





今年税务局对于研发部门提交的资料的要求越来越多了,比如新增的这个要求:按天提交研发材料领用清单。看了下会计部从公司数据库导出的领料清单,共34156条领用记录,分别在278天领取,我的心顿时拔凉拔凉的。如果要分成每日领料清单,那得准备278份Excel文件。在总表中按每天筛选,然后粘贴到新的表格,再添加“领料人”、“批准”等信息,一张表至少也得2分钟吧。掐指一算,278张表要556分钟,约9.3小时,要至少1个工作日。此刻,我的心是崩溃的。慢着...这只是我的额外工作呢,每天例行的事情还做不做了?想1个工作日搞定,纯粹是做梦,1天能挤出两小时都很不错了,估计只能冒着ICU的风险996了。最让人心惊肉跳的是,万一老板发疯,提交上去被打回要求改动,哪怕是一点点,都涉及到278次,有种ICU在招手的感觉......
画风一转,谁让我会编程呢?虽然面对老板的要求苦大仇深,灰头土脸,内心其实是偷着乐的。哪怕你要求改N次,我只需要改改源程序,小事儿。
物料总表和领料单模板分别长这样的:
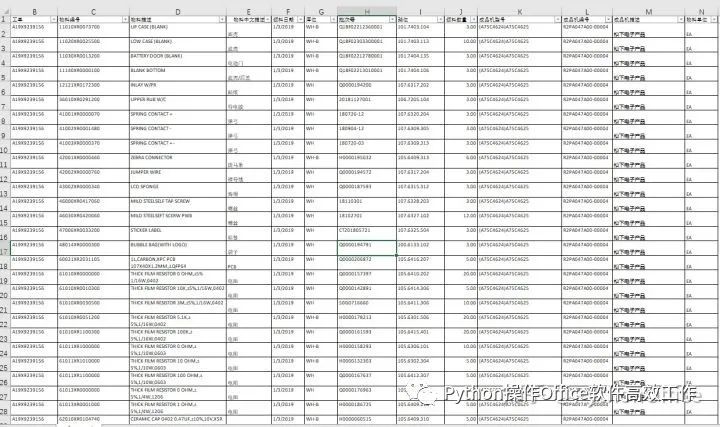

下面整理一下操作思路:
物料总表中有14个字段,其中11个是需要填到领料单中的,我们需要将这些数据先提取出来。
领料单中共16个字段,其中“域”、“生产线”、“工作中心”、“状态”4个字段都是固定的,另外“请求数量”与“批号批数量”相同。“项次”是每日领料笔数的编号,需要单独处理(比如领料20个,则就是1~20)。那物料总表的11个字段的数据中有10个需要填入领料单的对应的字段,剩下1个是“日期”,填入领料单表尾的“日期”位置(即上图的C9单元格)
由于每天领料笔数是不固定的,所以领料单表尾的“提出部门”、“货仓(发出部门)确认”等内容所在行也是不固定的,需要编程,根据每天具体的数据量来填写。
数据填写完成后,需要对单元格字体、字号、加粗、对齐、边框等设置,也需要编程来完成。
下面开始我们的程序,跟我飞~~
%%time>>Wall time: 56.3 s
先看用时,3万多行数据,用时1分32秒,还是蛮快的了。以上,我们先导入openpyxl模块中的加载工作簿程序load_workbook,然后读取工作簿“工单物料”,并存入wb中。我们可以用type(wb)查看它的类型。我们看到它是openpyxl.workbook.workbook.Workbook类型,即Excel“Workbook工作簿”。一个Excel工作簿里可能有多个工作表,那接下来还需要选取工作表,我们使用ws= wb.active获取工作簿中活动的工作表(活动工作表是你保存Excel文件时点选的那个工作表)。当然也可以直接指定工作表的名字来选取,如ws=wb['sheet1']。用type(ws)查看类型,知道它是openpyxl.worksheet.worksheet.Worksheet,即“Worksheet工作表”。
from >>openpyxl.worksheet.worksheet.Worksheet
然后我们建一个空字典data来存储数据。为什么要建字典呢?因为我们要按每天来提取数据,每天可能对应几十上百条数据,这些数据是按天来归类,那“天”就作为字典的“键”,数据就是这个键的“值”。像这种涉及到归类的数据,用字典来存储是一个很好的选择。然后我们使用for循环遍历这个工作表。第一行是标题,所以我们从第二行开始,最大一行+1结束(ws.max_row+1)。为什么要+1呢,是因为range()函数是取不到尾数的,比如range(1,3)只能取到“1,2”两个数(如下所示)。因此,如果不加1,那我们就得不到工作表最后一行的数据了。
for i >>1
>>2
然后将每行每个单元格的数据读取出来,使用类似这种move_order= ws['A' + str(row)].value。比如第二行,则相当于move_order= ws['A2'].value,即把工作表ws中单元格A2的值存进move_order中了。由于行row是整数,所以需要str(row)将数字转成字符串,才能跟字符串‘A’连接。这些数据中,factory,work_center,status是固定的,所以直接赋值即可,就不用从工作表里去读取了。一行数据读完后,将其存入列表info_list中。
我们要按领料日期来分类存储数据,比如要将1月3日这天的所领物料存为1组,那得先将1月3日设为字典的键。但1月3日不止领取1个物料,后面来的1月3日又来当“键”,则会跟之前的打架(因为字典的键必须是唯一的,一山不容二虎)。所以此处我们用了字典的setdefault函数(data.setdefault(date,[]))。它的意思是,假如新来一个日期,先看看字典里有没有这个日期,如果有,就不新建了,直接把这个日期对应的数据放在已存在的日期后面的列表里;如果没有,则新建。data[date].append(info_list)将单个物料信息的列表放入对应日期的大列表中。
我们可以看一下提取的数据,先看一下长度,即有多少天领取过物料,可见有278天。再用data.keyes()看一下这278天分别是哪些日期。datetime.date(2019, 1, 3)是日期格式,这个表示2019年1月3日。
len(data)再看看键值对,核实一下数据是否有问题。看起来很规整,让人放心。
for key,value 我们可以指定看一天的,比如1月3日的前面5条数据。此处导入datetime,是因为我们按日期选取,必须用到,不然会报错说“datetime”未定义。如下,可见1月3日前5条数据正是“工单物料”Excel表中的前5条数据。
import 为安全起见,再检查一下“工单物料”Excel表中最后一条数据是否被成功抓取。最后一条数据对应日期是12月28日,所以输入如下代码。回到原始表格对比,正是最后一条数据,欧耶!数据提取及检查到此完成。ヾ( ̄ー ̄)X(^▽^)ゞ
.date(数据提取完成后,就可以开始批量生成每日领料单了。先上程序,再慢慢解释。
%%time>>Wall time: 4min 34s
总耗时4分34秒,处理了3万4千条数据,278张工作表。比起纯手工打造所需的9小时,可谓分分钟完成,别告诉我效率不高^_^。首先,我们导入风格设置所需要的函数,其作用在注释部分已有说明,其实就是我们在Excel中经常进行的一些操作,比如设置字体、字号、是否加粗、单元格对齐、单元格加边框等等。然后使用Side函数定义了一个细线、黑色边框的风格,存入thin,通过type(thin)查看数据类型,显示为Side即边框风格类型。
type(thin)然后打开“领料单模板”Excel文件,准备将提取的数据写入其中。以模板为基础来写入数据,主要是用到了模板中的表头,因为每个表的表头都是一样的,这样就省略了用程序去处理表头的麻烦。先用ws_new = wb_day.copy_worksheet(ws_day)复制模板中的工作表,并生成新的工作表,新的工作表名使用日期ws_new.title=str(date)[-5:] ,即只取年月日的最后5位,比如取2019-01-03中的"01-03"。因为是从模板中的第四行开始写,所以定义了一个计数i=4,以便后面写入各行的时候调用。由于需要对当天领取的物料进行编号,假设领取了20个物料,那编号就是1至20,所以定义了编号seq,初始值为1。然后遍历每天领取的物料列表,逐个写入每行。如果当天领取了20个物料,则大列表中将有像如下这样的20个小嵌套列表:
['AAA', 377355, 3, 'A19X9239156', 'QQ31', 'Complete', 'WH-B', 'EA', '11010XR0073700', '101.7403.104', 'Q18F02212360001', 3, '(A75C4624)A75C4625', '面壳']
模板中共有16列数据,其中第三列不需要填入数据,所以只需要写入15个数据,找好对应关系书写程序,每一个都是一样的处理方式。其中第4列和14列是物料的数量,由于系统有误,有些本应该是整数的变成了小数,比如10.23个电阻。这肯定是不符合常识的,所以我们先对数据进行了处理再写入,通过split(".")[0]将小数点后的直接砍掉了。
看一下split函数的作用,先将数值“10.23”通过str函数转换成字符串,然后用split函数按照字符“.”来分段。输出的将是一个分好段的列表['10', '23'],再取其中第一个,就是“10”了,这样就成功地将小数点后的砍掉了。
= 随后,使用ws_new.row_dimensions[i].height将指定行的行高进行调整,方便打印出来有足够的地方签字。此时写好的数据都是模板中的默认字体、字号,边框也没有,可以说是一片原始荒芜。那接下来我们就要进行一系列美化啦。使用for循环遍历每个单元格(表头及表尾除外),然后设定字号、边框、对齐方式。对齐方式中的shrink_to_fit = True对应到Excel中就是“缩小字体填充(K)”功能。这样一个工作表就处理完了,然后再接着处理后续的277张表,步骤完全一样,全部完成后,保存数据。此刻,终于大功告成!看一下这漂亮的结果,是不是很舒畅啊?热烈表扬一下Python同学!
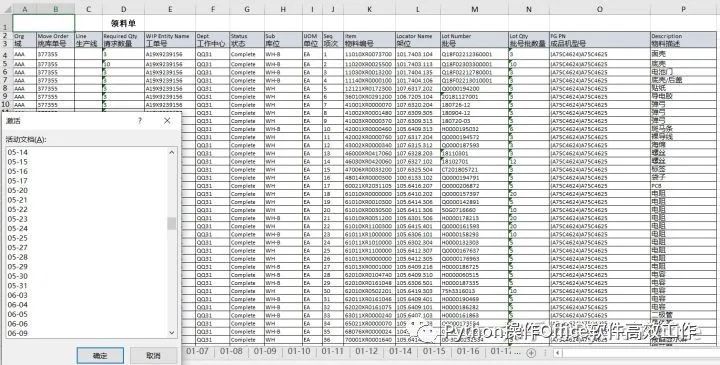
所有源代码和说明都在Jupyter notebook上完成,所用到的代码及Excel 资料已上传GitHub及百度网盘, 欢迎Fork或下载到本地随意玩。。。转载请注明出处,谢谢。
GitHub链接:https://github.com/weidylan/Office_Automation_by_Using_Python
百度网盘:链接: pan.baidu.com/s/1JjW_ke 提取码: z8nk
微信公众号:Python操作Office软件高效工作
知乎专栏:Python操作Office软件高效工作















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









