










作者:萧寒
GitHub ID :hx23840
阿列夫科技原来的技术平台是基于 Hadoop,Spark 平台搭建的,为了充分的满足业务需求,做了大量接口封装。但是随着业务发展,现有技术平台日渐满足不了业务需求。Apache Linkis 提供了统一的对接方式,同时,在性能方面也有了极大提升,满足了我们在产品迭代更新的需求。如下是基于 Apache Linkis + DataSphere Studio 的单机安装部署实战内容,请君享用。
阿列夫科技:https://www.alephf.com/
一、环境以及版本
-
CentOS 7
-
DataSphere Studio1.1.0
-
Jdk-8
-
Hadoop 2.7.2
-
Hive 2.3.3
-
Spark 2.4.3
-
MySQL 5.5
二、基础环境准备
1、基础软件安装
sudo yum install -y telnet tar sed dos2unix mysql unzip zip expect python java-1.8.0-openjdk java-1.8.0-openjdk-devel
nginx安装特殊一些,不在默认的 yum 源中,可以使用 epel 或者官网的 yum 源,本例使用官网的 yum 源
sudo rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
sudo yum install -y nginx
sudo systemctl enable nginx
sudo systemctl start nginx
MySQL (5.5+); JDK (1.8.0_141 以上); Python(2.x 和 3.x 都支持); Nginx
特别注意 MySQL 和 JDK 版本,否则后面启动会有问题
2、Hadoop 安装
采用官方安装包安装,要求 Hadoop 版本对应如下
Hadoop (2.7.2,Hadoop 其他版本需自行编译 Linkis) ,安装的机器必须支持执行 hdfs dfs -ls / 命令
官方下载页面 https://hadoop.apache.org/release/2.7.2.html
安装步骤,创建用户
sudo useradd hadoop
修改 hadoop 用户,切换到 root 帐号,编辑 /etc/sudoers(可以使用 visudo 或者用 vi,不过vi 要强制保存才可以),添加下面内容到文件最下方
hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL
切换回 hadoop 用户,解压缩安装包
su hadoop
tar xvf hadoop-2.7.2.tar.gz
sudo mkdir -p /opt/hadoop
sudo mv hadoop-2.7.2 /opt/hadoop/
配置环境变量
sudo vim /etc/profile
添加如下内容(偷下懒,把后面的 Hive 和 Spark 环境变量也一同配置好了)
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.2
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.3.3-bin/conf
export HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.3.3-bin/lib
export HIVE_HOME=/opt/hive/apache-hive-2.3.3-bin
export SPARK_HOME=/opt/spark/spark-2.4.3-bin-without-hadoop
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.2/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
使配置生效
source /etc/profile
配置免密登录,过程是先生成公私钥,再把公钥拷贝到对应的帐号下
ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@127.0.0.1
配置成功后,测试下是否成功,如果不需要输入密码,证明配置成功。
ssh localhost
添加 hosts 解析
sudo vi /etc/hosts
修改后
192.168.1.211 localhost
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 namenode
配置 Hadoop
mkdir -p /opt/hadoop/hadoop-2.7.2/hadoopinfra/hdfs/namenode
mkdir -p /opt/hadoop/hadoop-2.7.2/hadoopinfra/hdfs/datanode
vi /opt/hadoop/hadoop-2.7.2/etc/hadoop/core-site.xml
core-site.xml 修改如下
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.7.2/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
修改 Hadoop 的 hdfs 目录配置
vi /opt/hadoop/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
hdfs-site.xml 修改如下
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop-2.7.2/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop-2.7.2/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
修改 Hadoop 的 yarn 配置
vi /opt/hadoop/hadoop-2.7.2/etc/hadoop/yarn-site.xml
yarn-site.xml 修改如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
</configuration>
修改 mapred
cp /opt/hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml
vi /opt/hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml
mapred-site.xml 修改如下
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
修改 Hadoop 环境配置文件
vi /opt/hadoop/hadoop-2.7.2/etc/hadoop/hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64/
初始化hadoop
hdfs namenode -format/opt/hadoop/hadoop-2.7.2/sbin/start-dfs.sh /opt/hadoop/hadoop-2.7.2/sbin/start-yarn.sh
临时关闭防火墙
sudo systemctl stop firewalld
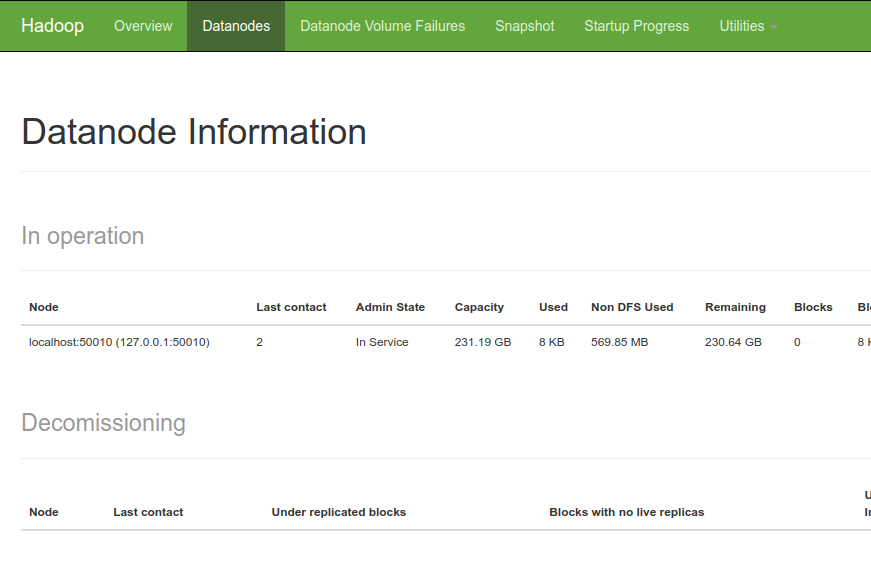
浏览器访问 Hadoop
访问 hadoop 的默认端口号为 50070
3、Hive 安装
采用官方安装包安装,要求 Hive 版本对应如下
Hive(2.3.3,Hive 其他版本需自行编译 Linkis),安装的机器必须支持执行 hive -e “show databases” 命令
官方下载页面 https://archive.apache.org/dist/hive/hive-2.3.3/
tar xvf apache-hive-2.3.3-bin.tar.gzsudo mkdir -p /opt/hivesudo mv apache-hive-2.3.3-bin /opt/hive/
修改配置文件
cd /opt/hive/apache-hive-2.3.3-bin/conf/sudo cp hive-env.sh.template hive-env.shsudo cp hive-default.xml.template hive-site.xmlsudo cp hive-log4j2.properties.template hive-log4j2.propertiessudo cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
在Hadoop中创建文件夹并设置权限
hadoop fs -mkdir -p /data/hive/warehousehadoop fs -mkdir /data/hive/tmphadoop fs -mkdir /data/hive/loghadoop fs -chmod -R 777 /data/hive/warehousehadoop fs -chmod -R 777 /data/hive/tmphadoop fs -chmod -R 777 /data/hive/loghadoop fs -mkdir -p /spark-eventlog
修改hive配置文件
sudo vi hive-site.xml
配置文件如下
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.--><configuration><property> <name>hive.exec.scratchdir</name> <value>hdfs://127.0.0.1:9000/data/hive/tmp</value></property><property> <name>hive.metastore.warehouse.dir</name> <value>hdfs://127.0.0.1:9000/data/hive/warehouse</value></property><property> <name>hive.querylog.location</name> <value>hdfs://127.0.0.1:9000/data/hive/log</value></property><property> <name>hive.metastore.schema.verification</name> <value>false</value></property><property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value></property><property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value></property><property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value></property><property> <name>javax.jdo.option.ConnectionPassword</name> <value></value></property> <property> <name>system:java.io.tmpdir</name> <value>/tmp/hive/java</value> </property> <property> <name>system:user.name</name> <value>hadoop</value> </property> <property> <name>hive.exec.local.scratchdir</name> <value>/opt/hive/apache-hive-2.3.3-bin/tmp/${system:user.name}</value> <description>Local scratch space for Hive jobs</description> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/opt/hive/apache-hive-2.3.3-bin/tmp/${hive.session.id}_resources</value> <description>Temporary local directory for added resources in the remote file system.</description> </property><property> <name>hive.server2.logging.operation.log.location</name> <value>/opt/hive/apache-hive-2.3.3-bin/tmp/root/operation_logs</value> <description>Top level directory where operation logs are stored if logging functionality is enabled</description> </property></configuration>
配置 hive 中 jdbc 的 MySQL 驱动
cd /opt/hive/apache-hive-2.3.3-bin/lib/
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.49.tar.gz
tar xvf mysql-connector-java-5.1.49.tar.gz
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar .
配置环境变量
sudo vi /opt/hive/apache-hive-2.3.3-bin/conf/hive-env.shexport HADOOP_HOME=/opt/hadoop/hadoop-2.7.2export HIVE_CONF_DIR=/opt/hive/apache-hive-2.3.3-bin/confexport HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.3.3-bin/lib
初始化 schema
/opt/hive/apache-hive-2.3.3-bin/bin/schematool -dbType mysql -initSchema
初始化完成后修改MySQL链接信息,之后配置MySQL IP 端口以及放元数据的库名称
vi /opt/hive/apache-hive-2.3.3-bin/conf/hive-site.xml<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://127.0.0.1:3306/hive?characterEncoding=utf8&useSSL=false</value></property>nohup hive --service metastore >> metastore.log 2>&1 &nohup hive --service hiveserver2 >> hiveserver2.log 2>&1 &
```
验证安装
```
hive -e "show databases"
```
**4、Spark** **安装**
------------------
采用官方安装包安装,要求 Spark 版本对应如下
Spark (支持2.0 以上所有版本) ,一键安装版本,需要 2.4.3 版本,安装的机器必须支持执行 spark-sql -e "show databases" 命令
官方下载页面 https://archive.apache.org/dist/spark/spark-2.4.3/
安装
```
tar xvf spark-2.4.3-bin-without-hadoop.tgzsudo mkdir -p /opt/sparksudo mv spark-2.4.3-bin-without-hadoop /opt/spark/
```
配置spark环境变量以及备份配置文件
```
cd /opt/spark/spark-2.4.3-bin-without-hadoop/conf/cp spark-env.sh.template spark-env.shcp spark-defaults.conf.template spark-defaults.confcp metrics.properties.template metrics.propertiescp workers.template workers
```
配置程序的环境变量
```
vi spark-env.shexport JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64export HADOOP_HOME=/opt/hadoop/hadoop-2.7.2export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.2/etc/hadoopexport SPARK_DIST_CLASSPATH=$(/opt/hadoop/hadoop-2.7.2/bin/hadoop classpath)export SPARK_MASTER_HOST=127.0.0.1export SPARK_MASTER_PORT=7077export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://127.0.0.1:9000/spark-eventlog"
```
修改默认的配置文件
```
vi spark-defaults.confspark.master spark://127.0.0.1:7077spark.eventLog.enabled truespark.eventLog.dir hdfs://127.0.0.1:9000/spark-eventlogspark.serializer org.apache.spark.serializer.KryoSerializerspark.driver.memory 3gspark.eventLog.enabled truespark.eventLog.dir hdfs://127.0.0.1:9000/spark-eventlogspark.eventLog.compress true
```
配置工作节点
```
vi workers127.0.0.1
```
配置 hive
```
cp /opt/hive/apache-hive-2.3.3-bin/conf/hive-site.xml /opt/spark/spark-2.4.3-bin-without-hadoop/conf
```
```
验证应用程序
/opt/spark/spark-2.4.3-bin-without-hadoop/sbin/start-all.sh
访问集群中的所有应用程序的默认端口号为 8080
验证安装
spark-sql -e “show databases”
提示
Error: Failed to load class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.
Failed to load main class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.
You need to build Spark with -Phive and -Phive-thriftserver.
查找原因是因为没有集成hadoop的spark没有hive驱动,按网上的讲法,要么自己编译带驱动版本,要么把驱动文件直接放到jars目录。第一种太麻烦,第二种没成功,我用的第三种方法。下载对应版本集成了hadoop的spark安装包,直接覆盖原来的jars目录
tar xvf spark-2.4.3-bin-hadoop2.7.tgz
cp -rf spark-2.4.3-bin-hadoop2.7/jars/ /opt/spark/spark-2.4.3-bin-without-hadoop/
如果提示缺少 MySQL 驱动,可以将 mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar 放入到 spark 的 jars 目录
如果本地没有相关驱动,执行下面脚本
cd /opt/spark/spark-2.4.3-bin-without-hadoop/jars
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.49.tar.gz
tar xvf mysql-connector-java-5.1.49.tar.gz
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar .
5、DataSphere Studio 安装
准备安装包
-----
unzip -d dss dss_linkis_one-click_install_20220704.zipsudo yum -y install epel-releasesudo yum install -y python-pippython -m pip install matplotlib
修改配置
----
用户需要对 xx/dss\_linkis/conf 目录下的 config.sh 和 db.sh 进行修改
deploy userdeployUser=hadoop### Linkis_VERSIONLINKIS_VERSION=1.1.1### DSS WebDSS_NGINX_IP=127.0.0.1DSS_WEB_PORT=8085### DSS VERSIONDSS_VERSION=1.1.0############## ############## linkis的其他默认配置信息 start ############## ################# Specifies the user workspace, which is used to store the user’s script files and log files.### Generally local directory##file:// requiredWORKSPACE_USER_ROOT_PATH=file:///tmp/linkis/ ### User’s root hdfs path##hdfs:// requiredHDFS_USER_ROOT_PATH=hdfs:///tmp/linkis ### Path to store job ResultSet:file or hdfs path##hdfs:// requiredRESULT_SET_ROOT_PATH=hdfs:///tmp/linkis ### Path to store started engines and engine logs, must be localENGINECONN_ROOT_PATH=/appcom/tmp#ENTRANCE_CONFIG_LOG_PATH=hdfs:///tmp/linkis/ ##hdfs:// required###HADOOP CONF DIR #/appcom/config/hadoop-configHADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.2/etc/hadoop###HIVE CONF DIR #/appcom/config/hive-configHIVE_CONF_DIR=/opt/hive/apache-hive-2.3.3-bin/conf###SPARK CONF DIR #/appcom/config/spark-configSPARK_CONF_DIR=/opt/spark/spark-2.4.3-bin-without-hadoop/conf# for installLINKIS_PUBLIC_MODULE=lib/linkis-commons/public-module##YARN REST URL spark engine requiredYARN_RESTFUL_URL=http://127.0.0.1:8088## Engine version conf#SPARK_VERSIONSPARK_VERSION=2.4.3##HIVE_VERSIONHIVE_VERSION=2.3.3PYTHON_VERSION=python2## LDAP is for enterprise authorization, if you just want to have a try, ignore it.#LDAP_URL=ldap://localhost:1389/#LDAP_BASEDN=dc=webank,dc=com#LDAP_USER_NAME_FORMAT=cn=%s@xxx.com,OU=xxx,DC=xxx,DC=com################### The install Configuration of all Linkis’s Micro-Services ####################### NOTICE:# 1. If you just wanna try, the following micro-service configuration can be set without any settings.# These services will be installed by default on this machine.# 2. In order to get the most complete enterprise-level features, we strongly recommend that you install# the following microservice parameters#### EUREKA install information### You can access it in your browser at the address below:http:// E U R E K A I N S T A L L I P : {EUREKA_INSTALL_IP}: EUREKAINSTALLIP:{EUREKA_PORT}### Microservices Service Registration Discovery CenterLINKIS_EUREKA_INSTALL_IP=127.0.0.1LINKIS_EUREKA_PORT=9600#LINKIS_EUREKA_PREFER_IP=true### Gateway install information#LINKIS_GATEWAY_INSTALL_IP=127.0.0.1LINKIS_GATEWAY_PORT=9001### ApplicationManager#LINKIS_MANAGER_INSTALL_IP=127.0.0.1LINKIS_MANAGER_PORT=9101### EngineManager#LINKIS_ENGINECONNMANAGER_INSTALL_IP=127.0.0.1LINKIS_ENGINECONNMANAGER_PORT=9102### EnginePluginServer#LINKIS_ENGINECONN_PLUGIN_SERVER_INSTALL_IP=127.0.0.1LINKIS_ENGINECONN_PLUGIN_SERVER_PORT=9103### LinkisEntrance#LINKIS_ENTRANCE_INSTALL_IP=127.0.0.1LINKIS_ENTRANCE_PORT=9104### publicservice#LINKIS_PUBLICSERVICE_INSTALL_IP=127.0.0.1LINKIS_PUBLICSERVICE_PORT=9105### cs#LINKIS_CS_INSTALL_IP=127.0.0.1LINKIS_CS_PORT=9108########## Linkis微服务配置完毕##### ################### The install Configuration of all DataSphereStudio’s Micro-Services ####################### NOTICE:# 1. If you just wanna try, the following micro-service configuration can be set without any settings.# These services will be installed by default on this machine.# 2. In order to get the most complete enterprise-level features, we strongly recommend that you install# the following microservice parameters#### DSS_SERVER### This service is used to provide dss-server capability.### project-server#DSS_FRAMEWORK_PROJECT_SERVER_INSTALL_IP=127.0.0.1#DSS_FRAMEWORK_PROJECT_SERVER_PORT=9002### orchestrator-server#DSS_FRAMEWORK_ORCHESTRATOR_SERVER_INSTALL_IP=127.0.0.1#DSS_FRAMEWORK_ORCHESTRATOR_SERVER_PORT=9003### apiservice-server#DSS_APISERVICE_SERVER_INSTALL_IP=127.0.0.1#DSS_APISERVICE_SERVER_PORT=9004### dss-workflow-server#DSS_WORKFLOW_SERVER_INSTALL_IP=127.0.0.1#DSS_WORKFLOW_SERVER_PORT=9005### dss-flow-execution-server#DSS_FLOW_EXECUTION_SERVER_INSTALL_IP=127.0.0.1#DSS_FLOW_EXECUTION_SERVER_PORT=9006###dss-scriptis-server#DSS_SCRIPTIS_SERVER_INSTALL_IP=127.0.0.1#DSS_SCRIPTIS_SERVER_PORT=9008###dss-data-api-server#DSS_DATA_API_SERVER_INSTALL_IP=127.0.0.1#DSS_DATA_API_SERVER_PORT=9208###dss-data-governance-server#DSS_DATA_GOVERNANCE_SERVER_INSTALL_IP=127.0.0.1#DSS_DATA_GOVERNANCE_SERVER_PORT=9209###dss-guide-server#DSS_GUIDE_SERVER_INSTALL_IP=127.0.0.1#DSS_GUIDE_SERVER_PORT=9210########## DSS微服务配置完毕################### ############## other default configuration 其他默认配置信息 ############## ################ java application default jvm memoryexport SERVER_HEAP_SIZE=“512M”##sendemail配置,只影响DSS工作流中发邮件功能EMAIL_HOST=smtp.163.comEMAIL_PORT=25EMAIL_USERNAME=xxx@163.comEMAIL_PASSWORD=xxxxxEMAIL_PROTOCOL=smtp### Save the file path exported by the orchestrator serviceORCHESTRATOR_FILE_PATH=/appcom/tmp/dss### Save DSS flow execution service log pathEXECUTION_LOG_PATH=/appcom/tmp/dss
脚本安装
----
cd xx/dss_linkis/binsh install.sh
等待安装脚本执行完毕,再进到 linkis 目录里修改对应的配置文件
修改 linkis-ps-publicservice.properties 配置,否则 hive 数据库刷新不出来表
linkis.metadata.hive.permission.with-login-user-enabled=false
拷贝缺少的 jar
cp /opt/hive/apache-hive-2.3.3-bin/lib/datanucleus-* ~/dss/linkis/lib/linkis-engineconn-plugins/hive/dist/v2.3.3/lib
cp /opt/hive/apache-hive-2.3.3-bin/lib/jdo ~/dss/linkis/lib/linkis-engineconn-plugins/hive/dist/v2.3.3/lib
安装完成后启动
sh start-all.sh
```
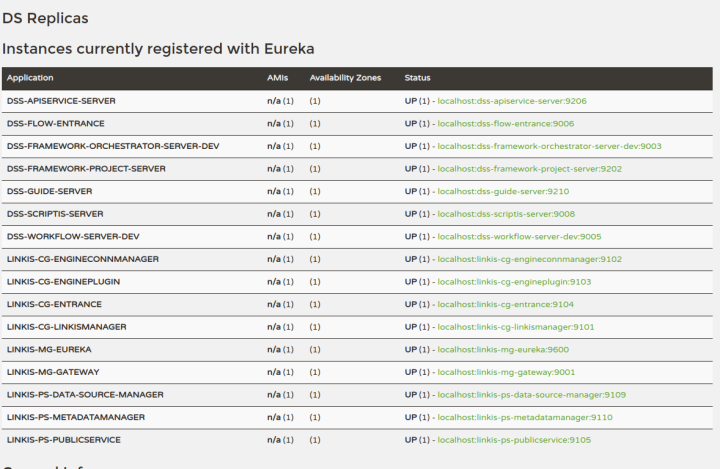
启动完成后 eureka 注册页面
最后一个坑,前端部署完会报权限错误,把前端迁移到 opt 目录,记得修改nginx 配置
```
sudo cp -rf web/ /opt/
```
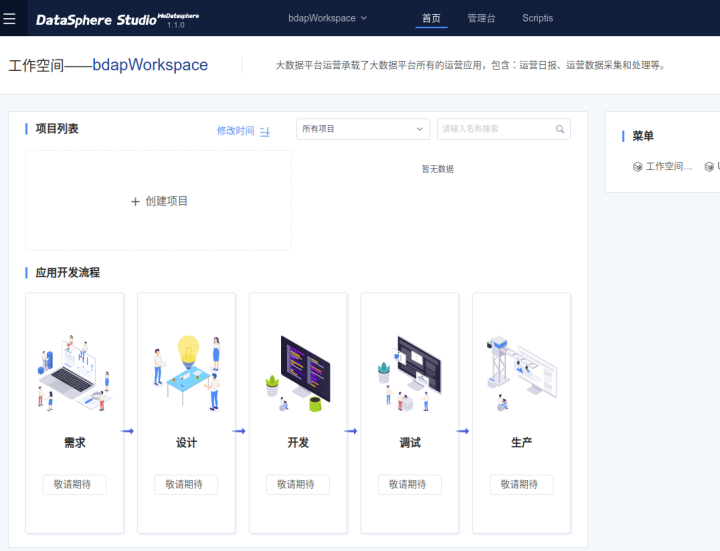
最后系统启动完毕
征文投稿 持续进行中, 期待大家多多参与~
地址(或点击阅读原文):https://github.com/apache/incubator-linkis/discussions/categories/solicit-articles-%E5%BE%81%E6%96%87
说明:https://github.com/apache/incubator-linkis/discussions/2223
— END —
● 往期精选 ●
[版本动态 | Apache Linkis(incubating) 1.1.0 版本发布](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488511&idx=1&sn=6d05d4ec3aa1bc9b1d4e4c3ee66aec93&chksm=ebb07098dcc7f98ecd8b54c4dcc4c365e527000ad763776880d17f42eed74334e891c7ff9bbc&scene=21#wechat_redirect)
[版本动态 | 数据质量管理平台 Qualitis 0.9.0 版本发布](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488169&idx=1&sn=ee71415f27f662f0db23b173281502f1&chksm=ebb071cedcc7f8d85142513f8f4628ad8b117d64fea5e0b9a8b48f28a507d23bfdecb3ad16cb&scene=21#wechat_redirect)
[版本动态 | DataSphereStudio 1.0.1版本发布](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488106&idx=1&sn=5b98bdc9fe1fd11e01616761433545c7&chksm=ebb0710ddcc7f81bdc49c26184f41150303368b0f32de386dea85acadb044a7caea208acd49d&scene=21#wechat_redirect)
[WeDataSphere 入门指南](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247487968&idx=1&sn=e8210d2aca97a776a305842dc8162046&chksm=ebb07287dcc7fb918a4176e0b41e0d210656a5a87938127e76a383e89ff58dfc57a5188ab97e&scene=21#wechat_redirect)
如何成为社区贡献者
1 ► 官方文档贡献。发现文档的不足、优化文档,持续更新文档等方式参与社区贡献。通过文档贡献,让开发者熟悉如何提交PR和真正参与到社区的建设。参考攻略:[保姆级教程:如何成为Apache Linkis文档贡献者](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488838&idx=1&sn=3599cbb009751af44ba46720b0b60cf7&chksm=ebb07621dcc7ff37405c5c7ab36193c44ba543d4854b01a23cbc66a12440472a3a0adbc85c5b&scene=21#wechat_redirect)
2 ► 代码贡献。我们梳理了社区中简单并且容易入门的的任务,非常适合新人做代码贡献。请查阅新手任务列表:https://github.com/apache/incubator-linkis/issues/1161
3 ► 内容贡献:发布WeDataSphere开源组件相关的内容,包括但不限于安装部署教程、使用经验、案例实践等,形式不限,请投稿给小助手。例如:
* [技术干货 | Linkis实践:新引擎实现流程解析](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488722&idx=1&sn=6069ac14a2e0ec6f09acb8c8a471914f&chksm=ebb077b5dcc7fea3fcb2df95de0b3a99ecf1f73a86b8c036f1c36c17cce30c1d36b38866fec0&scene=21#wechat_redirect)
* [技术干货 | Prophecis保姆级部署教程](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488695&idx=1&sn=4020e1bccb565d518c0731b26b9a76ac&chksm=ebb077d0dcc7fec65c3052051f3a7d6d51b160fa82b5b89c06e1e0180080bb85949683f31a32&scene=21#wechat_redirect)
* [社区开发者专栏 | MariaCarrie:Linkis1.0.2安装及使用指南](http://mp.weixin.qq.com/s?__biz=MzI4MDkxNzUxMg==&mid=2247488005&idx=1&sn=df78dfb77f475c2d1ef7ee69568db5c7&chksm=ebb07162dcc7f8749a421038dd51abd7befb08aba8354846d87c61982db6a1ba520d99fd391b&scene=21#wechat_redirect)
4 ► 社区答疑:积极在社区中进行答疑、分享技术、帮助开发者解决问题等;
5 ► 其他:积极参与社区活动、成为社区志愿者、帮助社区宣传、为社区发展提供有效建议等














 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









