





Kafka系列文章之Kafka是什么?
前言
如果有幸目睹过系统从零到一的演变过程,大家估计都会有一种感叹,就是随着业务复杂度和流量的不断上升,系统变得越来越难以维护,面对高额的维护成本,攻城师们不得不对现有架构进行改造升级,以便使得系统更适合当下业务的发展。
说到架构改造升级,那到底该怎么改造呢?从哪里入手比较合适呢?这是一个比较大的话题,一两句话没办法讲述清楚,但是有一个出发点肯定是没有错的,就是为了更好的适应业务的发展需要进行必要的改造。
假设几个场景,场景一:用户 A 刷了微博,可能对某类博主比较感兴趣,为了让用户 A 看到更多可能感兴趣的人,该怎么做呢?场景二:用户 A 修改了年龄,搜索部门为了给其推荐可能感兴趣的商品,需要实时知道用户修改年龄的动作,采用何种方式来降低用户部门和搜索部门的耦合程度呢?场景三:京东 618 当天,大佬们想要看到实时成交总额,但又不能影响业务正常运行,又该怎么做呢?从以上几个例子可以看出,为了使得消息传递实时(说一下作者对实时的理解:在用户能接受的时间范围内得到想要的结果就是实时),降低业务部门的耦合度,需要有一个“中介”从中传递从而达到目的。
(本文来自公众号:z小赵)
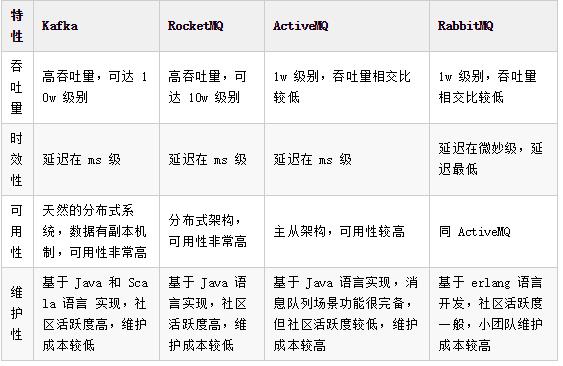
各消息队列对比
主流消息队列特性对比如下
Kafka 是什么?
Kafka 是一个分布式的、高吞吐量的、可持久性的、自动负载均衡的消息队列,同时 Kafka 从一定意义上来说具有横向易扩展性,通过 Kafka 也可以降低系统间的耦合度。
Kafka 消息队列中的消息生产消费模型是什么样的,即消息从何处来,又被送往何处去?
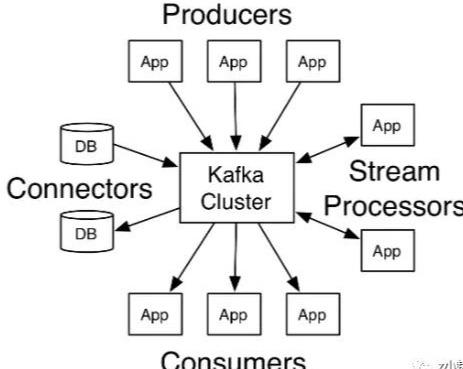
从上图可以看出,消息的产生可以是 APP 应用、DB 等等渠道,从各渠道产生的消息交给 Kafka Cluster,然后在通过计算将结果送到 DB、APP 等应用中。其实说白了就是一个典型的生产者消费者模型的具体应用。
Kafka 整体架构图
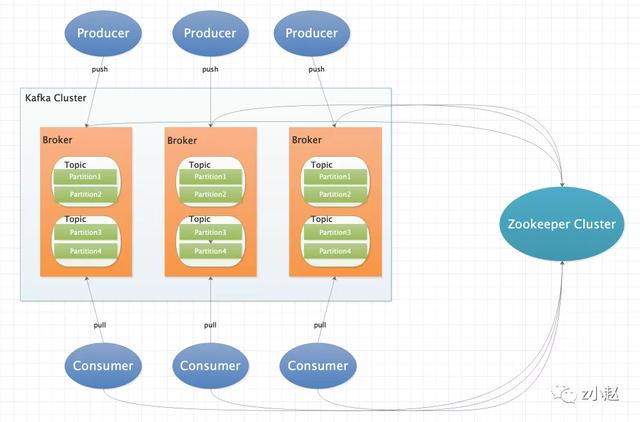
整体架构图
相关组件介绍
- Producer
消息发布者;即主要作用是生产数据,并将产生的数据推送给 Kafka 集群。
- Consumer
消息消费者;即主要作用是 kafka 集群中的消息,并将处理结果推送到下游或者是写入 DB 资源等。
- Zookeeper Cluster
存储 Kafka 集群的元数据信息,比如记录注册的 Broker 列表,topic 元数据信息,partition 元数据信息等等。
- Broker
Kafka 集群由多台服务器构成,每台服务器称之为一个 Broker 节点。
- Topic
主题,表示一类消息,consumer 通过订阅 Topic 来消费消息,一个 Broker 节点可以有多个 Topic,每个 Topic 又包含 N 个 partition(分区或者分片)。
- Partition
partition 是一个有序且不可变的消息序列,它是以 append log 文件形式存储的,partition 用于存放 Producer 生产的消息,然后 Consumer 消费 partition 上的消息,每个 partition 只能被一个 Consumer 消费。partition 还有副本的概念,后面文章来详细介绍。
总结
本篇文章主要介绍了 Kafka 是什么,Kafka 的整体架构及各组件组成;为了让大家更容易理解和接受,部分概念没有完全展开,在后续的文章中我们会一一来详细介绍,请大家放心;基本概念讲完了,下篇文章我们来实操搭建一个 Kafka 集群玩玩。
Kafka系列文章之安装测试
前言
上篇文章讲解了 Kafka 的基础概念和架构,了解了基本概念之后,必须得实践一波了,所谓“实践才是检验真理的唯一办法”,后续系列关于 Kafka 的文章都以 kafka_2.11-0.9.0.0 为例;另外为了让大家快速入门,本文只提供单机版的安装实战教程,如果有想尝试集群方案的,后面在出一篇集群安装的教程,废话不多说了,直接开干。
安装
1. 下载
版本号:kafka_2.11-0.9.0.0
下载地址:http://kafka.apache.org/downloads
2. 安装
# 安装目录$ pwd/Users/my/software/study# 减压$ sudo tar -zxvf kafka_2.11-0.9.0.0.tgz# 重命名$ sudo mv kafka_2.11-0.9.0.0.tgz kafka-0.9# 查看目录结构$ cd kafka-0.9 && lsLICENSE NOTICE bin config libs site-docs# 目录结构介绍:# bin: 存放kafka 客户端和服务端的执行脚本# config:存放kafka的一些配置文件# libs:存放kafka运行的的jar包# site-docs:存放kafka的配置文档说明# 配置环境变量,方便在任意目录下运行kafka命令# 博主使用的Mac,所以配置在了 ~/.bash_profile文件中,# Linux中则配置在 ~/.bashrc 或者 ~/.zshrc文件中$ vim ~/.bash_profileexport KAFKA_HOME=/Users/haikuan1/software/study/kafka-0.9export PATH=$PATH:$JAVA_HOME:$KAFKA_HOME/bin# 使得环境变量生效$ source ~/.bash_profile3.运行
3.1 启动 zookeeper
# 启动zookeeper,因为kafka的元数据需要保存到zookeeper中$ bin/zookeeper-server-start.sh config/zookeeper.properties# 若出现如下信息,则证明zookeeper启动成功了[2020-04-25 16:23:44,493] INFO Server environment:user.dir=/Users/haikuan1/software/study/kafka-0.10 (org.apache.zookeeper.server.ZooKeeperServer)[2020-04-25 16:23:44,505] INFO tickTime set to 3000 (org.apache.zookeeper.server.ZooKeeperServer)[2020-04-25 16:23:44,505] INFO minSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)[2020-04-25 16:23:44,505] INFO maxSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)[2020-04-25 16:23:44,548] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)3.2 启动 Kafka server
# 以守护进程的方式启动kafka服务端,去掉 -daemon 参数则关闭当前窗口服务端自动退出$ bin/kafka-server-start.sh -daemon config/server.properties3.3 kafka 基础命令使用
# 1. 创建一个topic# --replication-factor:指定副本个数# --partition:指定partition个数# --topic:指定topic的名字$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic mytopic# 2. 查看创建成功的topic$ kafka-topics.sh --list --zookeeper localhost:2181# 3. 创建生产者和消费者# 3.1 启动kafka消费端# --from-beginning:从头开始消费,该特性也表明kafka消息具有持久性$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic --from-beginning# 3.2 启动kafka生产端# --broker-list:当前的Broker列表,即提供服务的列表$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic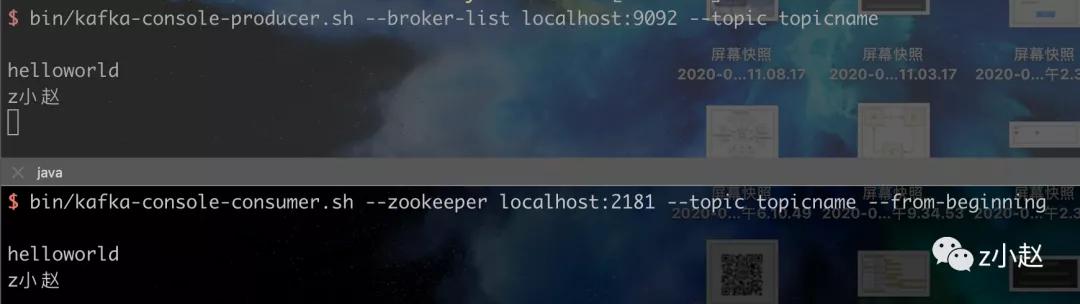
生产者消费者效果图
4.使用 Java 连接 kafka 进行测试
4.1 创建一个 maven 工程,引入如下 pom 依赖
org.apache.kafka kafka-clients 0.9.0.0org.apache.kafka kafka_2.11 0.9.0.04.2 消费者端代码
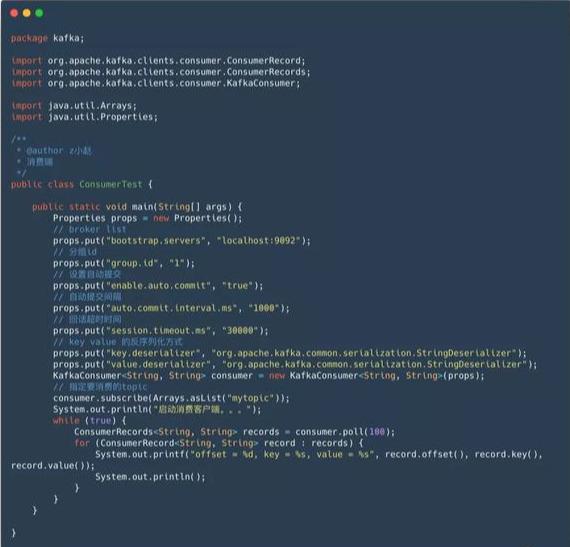
消费者端代码
4.3 生产者端代码
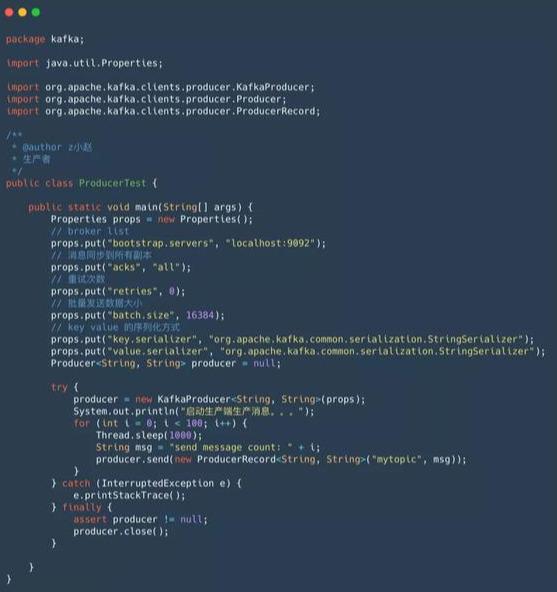
生产者端代码
4.4 消费者端效果图
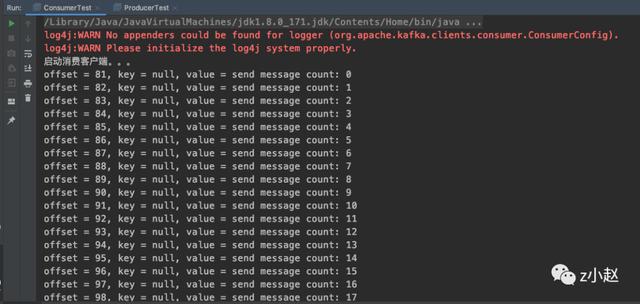
5.总结
本文介绍了 kafka 单机版安装及简单命令使用,然后使用 Java 实现了生产者和消费者的简单功能,虽然内容可能比较简单,但还是强烈建议大家手动去实践一下,从而对 kafka 的架构有一个更深入的理解。下篇文章我们来介绍一下 Kafka 消息发送及其背后的原理,敬请期待。
一条消息如何被存储到Broker上
前言
经过上篇文章的简单实战之后,今天来聊聊生产者将消息从客户端发送到 Broker 上背后发生了哪些故事,看不看由你,但是我保证可以本篇文章你一定可以学到应用背后的一些实质东西。
本文我们从以下 4 个方面来探讨下一条消息如何被准确的发送到 Broker 的 partition 上。
1. 客户端组件
2. 客户端缓存存储模型
3. 确定消息的 partition 位置
4. 发送线程的工作原理
客户端组件
- KafkaProducer:
KafkaProducer 是一个生产者客户端的进程,通过该对象启动生产者来发送消息。
- RecordAccumulator:
RecordAccumulator 是一个记录收集器,用于收集客户端发送的消息,并将收集到的消息暂存到客户端缓存中。
- Sender:
Sender 是一个发送线程,负责读取记录收集器中缓存的批量消息,经过一些中间转换操作,将要发送的数据准备好,然后交由 Selector 进行网络传输。
- Selector:
Selector 是一个选择器,用于处理网络连接和读写处理,使用网络连接处理客户端上的网络请求。
通过使用以上四大组件即可完成客户端消息的发送工作。消息在网络中传输的方式只能通过二级制的方式,所以首先需要将消息序列化为二进制形式缓存在客户端,kafka 使用了双端队列的方式将消息缓存起来,然后使用发送线程(Sender)读取队列中的消息交给 Selector 进行网络传输发送给服务端(Broker)
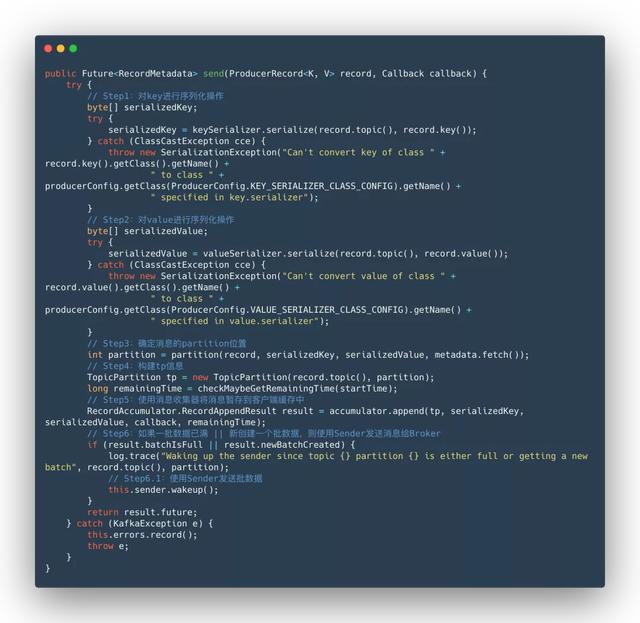
主流程
以上为发送消息的主流程,附上部分源码供大家参考,接下来分析下几个非常重要流程的具体实现原理。
客户端缓存存储模型
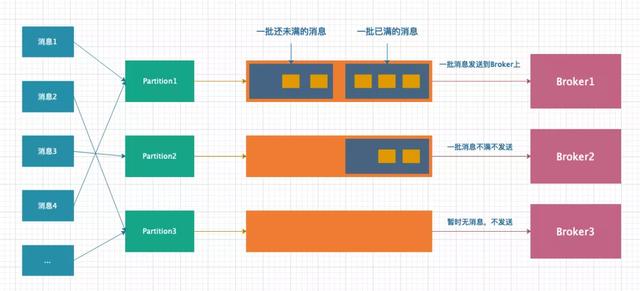
客户端缓存模型
从上图可以看出,一条消息首先需要确定要被存储到那个 partition 对应的双端队列上;其次,存储消息的双端队列是以批的维度存储的,即 N 条消息组成一批,一批消息最多存储 N 条,超过后则新建一个组来存储新消息;其次,新来的消息总是从左侧写入,即越靠左侧的消息产生的时间越晚;最后,只有当一批消息凑够 N 条后才会发送给 Broker,否则不会发送到 Broker 上。
了解了客户端存储模型后,来探讨下确定消息的 partition(分区)位置?
确定消息的 partition 位置
消息可分为两种,一种是指定了 key 的消息,一种是没有指定 key 的消息。
对于指定了 key 的消息,partition 位置的计算方式为:Utils.murmur2(key) % numPartitions,即先对 key 进行哈希计算,然后在于 partition 个数求余,从而得到该条消息应该被存储在哪个 partition 上。
对于没有指定 key 的消息,partition 位置的计算方式为:采用 round-robin 方式确定 partition 位置,即采用轮询的方式,平均的将消息分布到不同的 partition 上,从而避免某些 partition 数据量过大影响 Broker 和消费端性能。
注意
由于 partition 有主副的区分,此处参与计算的 partition 数量是当前有主 partition 的数量,即如果某个 partition 无主的时候,则此 partition 是不能够进行数据写入的。
稍微解释一下,主副 partition 的机制是为了提高 kafka 系统的容错性的,即当某个 Broker 意外宕机时,在此 Broker 上的主 partition 状态为不可读写时(只有主 partition 可对外提供读写服务,副 partition 只有数据备份的功能),kafka 会从主 partition 对应的 N 个副 partition 中挑选一个,并将其状态改为主 partition,从而继续对外提供读写操作。
消息被确定分配到某个 partition 对应记录收集器(即双端队列)后,接下来,发送线程(Sender)从记录收集器中收集满足条件的批数据发送给 Broker,那么发送线程是如何收集满足条件的批数据的?批数据是按照 partition 维度发送的还是按照 Broker 维度发送数据的?
发送线程的工作原理
Sender 线程的主要工作是收集满足条件的批数据,何为满足条件的批数据?缓存数据是以批维度存储的,当一批数据量达到指定的 N 条时,就满足发送给 Broker 的条件了。
partition 维度和 Broker 维度发送消息模型对比。
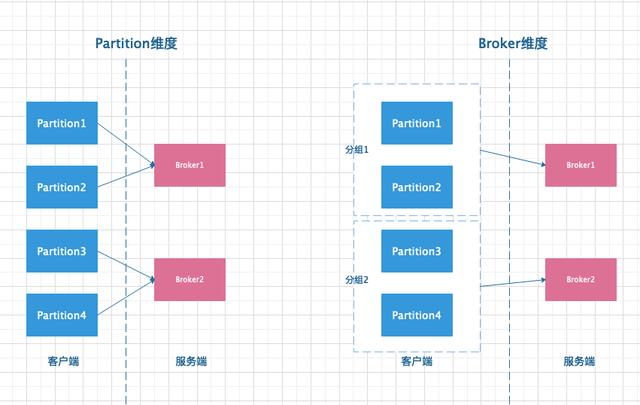
模型对比图
从图中可以看出,左侧按照 partition 维度发送消息,每个 partition 都需要和 Broker 建连,总共发生了四次网络连接。而右侧将分布在同一个 Broker 的 partition 按组聚合后在与 Broker 建连,只需要两次网络连接即可。所以 Kafka 选择右侧的方式。
Sender 的主要工作
第一步:扫描记录收集器中满足条件的批数据,然后将 partition -> 批数据映射转换成 BrokerId -> N 批数据的映射。第二步:Sender 线程会为每个 BrokerId 创建一个客户端请求,然后将请求交给 NetWorkClient,由 NetWrokClient 去真正发送网络请求到 Broker。
NetWorkClient 的工作内容
Sender 线程准备好要发送的数据后,交由 NetWorkClient 来进行网络相关操作。主要包括客户端与服务端的建连、发送客户端请求、接受服务端响应。完成如上一系列的工作主要由如下方法完成。
- reday()方法。从记录收集器获取准备完毕的节点,并连接所有准备好的节点。
- send()方法。为每个节点创建一个客户端请求,然后将请求暂时存到节点对应的 Channel(通道)中。
- poll()方法。该方法会真正轮询网络请求,发送请求给服务端节点和接受服务端的响应。
总结
以上,即为生产者客户端的一条消息从生产到发送到 Broker 上的全过程。现在是不是就很清晰了呢?也许有些朋友会比较疑惑它的网络请求模型是什么样的,作者就猜你会你会问,下一篇我们就来扒开它的神秘面纱看看其究竟是怎么实现的,敬请期待。(本文来自公众号:z小赵)
感谢大家支持,多多转发关注不迷路~~~~~~















 1145
1145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









