





一 pandas文件读写
Pandas是Python的第三方库,提供高性能易用的数据类型和分析工具
import pandas as pd
Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
1.1读取文本文件
使用read_table来读取文本文件
pandas.read_table(filepath_or_buffer, sep=’t’, header=’infer’, names=None,
index_col=None, dtype=None, engine=None, nrows=None)
使用read_csv函数来读取csv文件
pandas.read_csv(filepath_or_buffer, sep=’t’, header=’infer’, names=None,
index_col=None, dtype=None, engine=None, nrows=None)
参数如下:
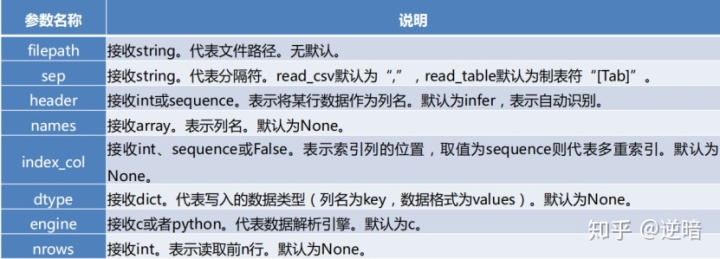
· read_table和read_csv函数中的sep参数是指定文本的分隔符的
o 如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片
· header参数是用来指定列名的,如果是None则会添加一个默认的列名
· encoding代表文件的编码格式
o 常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等
o 如果编码指定错误数据将无法读取,IPython解释器会报解析错误
1.2 文本文件存储
使用to_csv函数实现以csv格式存储
DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None,
header=True,
index=True,index_label=None,mode=’w’,encoding=None)
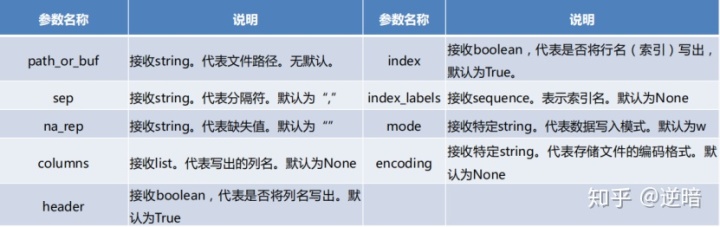
参数如下:
1.3 读取Excel文件
read_excel函数:读取“xls”“xlsx”两种Excel文件
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None,
dtype=None)
参数如下:

1.4 Excel文件存储
to_excel方法,其语法格式如下。
DataFrame.to_excel(excel_writer=None, sheetname=None’, na_rep=”,
header=True,
index=True, index_label=None, mode=’w’, encoding=None)
· 与to_csv方法的常用参数基本一致
o 区别之处在于指定存储文件的文件路径参数名称为excel_writer
o 增加sheetnames参数以指定存储的Excel sheet名,默认为sheet1
o 没有sep参数
二 Series
2.1 创建Series对象
类似字典key-value,在series中则为index的纵轴标度与对应的values
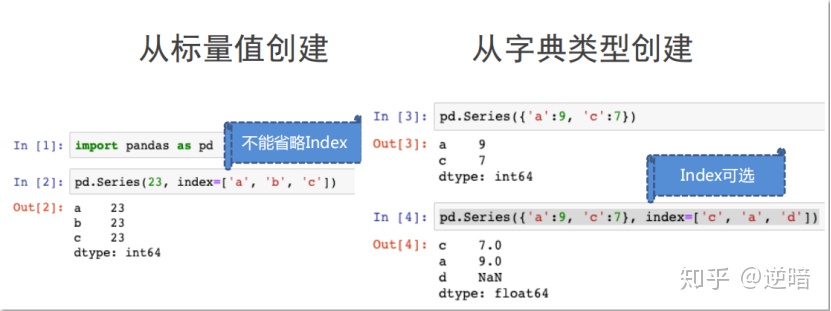
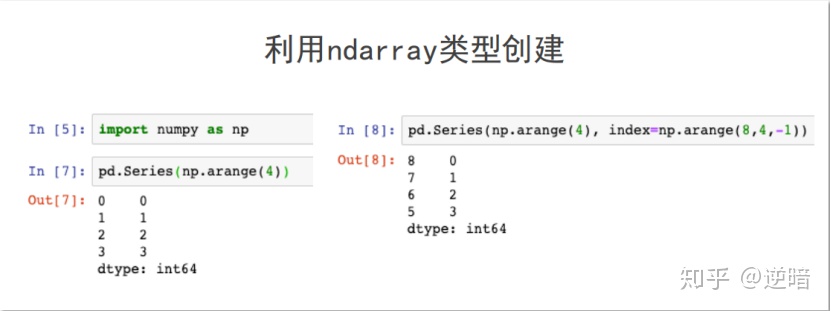
可以由如下类型创建:
· Python列表:index与列表元素个数一致
· 标量值:index表达Series类型的尺寸
· Python字典:键值对中的键是索引index从字典中进行选择操作
· ndarray:索引和数据都可用ndarray创建
· 其他函数:range等
2.2 Series基本操作
· Series类型包括index和values两部分
.index属性获得纵轴索引,.values获得数据值
· Series类型的操作类似ndarray类型
· Series类型的操作类似Python字典类型
index和value如下操作:
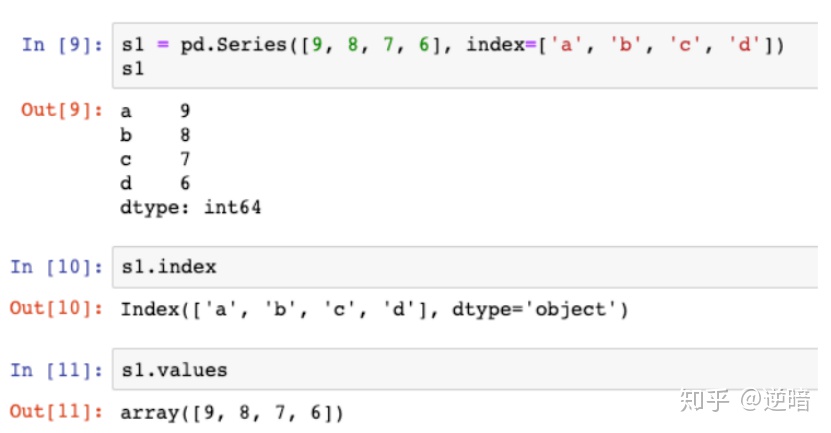

类似ndarray类型
索引方法相同,采用 [ ]
numpy中运算和操作可用于Series类型
可以通过自定义索引的列表进行切片
可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
类似Python字典类型

Series类型的对齐操作

2.3 Series小结

欢迎大家加入人工智能圈参与交流
人工智能学习圈 - 知乎www.zhihu.com















 4911
4911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









