





你在工作当中有遇到内存溢出问题吗?你是如何解决的?
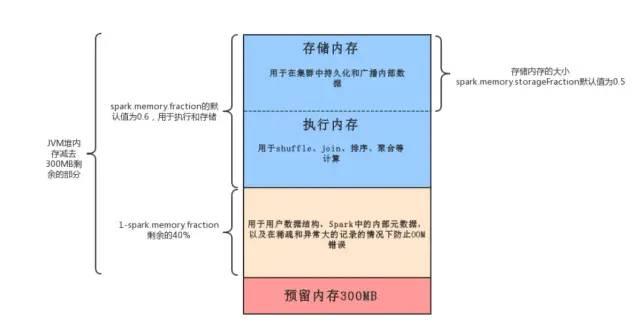
oom通常出现在execution内存中,因为storage这块内存在放满之后,会直接丢弃内存中旧的数据,对性能有点影响但不会导致oom。
一 OOM原因
- Driver 内存不足
driver端生成大对象
collect数据收集导致
- Executor 内存不足
map 类操作产生大量数据包括 map,flatMap,filter,mapPartitions 等
shuffle 后产生数据倾斜
二 Driver 内存不足
1.用户在Dirver端生成大对象,比如创建了一个大的集合数据结构
- 将大对象转换成Executor端加载,比如调用sc.textfile
- 评估大对象占用的内存,增加dirver-memory的值
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
2.collect
本身不建议将大的数据从executor端,collect回来。建议将driver端对collect回来的数据所作的操作,转换成executor端rdd操作
若无法避免,估算collect需要的内存,相应增加driver-memory的值
rdd = sc.parallelize(range(100))rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000)]).collect() # 内存溢出def func(x): print(x)rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000)]).foreach(func) # 分区输出三 Executor 内存不足
1.增加 Executor 内存
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).2.map过程产生大量对象导致内存溢出
这种溢出的原因是在单个map中产生了大量的对象导致的,例如:rdd.map(x=>for(i for(i
3.数据倾斜导致内存溢出
解决方案:Spark数据倾斜解决方案
4.coalesce调用导致内存溢出
因为hdfs中不适合存小问题,所以Spark计算后如果产生的文件太小,我们会调用coalesce合并文件再存入hdfs中。但是这会导致一个问题,例如在coalesce之前有100个文件,这也意味着能够有100个Task,现在调用coalesce(10),最后只产生10个文件,因为coalesce并不是shuffle操作,这意味着coalesce并不是按照我原本想的那样先执行100个Task,再将Task的执行结果合并成10个,而是从头到位只有10个Task在执行,原本100个文件是分开执行的,现在每个Task同时一次读取10个文件,使用的内存是原来的10倍,这导致了OOM。解决这个问题的方法是令程序按照我们想的先执行100个Task再将结果合并成10个文件,这个问题同样可以通过repartition解决,调用repartition(10),因为这就有一个shuffle的过程,shuffle前后是两个Stage,一个100个分区,一个是10个分区,就能按照我们的想法执行。
5.shuffle后内存溢出
shuffle内存溢出的情况可以说都是shuffle后,单个文件过大导致的。在Spark中,join,reduceByKey这一类型的过程,都会有shuffle的过程,在shuffle的使用,需要传入一个partitioner,大部分Spark中的shuffle操作,默认的partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) , spark.default.parallelism参数只对HashPartitioner有效,所以如果是别的Partitioner或者自己实现的Partitioner就不能使用spark.default.parallelism这个参数来控制shuffle的并发量了。如果是别的partitioner导致的shuffle内存溢出,就需要从partitioner的代码增加partitions的数量。
6.standalone 模式资源分配不均
在standalone的模式下如果配置了--total-executor-cores 和 --executor-memory 这两个参数,但是没有配置--executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。这种情况的解决方法就是同时配置--executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
7.在RDD中,共用对象能够减少OOM的情况
rdd.flatMap(x=>for(i for(i
这是因为每次("key","value")都产生一个Tuple对象,
而"key"+"value",不管多少个,都只有一string个对象,指向常量池。














 1689
1689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









