





上一次介绍了决策树的ID3算法和CART算法 决策树与随机森林(2)—— 用R种树和画树,想详细了解算法具体原理,请看 决策树与随机森林(1)—— 决策树算法数学推导与实例演练,这次我们来聊一下决策树的剪枝和
C4.5
算法
。
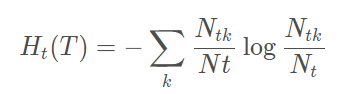 这个代表了该叶节点 t 的混乱程度,极端来看,如果该叶节点 t 只有一个分类 k
n
时,
该节点的 Ht(T) 最终会等于0,那么可以说,Ht(T) 接代表了该叶节点对所属路径数据分类的彻底性。
考虑到所有叶节点里面每个叶节点的样例个数不同,所以,我们得到了决策树损失函数的前体:
这个代表了该叶节点 t 的混乱程度,极端来看,如果该叶节点 t 只有一个分类 k
n
时,
该节点的 Ht(T) 最终会等于0,那么可以说,Ht(T) 接代表了该叶节点对所属路径数据分类的彻底性。
考虑到所有叶节点里面每个叶节点的样例个数不同,所以,我们得到了决策树损失函数的前体:
 大家可以尝试下其它参数设置,但个人认为预剪枝一般用的不多,还是后剪枝用的稍微多一些,通过错误率和复杂度来对模型进行剪枝。
大家可以尝试下其它参数设置,但个人认为预剪枝一般用的不多,还是后剪枝用的稍微多一些,通过错误率和复杂度来对模型进行剪枝。
我对
We
ka_
contro
l 的理解是这些参数属于 J48 的剪枝参数,如 U,M 属于预剪枝设置,R 则属于后剪枝设置。
1.剪枝
以上是决策树的两个核心问题,其中第一个我们前两节已经说过,通过不同的算法可以找到最优划分属性。为什么要进行剪枝呢?可以换个问题,如何衡量一个模型的好与坏呢?简单来说,就是 该模型在验证数据集的准确性。对于决策树,我们希望每个叶子节点分的都是正确的答案,所以在不加限制的情况下, 决策树倾向于把每个叶子节点单纯化,那如何最单纯呢?极端情况下,就是每个叶子节点只有一个样本,那这样,这个模型在建模集的准确率就非常高了。但是,这又带来了一个问题——过拟合,这会导致该模型在建模集效果显著,但是验证集表现不佳,所以,这里引入了剪枝的概念,通过限制 复杂度参数(complexity parameter) , 删除明显不值得的分割,来防止模型的过拟合。1.到底由谁来做根节点和内部节点;
2.如何让决策树停止生长,防止过拟合。
接下来用数学推导一下上面的结论 (损失函数)我们先不考虑模型的泛化能力,那么得到一棵表现最优的树可以根据所有叶结点中的预测误差来衡量,即模型与训练数据的拟合程度。设树 T 的叶结点个数为 N,n 是树 T 的一个叶结点,该叶结点有 Nt个样本,其中 k 类的样本点有 N tk 个,K=1,2,3......K, K 为 样本空间中的所属分类数量。 叶结点 t 上的熵 H t(T) 为
这个代表了该叶节点 t 的混乱程度,极端来看,如果该叶节点 t 只有一个分类 k
n
时,
该节点的 Ht(T) 最终会等于0,那么可以说,Ht(T) 接代表了该叶节点对所属路径数据分类的彻底性。
考虑到所有叶节点里面每个叶节点的样例个数不同,所以,我们得到了决策树损失函数的前体:
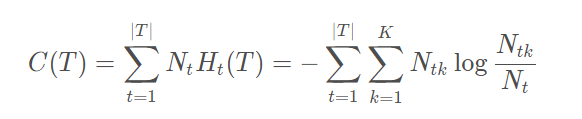
用 C(T) 来衡量模型对训练数据的整体测量误差。
但是,问题来了,如果仅仅用 C(T) 来作为优化目标函数,如上所述,该模型就会走向过拟合的结果。因为模型会倾向将每个分支划分到最细来使每一个叶节点的 H t (T) = 0,最终使得 C(T) 最小。为了避免过拟合,我们需要给优化目标函数增加一个正则惩罚项,正则项应该包含模型的复杂度信息,对于决策树来说,其叶节点的数量越多就越复杂,所以损失函数如下:
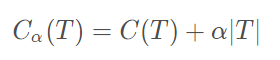
决策树的剪枝分为预剪枝和后剪枝 预剪枝:在构建决策树的过程中,提前停止 后剪枝:决策树构建好,才开始剪枝
预剪枝:
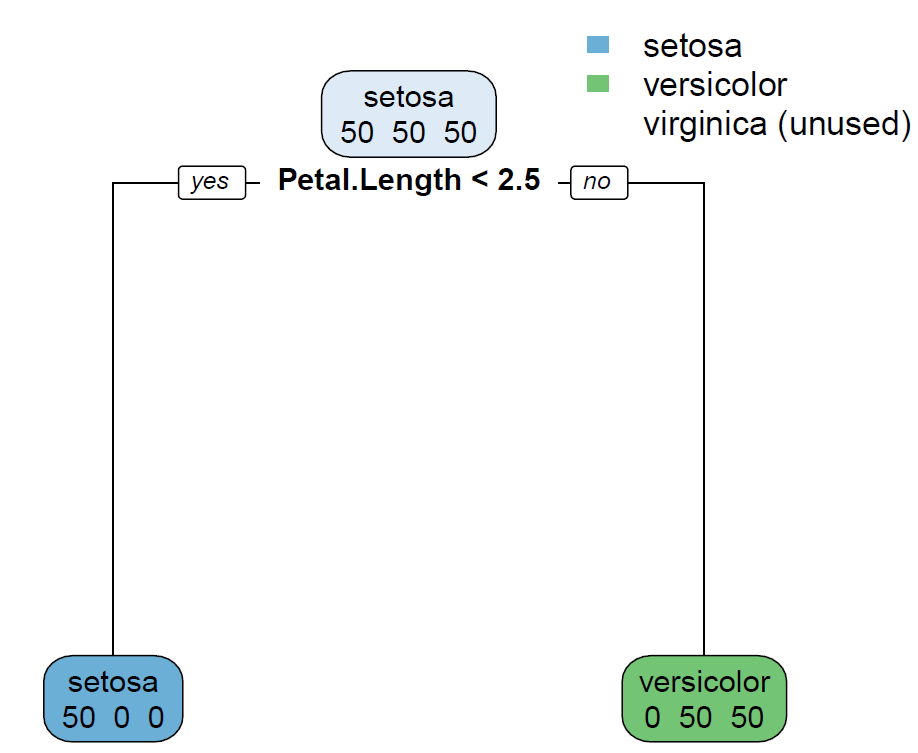
在 rpart 函数中,有个参数叫做 control,它可以控制 rpart 的各种细节参数,而预剪枝就是在这里设置的,比如我们可以规定 minsplit = 100,就是指 每个内部节点中所含样本最小数最小为100;也可以设置 minbucket = 50,就是指叶节点中所含样本最小数目为50,设置树的深度 maxdepth = 3 就是最大不超过3,设置复杂度 cp = 0.2; 如果这些条件没满足,那么决策树就是停止划分下去,这就是预剪枝。我们来构建一棵树 Tree1,不加预剪枝条件
library(rpart)library(rpart.plot)Tree1 <- rpart(formula = Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width, data = iris,method = 'class',parms = list(split='gini')) rpart.plot(Tree1,branch=1,type=2, fallen.leaves=T,cex=0.8,extra = 1)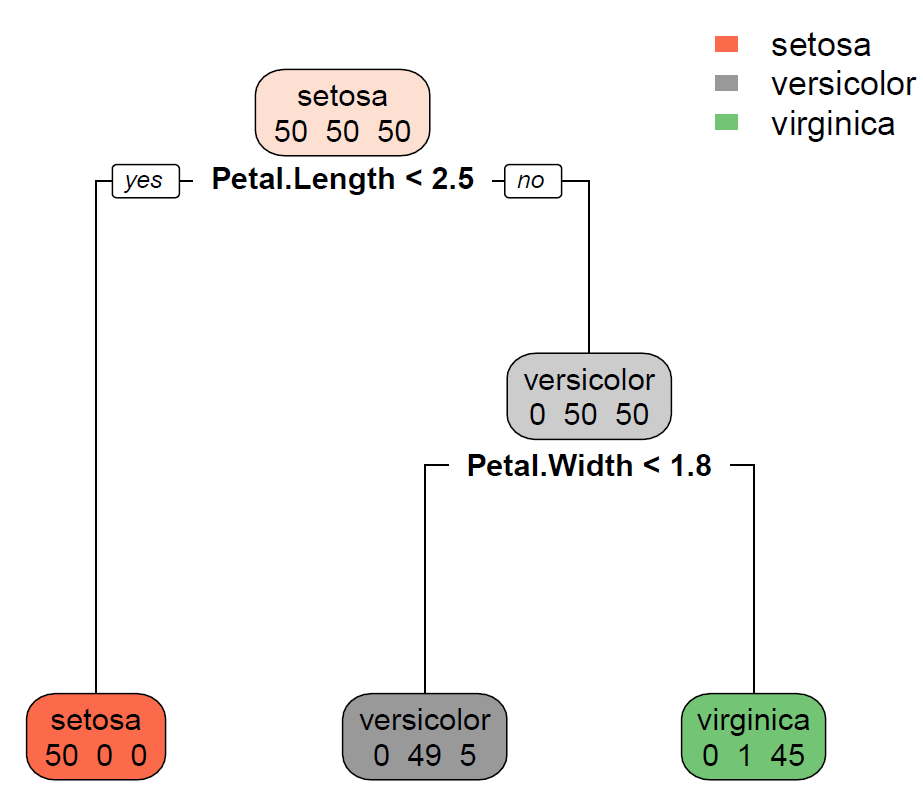
设置 minsplit= 150,限制内部节点即右边第一个分支的样本数量需要大于等于150个样本,明显不满足条件,所以被剪掉了
Tree2 <- rpart(formula = Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width, data = iris,method = 'class',parms = list(split='gini'), control = list(minsplit=150) )rpart.plot(Tree2,branch=1,type=2, fallen.leaves=T,cex=0.8,extra = 1)
设置 minbucket = 50,限制叶节点的样本数量最小为50个,从第一张图可以看出,第三个叶节点的样本数量才46个,不满足条件,所以被剪掉了
Tree3 <- rpart(formula = Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width, data = iris,method = 'class',parms = list(split='gini'), control = list(minbucket=50) )rpart.plot(Tree3,branch=1,type=2, fallen.leaves=T,cex=0.8,extra = 1)后剪枝:
对于 rpart 生成的结果,使用 prune 函数对其进行后剪枝, 一般选择最小交叉验证误差 xerror 对应的复杂度参数 cp 值,这种方法也叫做 最小代价复杂度剪枝法。为了构建更复杂的决策树,我们使用survival包中的lung数据集来进行构建树
library(survival)#为了调用lung数据集data 1:data$status datahead(data)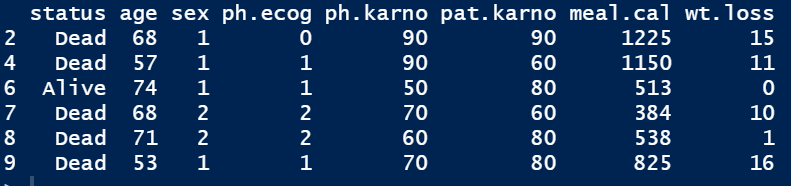
通过其它所有变量来预测病人的status:
Tree <- rpart(status~.,data,method = 'class',parms = list(split='gini'))rpart.plot(Tree,branch=1,type=0, fallen.leaves=T,cex=0.8,extra = 1)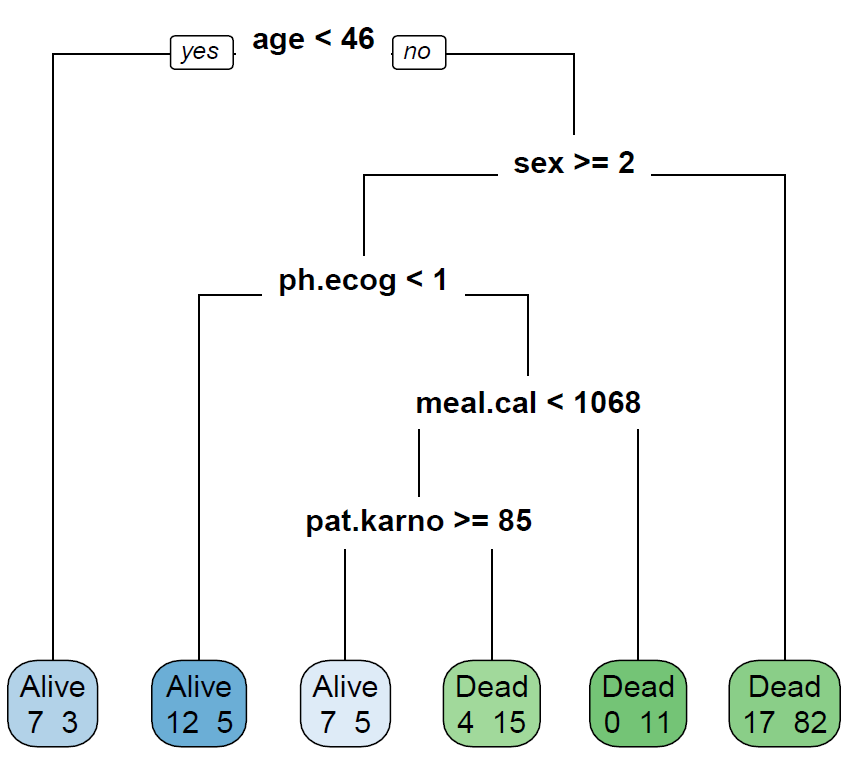
Tree$cptable #查看下10折交叉验证后的各种结果参数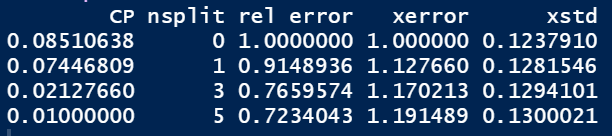
Tree2 $cptable[,rpart.plot(Tree2,branch=1,type=0, fallen.leaves=T,cex=0.8,extra = 1)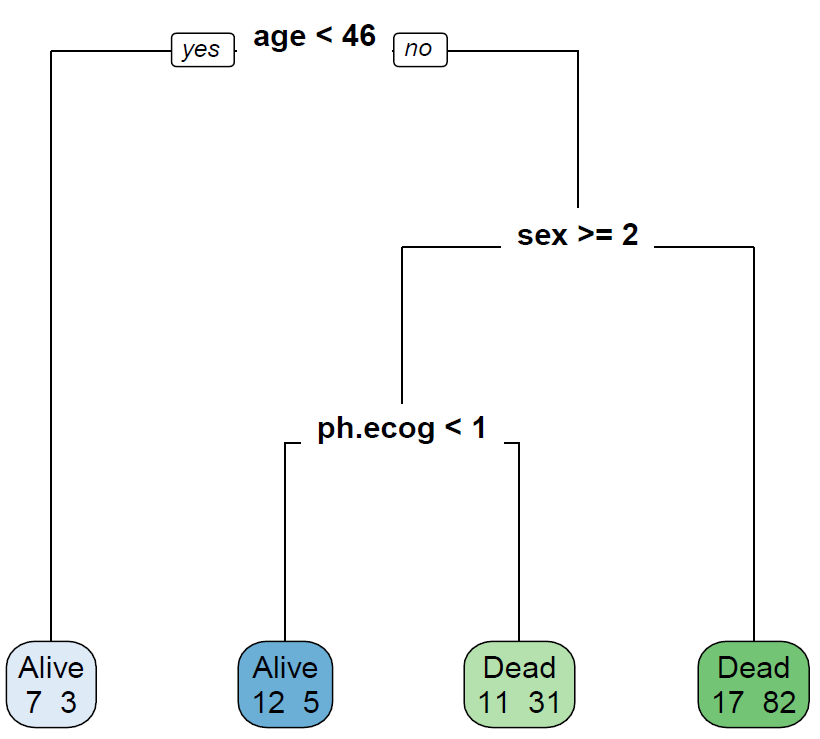
预剪枝和后剪枝的对比
后剪枝通常比预剪枝保留了更多的分支
后剪枝的欠拟合风险很小,泛化能力往往高于预剪枝决策树
后剪枝训练时间比未剪枝和预剪枝决策树要长很多
2.C4.5算法的实现
C4.5算法主要通过Rwake包的J48函数实现的,下面是J48函数的具体 参数解释 :J48(formula,data,subset,na.action,control=Weka_control(u=T,c=0.25,M=2,R=T,N=3,B=T),options=NULL)
| 参数 | 解释 |
| formula | y~x1+x2+x3/y~.(表示输入变量为除y的所有变量) |
| data | 训练数据集(数据框),用来对应formula的变量 |
| subset | 从data中选取子集建模 |
| na.action | 缺失值处理 |
| Weka_control | 控制 J48 的各种细节参数,需要输入一个列表格式的参数设置;control=Weka_control(u=T,c=0.25,M=2,R=T,N=3,B=T) |
| U | 默认为TRUE,表示不剪枝 |
| C | 对剪枝过程设置置信区间 |
| M | 表示叶节点的最小样本量,默认为2 |
| R | 按错误率降低剪枝法剪枝 |
| N | 当R=TRUE时,交叉验证的折叠次数,默认为3 |
| B | 表示是否建立二叉树,默认为TRUE |
简单构建一棵基于C4.5算法的树
#我们使用 mlbench 包中的 PimaIndiansDiabetes 数据集data("PimaIndiansDiabetes", package = "mlbench")head(PimaIndiansDiabetes)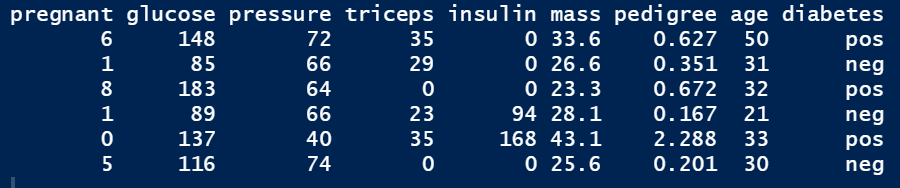
options(java.home='C:\\Program Files\\Java\\jdk1.8.0_131')#这里需要设置java,RWeka需要安装rjava包library(RWeka)Tree1 plot(Tree1)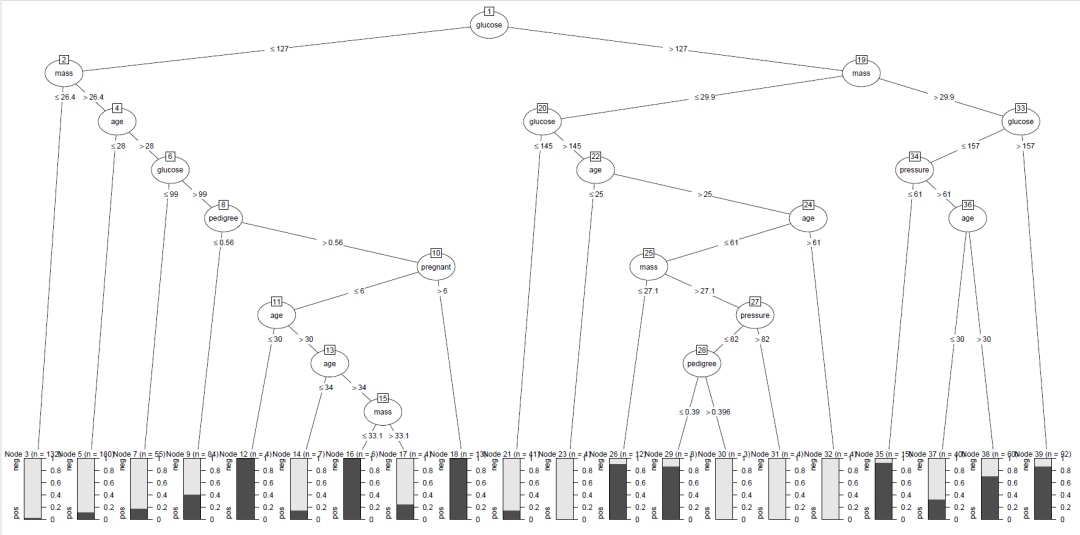
evaluate_Weka_classifier(Tree1,numFolds = 10,complexity = T,seed = 123)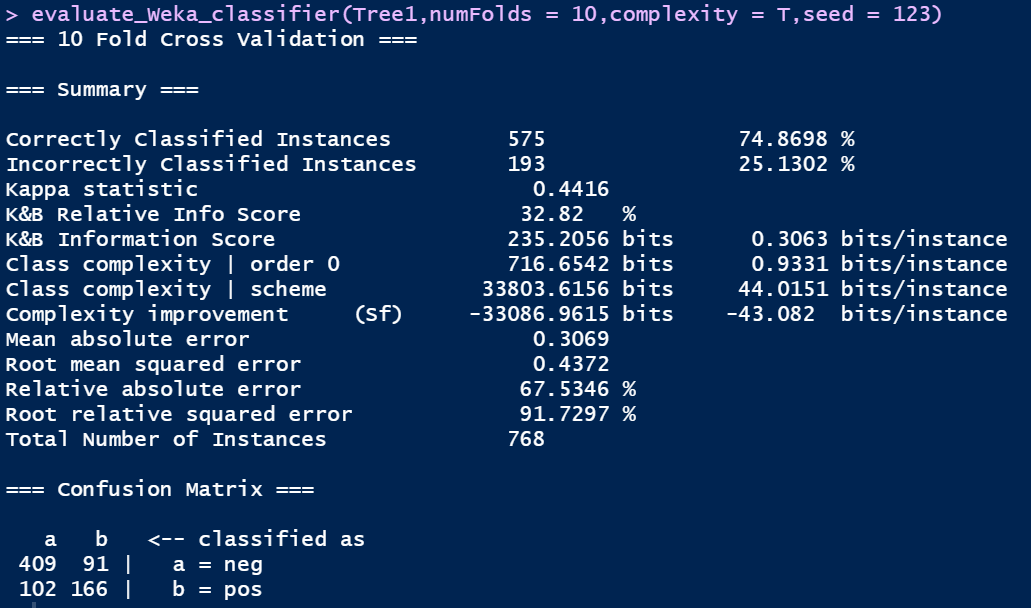
接下来在J48中的 Wake_control中设置剪枝参数:
Tree2 data = PimaIndiansDiabetes, control = Weka_control(M=10,R=T))#设计叶节点的最小样本量不能小于10,且按错误率降低剪枝法剪枝plot(Tree2)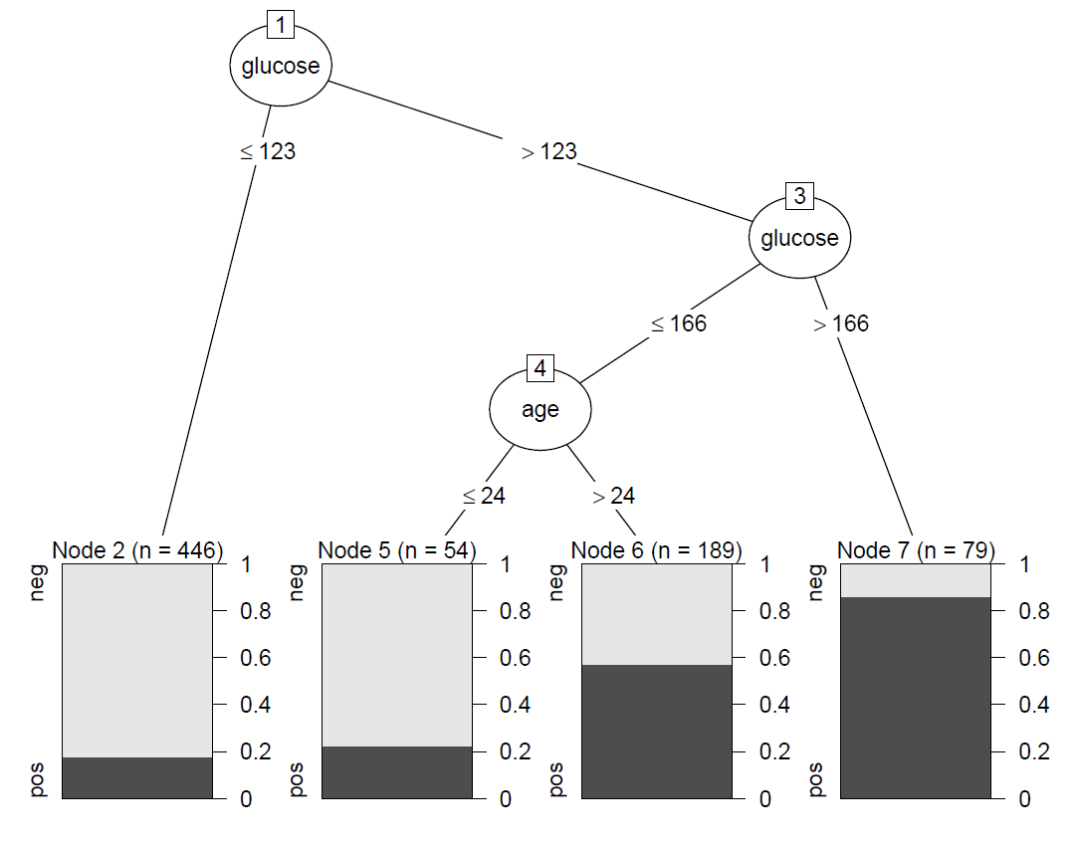
evaluate_Weka_classifier(Tree2,numFolds = 10,complexity = T,seed = 123)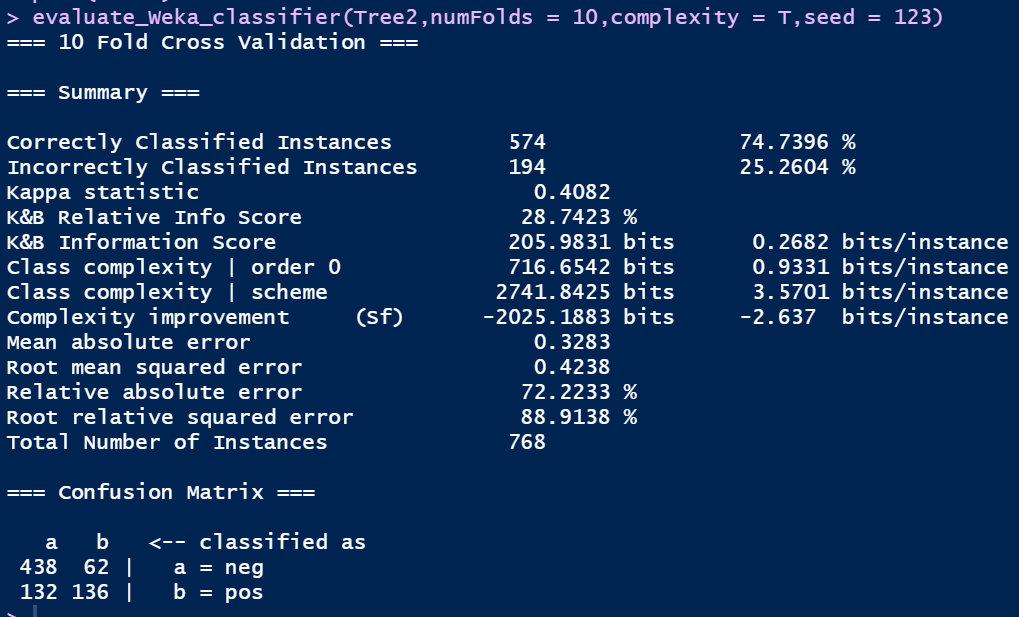















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









