点m的 F(m) 。来尝试更新该点,重新设置f值和父节点等数据
* 如果邻近节点m也不在open_set中,则:
* 设置节点m的parent为节点n
* 计算节点m的优先级
* 将节点m加入open_set中A星算法 公式优化:
我们都知道,A星算法的公式为:f(n)=g(n)+h(n)
这是迪杰斯特拉算法和最佳优先算法的结合体。我们可以加个权重K来调节这两种算法的影响程度
f(n)= k * g(n) + (1-k) * h(n) ; k 取值 为 [0,1]
- 当k=0时,f(n)= h(n) ,A星算法就变成了最佳优先算法;以距离目标最近为导向
- 当k=1时,f(n)= g(n) ,A星算法就变成了迪杰斯特拉算法;以距离自己最近为导向
- 当k=0.5时,f(n)=g(n)+h(n) ,A星算法就变成了大家提的A星算法;以距离自己最近 + 距离目标最近 为导向
我们可以通过调节权重K的值,来调节这两种算法的影响程度
我最终发现:
- 算法的权重K=0时,使得花费较少的步骤即可得到答案。即 最佳优先算法,以目标距离为导向。但是最终的路径并不是最短最优的。
- 算法的权重K=1时,花费的步骤是最多的方可得到答案。即 迪杰斯特拉算法,以圆圈波浪为导向。但是最终的路径是最短最优的。
- 算法的权重K=0.5时,最佳优先算法的步骤 < 花费的步骤 < 迪杰斯特拉算法的步骤; 最佳优先算法的最终的路径 > 最终的路径 > 迪杰斯特拉算法的最终的路径。
结论,无障碍物时,最佳优先算法的步骤和结果路径都是最优的。有障碍物时,最佳优先算法的步骤依然最优,但是结果路径不是太理想。因此采用居中策略,采用A*算法,采用寻路步骤和结果路径都合适的方案。
关于距离
1.曼哈顿距离
如果图形中只允许朝上下左右四个方向移动,则启发函数可以使用曼哈顿距离,它的计算方法如下图所示:
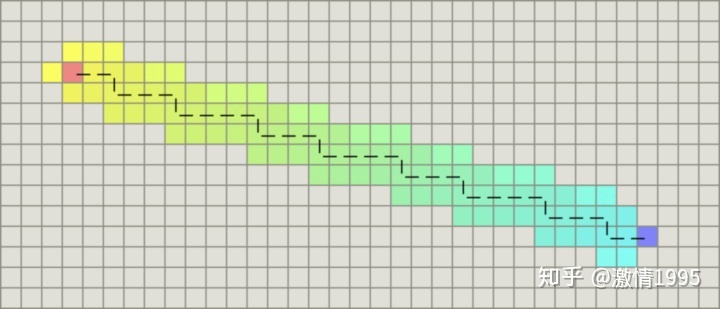
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * (dx + dy) 2.对角距离
如果图形中允许斜着朝邻近的节点移动,则启发函数可以使用对角距离。它的计算方法如下:

计算对角距离的函数如下,这里的D2指的是两个斜着相邻节点之间的移动代价。如果所有节点都正方形,则其值就是
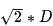
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * (dx + dy) + (D2 - 2 * D) * min(dx, dy) 3.欧几里得距离
如果图形中允许朝任意方向移动,则可以使用欧几里得距离。
欧几里得距离是指两个节点之间的直线距离,因此其计算方法也是我们比较熟悉的:
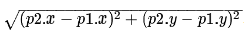
其函数表示如下:
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
return D * sqrt(dx * dx + dy * dy) 













 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









