





基于CDH集群的大数据项目的优化总结
点击上方“技术支持联盟”,选择“置顶公众号”
第一时间了解程序员大小事儿
作者:Jin,一个头发茂密的大数据方向攻城狮,一个爱为小伙伴排忧解难的小伙伴~
摘要:CDH是Cloudera公司的开源平台发行版,包括Apache Hadoop。通过将Hadoop与十几个其他关键的开源项目集成,可执行端到端的大数据工作流程。简单讲:CDH 封装了各类大数据组件,是一个拥有快速安装、中心化管理、集群监控等功能的工具。

概论
由于CDH的便利性,目前作者经历的多数项目都是运行在CDH集群上。近期由于工作需要,对部分大数据项目进行了梳理、优化,在这个过程中发现了一些问题,针对遇到的问题,进行了一些优化。对相关情况进行了总结,如有表述错误或偏差的情况,敬请谅解。
2
02存在现象
在项目运行和集群使用过程中,发现存在性能不理想,达不到预期效果、集群服务不稳定的问题。通过排查日志、监控任务发现,存在以下问题:
1. 因业务属性问题,存在大量数据量大、计算复杂的任务,这部分任务执行效率慢,造成整体作业时间较长;
2. Hdfs Namenode服务暂停,造成任务无法提交
3. Hive Server2服务暂停,造成任务无法提交
4. Impala任务执行失败,返回内存不足情况
5. Impala+kudu任务,仅千万级的数据量计算任务,执行耗时近3小时
6. 集群的计算资源使用不充分,利用率低
0 3基本情况
1. 用户作业方面,目前10个用户进行作业,一半是实时作业用户,一半是离线作业的用户。
2. 资源配置方面,实时作业用户分配资源较少,全天运行任务。离线作业用户分配资源较多,仅在固定时间点进行作业,虽然整体资源较高,但是分配到用户上较分散,利用率不高。
3. 作业类型方面,实时作业以SparkStreaming任务为主,离线作业方面以Hive任务和Impala+Kudu任务为主。
4. 组件使用方面,常出现的问题集中在impala内存不足、hive锁造成任务阻塞、impala+kudu任务耗时较长、hive任务耗时较长等问题上。
5. 组件服务方面,常出现HDFS NameNode服务暂停、HIveServer2服务暂停等现象。
04优化思路
对于发现的问题和梳理出的基本情况,进行点对点式的优化。
1. 在计算资源方面,主要优化思路是提高资源利用率、降低任务资源。
2. 在组件服务方面,主要优化思路是排查组件暂停阶段日志,定位服务暂停原因并进行针对性改进。
3. 在任务耗时方面,主要优化思路是调整sql、核查执行计划,定位慢的原因,同时根据对应组件机制,进行优化。
优化从集群配置和代码程序两方面共同进行。
05具体措施
提升资源利用率
提升任务执行效率最简单的方式,就是从资源上入手,增加计算资源。除了简单的增加资源,还可以从提升资源利用率方面入手。
目前作业用户中,除实时作业外的5个用户,各自进行计算的时间点皆不统一。主要分散在0-2点,2-4点,4-7点的几个时间段,在特点外的时间内,用户没有计算任务,资源是处于空闲状态当中。
对此情况,主要是实现让资源根据时间段来进行分配,将资源有效的使用起来,提高利用率,提升任务执行速度。
对此可以配置YARN组件动态资源池的计划模式,根据时间或日期分配资源。
解决Hive Server2服务暂停问题
个别情况下,出现hive任务报错,作业中断。开发人员从任务日志上查看,jdbc连接hive错误,连接拒绝。

运维人员从组件日志中查看,GC时间过长。

对于该情况,常见原因是H2服务挂掉。从CM组件界面上查看Hive服务运行状况,连接节点的HiveServer2服务确实处于挂掉状态。从监控图上看,该节点的连接数过多,JVM内存达到上限。
解决方案:
(1)集群配置方面根据实际情况调大jvm堆内存上限。
(2)集群配置方面配置H2服务的高可用。
(3)项目组方面对同一个HiveServer2服务,减少并发量。(未配置H2的HA情况下)
(4)项目组方面对SQL进行优化,避免过于复杂且数据量较大的任务,拆分中间表
(5)项目组方面对SQL进行优化,避免同时生成过多的分区/大量动态分区
解决Hdfs NameNode服务暂停问题
作业任务超时,执行失败,任务报错信息返回连接超时等相关错误,经检查impala、hive组件连接正常,但任务执行失败,无法读取或写入数据。根据组件的机制,定位到HDFS组件问题,查看到HDFS NameNode服务运行状态不良。
经排查,是NameNode组件的JVM内存达到上限,频繁GC,该参数受到HDFS 中文件夹、文件数量影响,发现当时文件数达到1300多万,但实际HDFS存储占用不大。
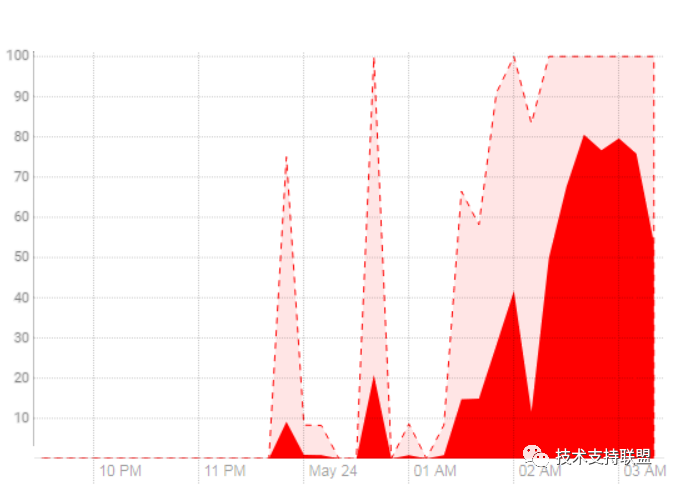
当时组件监控状态
解决方案:
(1)集群配置方面根据实际情况调大jvm堆内存上限。
(2)集群配置方面配置NameNode服务的高可用。
(3)项目组方面降低小文件数
优化小文件数
在使用过程中出HDFS小文件过多,除了造成HDFS NameNode组件暂停外,还对计算任务有影响,小文件过多,影响读取性能。
对HDFS组件中文件情况进行统计,发现文件数过多的情况主要集中在OGG实时同步任务和Hive任务当中。
OGG任务是每分钟同步一次,生成一个或多个文件(单表全天至少3600个文件),没有再做定期合并,存在大量小/空文件情况。
Hive任务主要是进行计算然后落地的数据表,存储文件存在大量低于50M的文件,但整表大小是大于G级别的。经检查,hive组件中涉及到合并部分的参数配置过低,并未进行调优,故默认生成的文件数较小。
解决方案:
(1)集群配置提高合并相关配置参数。
(2)项目组方面在脚本中根据情况设定参数合并文件。
(3)项目组方面对OGG任务中添加定期合并数据文件逻辑
Hive on spark模式
在使用Hive组件进行离线计算过程中,发现遇到大表计算、复杂关联计算的场景时,执行缓慢,个别任务的缓慢造成了项目整体完成时间的延迟。
当前Hive计算引擎使用的是默认的MapReduce,在CDH6.0.0集群中,还可以选择Spark作为执行引擎并且Hive on spark模式性能远优于hive on MapReduce,但由于默认的参数配置过低,hive on spark 模式下无法合理使用资源,性能达不到预期效果,资源无法全部利用,在集群方面修改参数可能会影响其他用户项目而且需要重启集群,所以没有从集群方面修改。后考虑在Hive脚本中设置Session级参数进行个性化修改,但又由于当前集群Hive的权限限制无法修改,相关参数在无法修改的名单当中。
解决方案:
(1)集群方面将相关配置参数添加到白名单当中,修改hive.security.authorization.sqlstd.confwhitelist.append参数。
(2)项目组方面在程序中根据实际情况设置session级参数,调整内存、核数等配置
优化impala+kudu任务
在检查作业日志过程中,发现一个impala+kudu计算任务,执行时间达到2.5-3个小时,后续任务依赖于该任务,从而造成调度阻塞,影响整体的完成时间。
对该任务进行检查时,主要是检查任务的执行计划及对应时间,发现任务主要堵塞在线程存储等待时间和KUDU扫描时间。
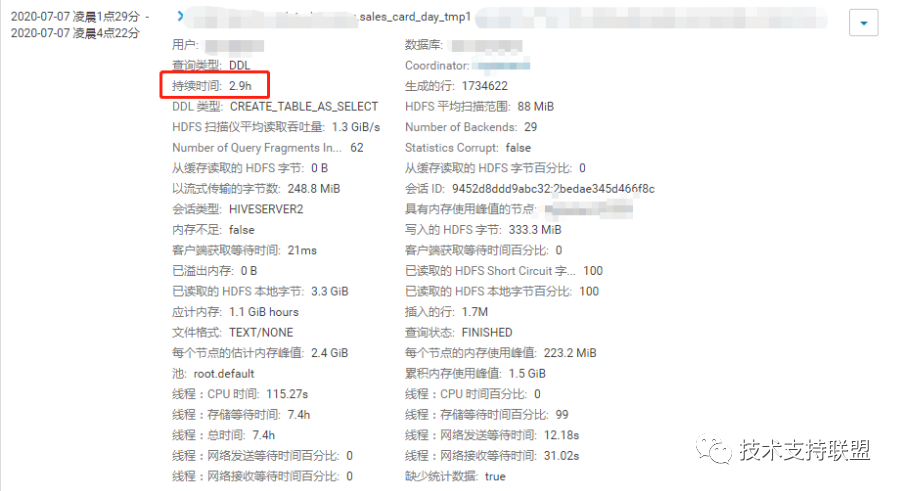
根据具体的执行计划后发现,kudu表扫描速度低到每秒500条左右,性能极差。Kudu是存在缓存的概念,表数据若在缓存当中,则读取性能高,若不在缓存当中,需要临时读取磁盘,遇到磁盘IO高,网络波动大等情况下,读取很缓慢。
解决方案:
(1)集群方面提高kudu组件缓存参数上限,提升读性能
(2)集群方面增加机器内存配置
(3)项目组方面降低数据表数据量
(4)项目组方面根据kudu特性进行代码开发,修改语法
(5)项目组方面临时性增加定时任务,将数据表保持在热数据状态
优化impala使用
impala组件单节点内存上限分别是25G/35G,原来集群没有操作资源隔离,用户使用内存没有设置上限,故所有任务都能够提交,目前完成资源隔离后,各用户有资源使用上限,故在使用过程中,impala部分任务提交失败,返回内存不足。

解决方案:
(1)项目组方面在提交任务前使用compute stats XXX命令,统计表信息;
06达成效果
1. 提高资源利用率方面,配置计划模式实现根据时间段动态使用资源。配置完成后用户G、用户H整体作业完成时间分别提升1小时左右。配置情况如下:
 2. 使用hive on spark 模式并设定合理参数后,性能提升至少35%-50%,作业耗时减少将近一半。对比图如下:
2. 使用hive on spark 模式并设定合理参数后,性能提升至少35%-50%,作业耗时减少将近一半。对比图如下:
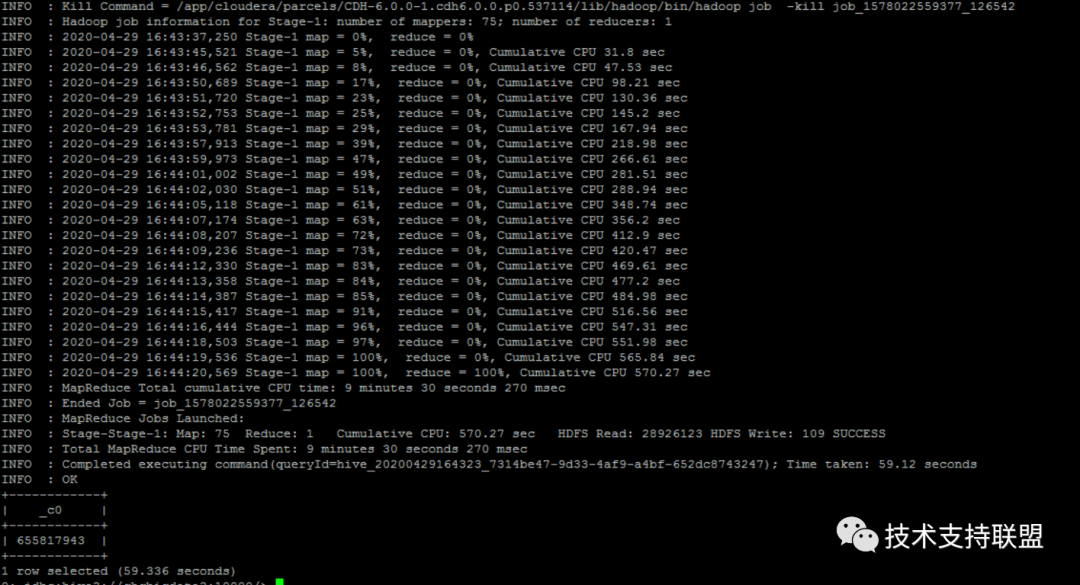
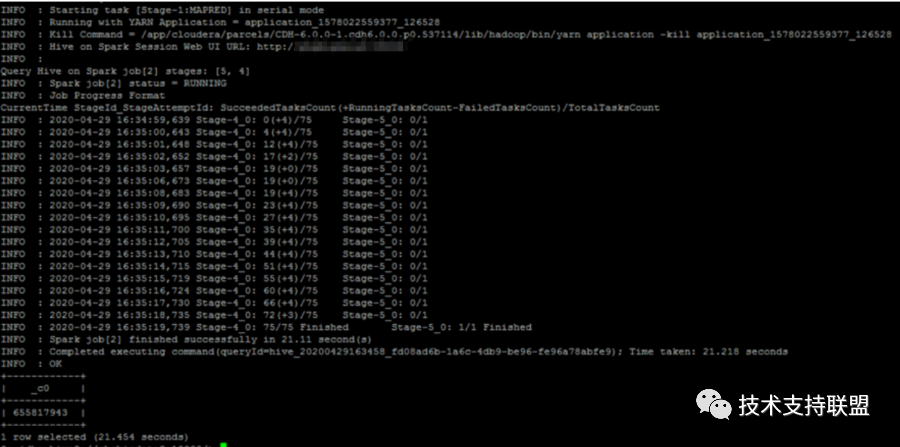
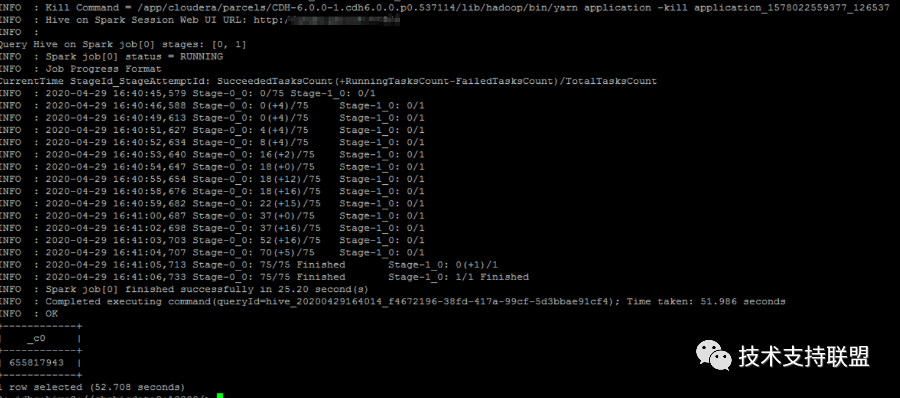
测试序号 | 作业名 | 执行引擎 | 设置executor内存 | 耗时 |
1 | Mem16G | spark | 16G | 21s |
2 | Mem4G | spark | 4G | 52s |
3 | -- | mr | -- | 59s |
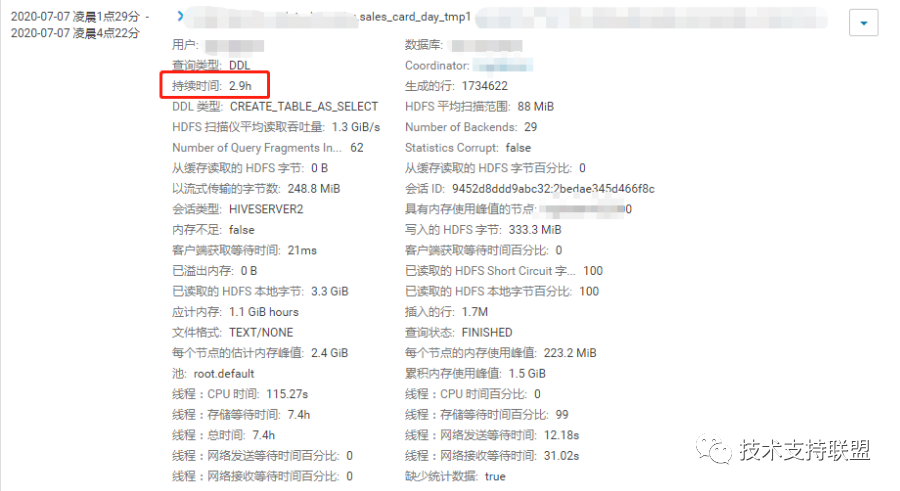
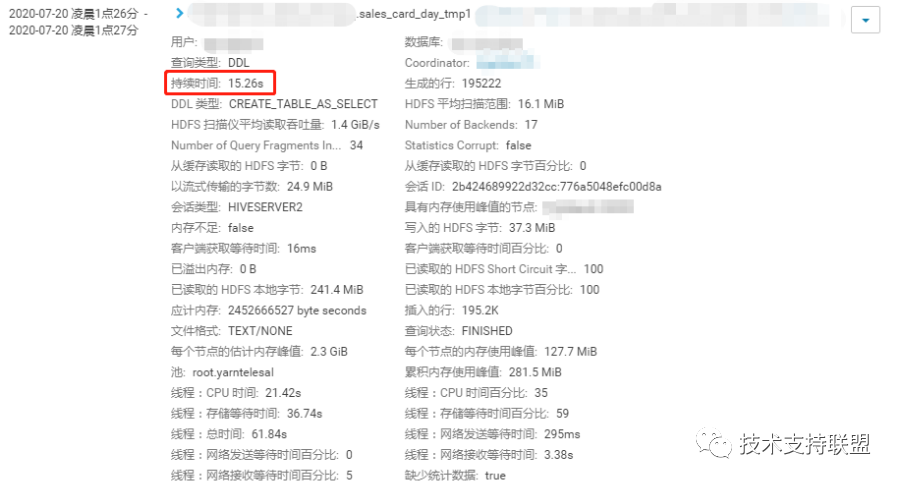
3. 优化impala+kudu任务后,个别任务作业耗时由2.5-3小时降为秒级;该项目作业整体运行时间提前两小时完成。对比图如下:
4. 因内存问题报错的Impala任务在执行前增加compute stats命令后,能够在当前上限资源情况下执行完成作业。
5. 调整hive、hdfs组件、进行小文件合并后,截止目前没有再出现过相同错误造成的服务暂停现象。
07总结
大数据项目依赖于稳定的集群环境和高效的程序,同时大数据项目使用多组件共同运行,具有一定的复杂性,针对不同的业务场景、不同的数据量、不同的组件、不同的硬件,解决方案都不相同,集群和程序两方面都需要进行协调沟通,针对性的进行更改参数或程序。
 END
END
















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









