







因工作的需要开始接触mongodb这个非关系型数据库,下面就将从mongoDb的存储机制和索引的使用俩方面来探究一下mongoDb的内部原理。
mongoDb在早期采用了MMAP存储引擎机制来实现数据的存储,直到mongoDb3.0 之后才引入了插件式的存储机制来支持更多的存储引擎,同时也升级MMAP到MMAP V1 ,并且MMAPV1作为默认的存储引擎 ,但是用户可以选择其它的存储引擎,例如 WiredTiger,InMemory 这些知名的插件存储引擎,到MongoDb 3.2的时候默认的存储引擎已经变更为Wired Tiger ,具体的架构如下图:

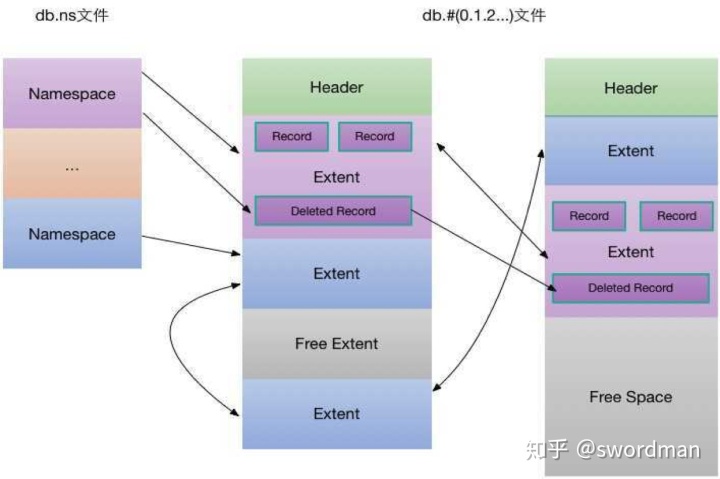
- MMAPV1 存储引擎是一种原始的存储引擎,它是基于内存映射文件来实现的,它擅长使用大容量插入,读取,更新工作负载,是出了名的耗内存,占资源,它会自动占有机器的全部可用内存来缓存数据,但是这个过程是动态的,当其它的进程要使用内存的时候,MMAPV1也会把Cache的内存分配给其它的进程 ,它采用的是操作系统的虚拟内存系统来管理自己的内存的
- 内部原理如图:
WT 存储引擎 我们将从如下的7方面就行介绍
- 文档级别的并发控制-乐观锁机制
- 检查点(Checkpoint)
- 预先记录日志
- WiredTiger 利用系统内存资源缓存两部分数据
- 调整WiredTiger内部缓存的大小
- 数据压缩
- Disk空间回收
- 上面我们介绍的MMAP存储引擎中所有的操作都是基于Collection级以上的互斥锁机制,这样的机制会使得整个数据库的并发的性能下降,然而WT存储引擎截然不同,在日常的使用中大多数对数据库的更新操作都只会对集合中少量的Document进行更新
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









