










背景介绍
Linkis是一款优秀的计算中间件,他对应用层屏蔽了复杂的底层计算引擎和存储方案,让大数据变得更加简单易用,同时也让运维变得更加方便。我们的平台很早就部署了WDS全家桶给业务用户和数据分析用户使用。近段时间,我们也调研和实现了hudi作为我们数据湖落地的方案,他帮助我们解决了在hdfs上进行实时upsert的问题,让我们能够完成诸如实时ETL,实时对账等项目。hudi作为一个数据湖的实现,我觉得他也是一种数据存储方案,所以我也希望它能够由Linkis来进行管理,这样我们的平台就可以统一起来对外提供能力。因此我这边做了一个Linkis和Hudi的结合和使用的分享。
1.环境版本介绍
1.1 环境是基于aws搭建,组件版本如下
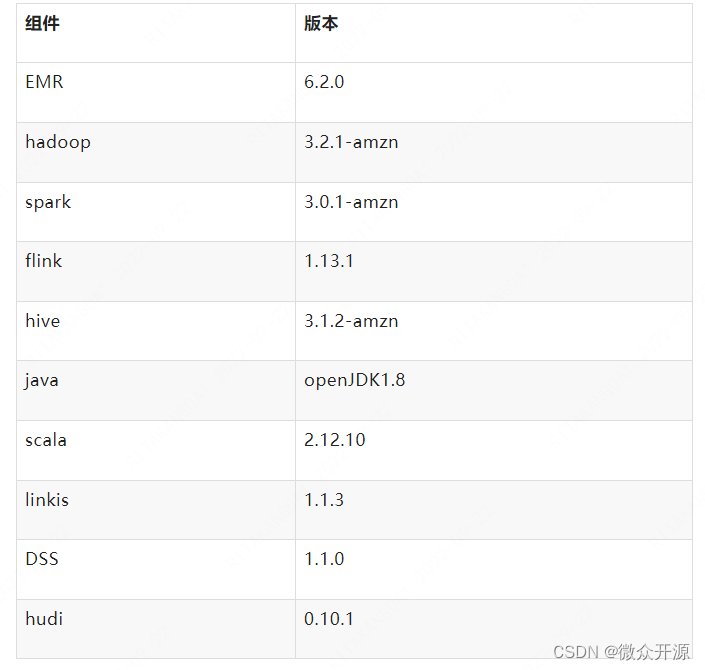
1.2 版本适配的操作
1.21 linkis需要按照hadoop,spark,flink,hive,scala等版本进行适配编译。适配编译已经有很多的介绍文章了,这里就不赘述了。
1.22 DSS可以直接使用,也可以升级他的scala版本到2.12,和Linkis保持一致。
1.23 hudi版本建议选择0.10.1或者0.11.1,因为0.10.0和0.11.0都有一些bug。另外0.11.x提供了bucket index功能,功能强大,如果是spark2.4.x或者3.1以上的spark,建议升级到0.11.1。我们的spark环境是3.0.1,0.11.1的hudi不能适配,退而求其次选择了0.10.1
1.24 hudi需要自己按照组件版本进行编译,一般来说,编译的命令如下
mvn clean package -Dmaven.test.skip=true -Dspark3.0.x -Dscala-2.12 -Dcheckstyle.skip=true -Drat.skip=true
1.25 有两个坑需要注意,因为aws的spark是自己修改了代码的,所以如果您使用的是aws,需要将spark-sql的version,改成amzn的版本,如3.0.1-amzn-0,不然在使用spark读取hudi的时候有包冲突;第二个坑是jetty版本的冲突,可以将hudi中的jetty改为provided。
1.26 完成编译后,我们可以得到三个bundle jar包,hudi-spark-bundle.jar,hudi-mr-bundle.jar, hudi-flink-bundle.jar,这三个jar分别是用于spark、hive和presto、flink的插件包。
2.整体架构介绍
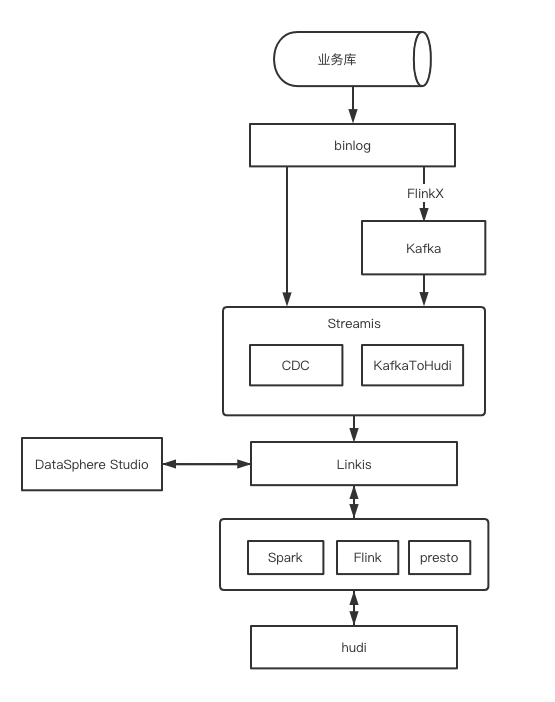
根据架构图所示,我们可以看到,业务库的binlog可以通过CDC直接到Hudi或者先经过Kafka再到Hudi。CDC和KafkaToHudi的应用使用Streamis进行提交,Streamis再通过Linkis将任务提交给Flink执行,这样用户的业务表就可以近实时地同步到我们的hudi表中。用户使用DSS进行查询,也是通过Linkis的Spark引擎访问hudi。
3.Linkis引入Hudi(Flink和Spark引擎)
3.1 Spark引擎
Spark引擎引入hudi的话,我们一般推荐直接将hudi-spark-bundle.jar放到${SPARK_HOME}/jars中,同时修改spark-defaut.conf,添加下面的配置
spark.serializer org.apache.spark.serializer.KryoSerializerspark.sql.extensions org.apache.spark.sql.hudi.HoodieSparkSessionExtension
同时也可以调大以下参数用来加大序列化的buffer内存。
spark.kryoserializer.buffer.max 256mspark.kryoserializer.buffer 256k
当然,也可以修改linkis启动spark引擎的方式,判断如果用户如果需要hudi的读取,就通过 --jars的方式引入hudi-spark-bundle.jar,并通过–conf的方式修改spark的序列化器参数。
3.2 Flink引擎
Flink引擎的话,就比较简单了,直接将hudi-flink-bundle.jar放置在${FLINK_HOME}/lib目录下即可,经过测试,hudi-flink-bundle.jar有shaded的方式,不会引入和其他connector冲突的包。
4.Linkis引入hudi之后的一些优点和应用介绍
4.1 实时ETL
将hudi引入到Linkis之后,我们可以直接通过streamis编写实时ETL任务,将业务表近实时地落到hudi,用户看到的最新的数据将是分钟级别的最新数据,而不是t-1或者几小时前的数据。而且这个实时ETL对集群压力也不大,如果是spark跑批,跑一天的数据,将会占据很大的集群资源,而且资源就在那一段时间被占用。
4.2 实时对账应用
我们以前的对账是在tidb上面,进行执行,tidb运维难度较大,而且商业版本价格较高,我们直接将数据导入到hudi之后,使用spark进行计算对账,也能打到分钟级别的延迟,同时运维成本降低。
4.3 实时BI
实时BI也是hudi的一个应用,通过Linkis的presto引擎查询hudi表,可以在visualis或tableau中实时刷新报表。presto的配置可以查看presto与hudi的连接。
4.4 实时分析
用户通过DSS直接查询hudi表,来进行取数以及实时分析,可以更快地反映出当天时刻的业务状况。
— END —
● 往期精选 ●
如何成为社区贡献者
1 ► 官方文档贡献。发现文档的不足、优化文档,持续更新文档等方式参与社区贡献。通过文档贡献,让开发者熟悉如何提交PR和真正参与到社区的建设。参考攻略:保姆级教程:如何成为Apache Linkis文档贡献者
2 ► 代码贡献。我们梳理了社区中简单并且容易入门的的任务,非常适合新人做代码贡献。请查阅新手任务列表:https://github.com/apache/incubator-linkis/issues/1161
3 ► 内容贡献:发布WeDataSphere开源组件相关的内容,包括但不限于安装部署教程、使用经验、案例实践等,形式不限,请投稿给小助手。例如:
4 ► 社区答疑:积极在社区中进行答疑、分享技术、帮助开发者解决问题等;
5 ► 其他:积极参与社区活动、成为社区志愿者、帮助社区宣传、为社区发展提供有效建议等















 5191
5191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









