





这篇文章介绍的是 tflite2onnx 背后的故事,建议忽略 + 没有帮助~
已经有半年多时间没有更新了。这段时间的业余精力都花在做一个小破轮子 tflite2onnx,虽然我看到大多数时候人们想要的是 onnx2tflite,比较 ONNX 生态还是比较羸弱……
另外,惯例——公式部分复制过来的时候有问题,懒得修了(因为本文其实对大家没什么帮助),有兴趣的话可以去博客看原文。
原载于博客。采用知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可授权,转载请注明出处。
ONNX 旨在将深度学习框架联系在一起。 TF2ONNX 将 TensorFlow 模型转换为 ONNX ,这样其他深度学习系统可以从 TensorFlow 的功能中受益。但 TF2ONNX 当前不支持量化。并且有些模型仅以 TensorFlow Lite(TFLite)格式发布。本文介绍了 TFLite2ONNX ,它能将量化的 TFLite 模型转换为 ONNX 。
简介
由 Facebook 和 Microsoft 创建的开放格式神经网络交换格式 ONNX,是一种用于表示机器学习模型。
TF2ONNX 将 TensorFlow 模型转换为 ONNX,从而将 TensorFlow 训练后的模型引入支持 ONNX 的系统。
然而 TF2ONNX 有一些局限(v1.5.5,即开始开发 TFLite2ONNX 的时候),例如不支持 TensorFlow 2.0 或量化。将_易变_的 TensorFlow 模型转换为 ONNX 的工作量很大。并且,由于量化在深度学习部署中扮演着越来越重要的角色。
另一方面,TFLite 的模型表示相对稳定,并且由 Google 统一维护的 TensorFlow 和 TFLite 的模型转换器足够健壮。该转换器通过包括批量归一化折叠和激活函数融合在内的图转换简化了 TensorFlow 模型。还可以处理在 TensorFlow Quantization-aware Training(QAT)期间生成的 FakeQuantWithMinMaxVars 节点。
此外,尽管某些模型由 TensorFlow 构建,但仅发布时只有 TFLite 格式的模型,例如 Google MediaPipe 。ONNX 生态系统无法使用这类模型。
TFLite2ONNX 可以将 TFLite 模型转换为 ONNX。截至 v0.3,TFLite2ONNX 支持 TensorFlow 2.0(感谢 TFLite 转换器)和量化。本文介绍了 TFLite2ONNX 为缩小 TFLite 与 ONNX 模型表示之间的语义差异的背景和实现。
数据布局语义转换
最明显的差距是数据布局问题—— TFLite 模型是 NHWC 格式,而 ONNX 是NCHW,在本文中被称为布局语义差异。
问题与 TF2ONNX
TFLite 的数据布局格式在文档或模型表示中均未提及,但在 TFLite 转换器(TensorFlow 模型需要为 NHWC)和内核有隐式协议。ONNX 则在算子表示和文档(由算子表示生成)中明确声明它使用NCHW。
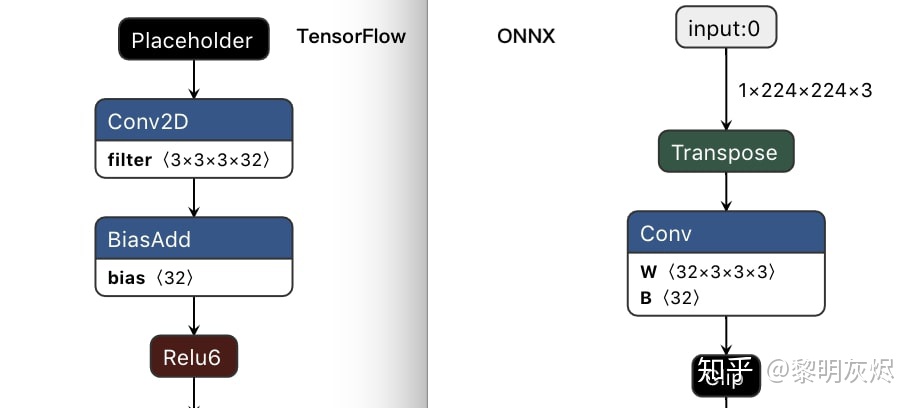
TF2ONNX 将内部算子和张量转换为 NCHW 数据布局,并允许用户通过 --inputs-as-nchw 选择是否需要将图的输入和输出转换为 NHWC 数据布局。默认情况(未指定 NCHW)会插入 Transpose 算子以桥接 NHWC 和 NCHW 子图。上面的图2是一个使用 TF2ONNX 将 MobileNetV2 TensorFlow模型转换为 ONNX 的实例。(有关 TF2ONNX 处理数据布局的更多描述,请参见 GitHub issue。)
在 TFLite2ONNX 的开发过程中,我们尝试了两种方法:
- 基于转换的方法——
v0.1启用,v0.3删除。 - 基于传播的方法——
v0.2引入并作为默认方法。
基于转换的方法
一个关于布局语义差异的事实是,某些算子具有隐式数据布局,如 Conv;而其他则不是,如 Add。
TFLite2ONNX 的基于转置的方法在算子有布局语义差异的地方插入一个转置模式。转置模式是用一个 Transpose 算子将源布局(TFLite)和目标的布局(ONNX)连接起来。
例如,将 TFLite 模式 ⟨ ℎ ⟩→[ ]⟨Datanhwc⟩→[Conv] 转换为 ⟨ ℎ ⟩→[ ]→⟨ ℎ ⟩→[ ]⟨Datanhwc⟩→[Transpose]→⟨Datanchw⟩→[Conv]。(在这篇文章中,⟨ ⟩⟨TensorName⟩ 和 [ ][Operator] 分别表示张量和算子。图3是转换MobileNetV2 的第一个 Conv 的示例。
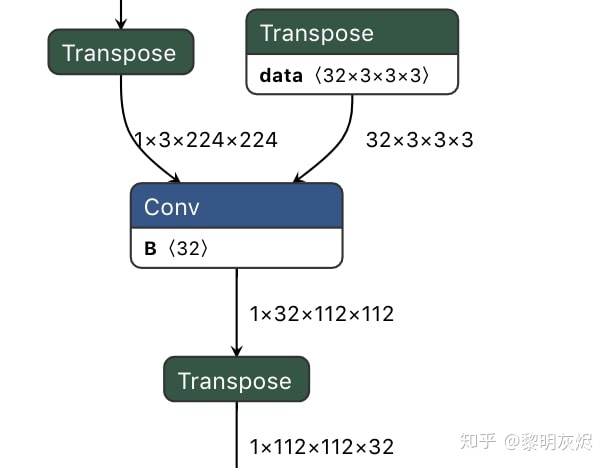
使用这种方法,我们只需要处理一组有限的算子,例如 Conv 和 Pooling。其他的算子和张量转换都是平凡的——没有布局语义上的差异。
基于传播的方法
尽管基于转换的方法可以处理布局语义差异,但由于添加了太多的算子和张量(即转换模式),因此生成的 ONNX 模型太大且复杂。基于传播的方法可以在整个图中传播布局语义差异来解决这个问题。
默认情况下(对于大多数情况),对于给定的图,某些张量具有隐式布局语义,例如直接连接到 Conv 的张量,而其他张量则没有,例如 Abs 和 Add。后着的对布局是透明的,这意味着连接到算子的所有张量都必须具有相同的布局语义或不具有这种语义。
因此,当布局透明的算子连接到具有隐式布局张量的算子时,透明算子的所有张量都具有与连接这两个算子的张量相同的布局语义。这便是传播的含义。
例如,在转换 TFLite 图(省略了kernel和 bias) ⟨ ℎ ⟩→[ ]→⟨ ℎ ⟩→[ ]→⟨ ?⟩⟨Anhwc⟩→[Conv]→⟨Bnhwc⟩→[Abs]→⟨C?⟩ 到 ONNX 时,张量 ⟨ ℎ ⟩⟨Anhwc⟩ 变成 ⟨ ℎ ⟩⟨Anchw⟩ ,⟨ ℎ ⟩⟨Bnhwc⟩ 变成 ⟨ ℎ ⟩⟨Bnchw⟩。因此 [ ][Abs] 的输出⟨ ⟩⟨C⟩ 应该与其输入 ⟨ ⟩⟨B⟩ 具有相同的格式。基于传播的方法会将 ⟨ ⟩⟨B⟩ 的格式传播给 ⟨ ⟩⟨C⟩。因此我们得到 ONNX 图 ⟨ ℎ ⟩→[ ]→⟨ ℎ ⟩→[ ]→⟨ ℎ ⟩⟨Anchw⟩→[Conv]→⟨Bnchw⟩→[Abs]→⟨Cnchw⟩,这其中未引入其他算子或张量。
在布局传播中,如果张量是 activations,则布局变换会置换张量的形状(即 ONNX 中的 value info),如果是权重的数据(即 ONNX 中的 initializer),还要转换数据。
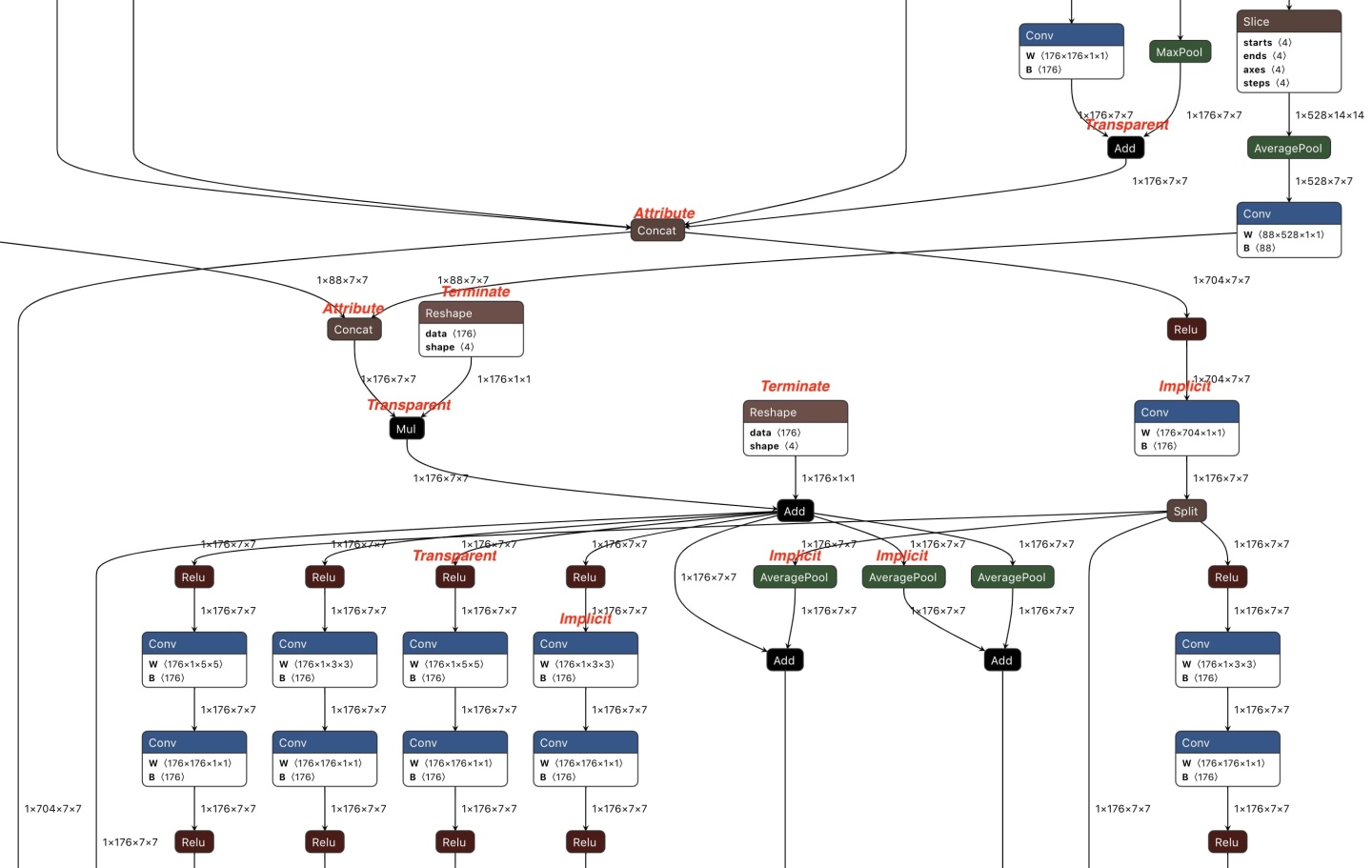
在实践中,算子分为四类(如图5所示):
- Implicit:算子在布局语义上有分歧,例如
Conv。它们是布局语义差异的来源。 - Transparent:对布局不敏感的算子,例如
Abs。如果任何张量具有布局语义差异,则将其传播到连接到此类算子的所有张量。 - Attribute:可以想 Transparent 那样传播布局语义差异的算子,但需要特殊处理处理敏感属性,例如
Concat的axis属性。传播后需要额外通过以调整这些属性。 - Terminate:没有和不能传播布局语义差异的算子,例如
Reshape。传播在碰到此类算子时停止。
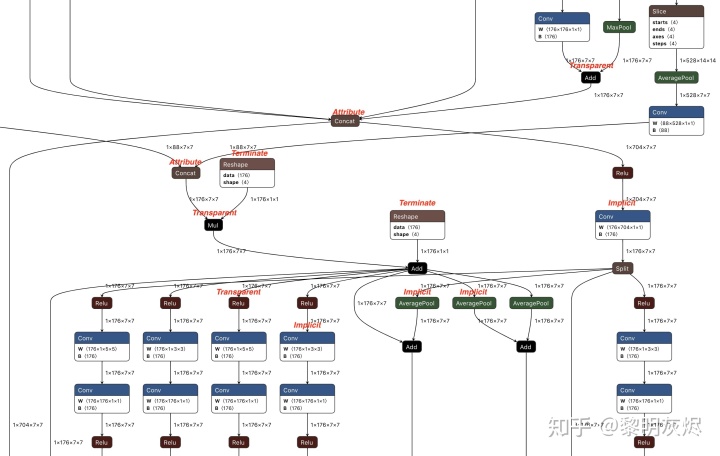
在整个图中传播布局语义差异时,对于某个算子:如果它是 Transparent 或 Attribute,则在其张量之间传播布局语义差异;如果是 Implicit 或 Terminate,则终止此方向上的传播。图 5 是用传播基础的方法从 NASNet TFLite 模型转换得到的 ONNX 模型的一部分。
显式布局和广播
通过基于传播的方法,转换后的 ONNX 模型可轻松处理布局语义差异,即无需引入其他算子或张量。
但是,有时可能存在不兼容的布局。考虑如下的 Reshape。如果 ⟨ ⟩⟨A⟩ 被传播而其他张量没有,由于用户可能会假设 ⟨ ⟩⟨B⟩ 的维度和 ⟨ ⟩⟨A⟩ 有某种关联,那么输出布局可能是意料之外的。(基于转换的方法没有问题,因为它的布局在模型级别上是 TFLite 格式的,布局语义差异在内部用 [ ]→[ ]→[ ][Transpose]→[OP]→[Transpose] 模式处理。) { ℎ}→⟨ ⟩→[ ℎ ]→⟨ ⟩⟨ ⟩}→[ ]→⟨ ⟩{Graph}→⟨A⟩→[Reshape]→⟨B⟩⟨C⟩}→[Concat]→⟨D⟩ 我们引入了显式布局来处理这种情况。用户可以给 TFLite2ONNX 提供 { : ( , )}{Tensor name:tuple(TFLite layout,ONNX layout)} 映射来描述 TFLite 布局和 ONNX 布局的关联。而且,用户可以灵活地为非 Transparent 的算子定义布局转换。例如,我们对只有 Add 算子的 TFLite 图执行 NHWC 到 NCHW 布局的转换。
另一个问题是二元算子的广播,例如 Add(有关更多信息,请参见此问题)。在下面的例子中, ⟨ ⟩⟨B⟩ 需要广播。如果 ⟨ ⟩⟨A⟩ 从 NHWC 转换为 NCHW,即 ⟨ (2×5×3×4)⟩⟨A(2×5×3×4)⟩,而 ONNX 模型中的 ⟨ ⟩⟨B⟩ 无法广播。更麻烦的是,布局语义转换在 ⟨ ⟩⟨B⟩ 处无法传播,因为 ⟨ ⟩⟨A⟩ 和 ⟨ ⟩⟨B⟩ 具有不同的维度。 { ℎ}→⟨ (2×3×4×5)⟩⟨ (4×5)⟩}→[ ]→⟨ ⟩{Graph}→⟨A(2×3×4×5)⟩⟨B(4×5)⟩}→[Add]→⟨C⟩ tflite2onnx 引入 Reshape 模式来处理广播问题。对于像 ⟨ ⟩⟨B⟩ 这样的张量,拓展它的维度(插入1)使它们彼此相等,以便传播和广播可以正确地工作。传播前的中间图示例如下。 { ℎ}→⟨ (2×3×4×5)⟩⟨ (4×5)⟩→[ ℎ ]→⟨ ′(1×1×4×5)⟩}→[ ]→⟨ ⟩{Graph}→⟨A(2×3×4×5)⟩⟨B(4×5)⟩→[Reshape]→⟨B(1×1×4×5)′⟩}→[Add]→⟨C⟩
量化语义转换
TensorFlow 很早就提供了生产级的量化支持。通过将量化的 TFLite 模型转换为 ONNX,我们可以将量化功能引入更多系统。(如果本节中的一些描述使您感到困惑,可以先阅读神经网络量化简介。)
问题与 TF2ONNX
TensorFlow 和 TFLite 提供了许多量化解决方案:规范,后训练和量化感知训练。所有这些技术最后生成量化的 TFLite 模型——大多数情况下时 uint8 格式。这些模型由 TFLite 运行时中的量化版本算子运行。本文将量化张量的 uint8 数据、scale、zero point 表示为量化语义。
另一方面,ONNX中的量化支持有两个方面(wiki):
- 接受低精度整数张量(
uint8或int8)的量化算子。QLinearConv和QLinearMatMul产生低精度输出,类似于 TFLite 的量化版Conv。ConvInteger和MatMulInteger生成int32输出,可以将其重新量化为低精度。
QuantizeLinear以及分别DequantizeLinear将高精度(float和int32)与低精度转换的算子。
TensorFlow 和 ONNX 之间的语义鸿沟很大。
在 TensorFlow 生态中,由于量化表示是为 TFLite 设计的,TensorFlow 图量化支持有限。因此,TF2ONNX 不提供量化支持。
使用量化算子
在 TFLite2ONNX 最初的设计中,如果量化的 TFLite 算子具有在 ONNX 中有对应,则将其转换为量化的 ONNX 算子,如 QLinearConv;否则转换回浮点算子。
由于只有 Conv 和 MatMul 在 ONNX 中具有量化算子,我们不可能生成端到端的量化 ONNX 模型。因此,在量化的 ONNX 算子两端需要插入 Quantize 和 Dequantize。 ⟨ ⟩⟨ ⟩}→[ ]→⟨ ⟩→[ ]→⟨ ⟩⟨Aq⟩⟨Bq⟩}→[Addq]→⟨Cq⟩→[Convq]→⟨Fq⟩ 例如,给定上面的 TFLite 图,其中 q 表示张量或算子被量化,量化和反量化算子被插入 [ ][Conv] 两端, 并将其他地方的张量和算子转换回浮点,结果如下所示。 ⟨ ⟩⟨ ⟩}→[ ]→⟨ ⟩→[ ]→⟨ 8⟩→[ ]→⟨ 8⟩→[ ]→⟨ ⟩⟨Afloat⟩⟨Bfloat⟩}→[Add]→⟨Cfloat⟩→[QuantizeLinear]→⟨Duint8⟩→[QLinearConv]→⟨Euint8⟩→[DequantizeLinear]→⟨Ffloat⟩ 对于主要由 Conv 构成的模型,例如 MobileNetV1(我们确实尝试过转换),这个问题还不大。但对于大多数其他模型,Conv 和 MatMul 只占算子总数的一小部分,这要在 ONNX 模型中插入太多的新算子和张量。
而且,像其他许多深度学习系统一样,ONNX 张量表示不具有量化语义。也就是说,低精度 uint8 张量就是单纯的 uint8 数据,就像 numpy 一样——没有_scale_ 和 zero point 描述。对于转换回浮点的张量,它们的量化语义已经丢失——这导致我们无法从量化感知训练中获益。
维护量化信息
TFLite2ONNX 不使用量化算子,而是通过插入量化模式在 ONNX 模型中维护量化语义。 [ ]→⟨ ⟩→[ ]→⎧⎩⎨⎪⎪⟨ ⟩⟨ _ ⟩⟨ ⟩⎫⎭⎬⎪⎪→[ ]→⟨ ′ ⟩→[ ][OP]→⟨Tf⟩→[Quantize]→{⟨Tq⟩⟨Tzero_point⟩⟨Tscale⟩}→[Dequantize]→⟨Tf′⟩→[OP] 具体而言,上面的 ONNX 图是tflite2onnx 是从 TFLite 图 [ ]→⟨ ⟩→[ ][OPq]→⟨Tq⟩→[OPq] 生成的。
如果原始的 TFLite 模型具有 O 个算子和 T 个张量,则生成的模型中最多可能有 +2 O+2T 个算子和 3 3T 个张量。尽管这种机制增加了更多的张量,但成功在 ONNX 模型中保留了比例和零点语义。图6 是将一个量化的 TFLite Conv 模型转换为 ONNX 的示例。
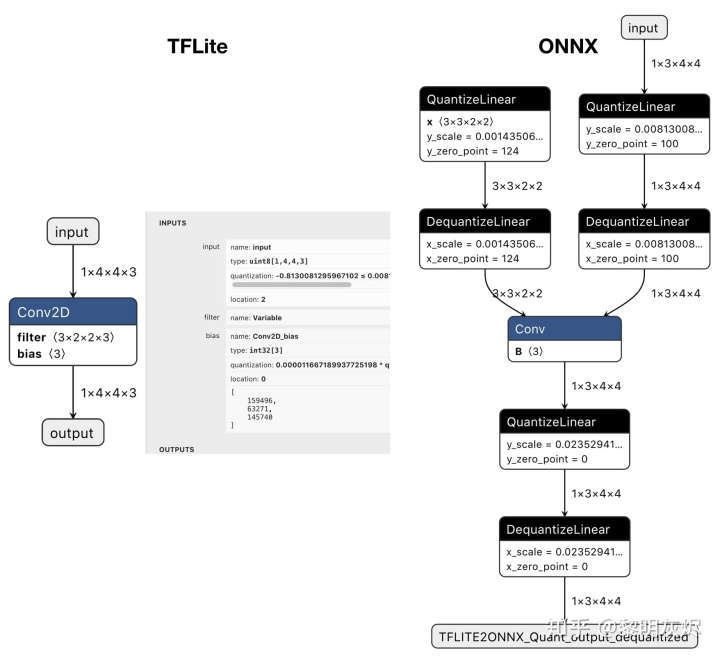
运行 ONNX 模型的框架可以决定如何启用量化的 ONNX 模型。可以将量化图转换回非量化图,或者使用其量化版本算子优化量化模式,以获得更好的性能。
实现
截至 v0.3,TFLite2ONNX 是一个非常简单的仅包含约 2000 行代码的软件包。这些代码分为几个部分:每个 TFLite 算子专用的转换器类;Graph 级别管理的数据布局和量化处理;帮助函数或封装,例如Tensor,Layout。
截至 v0.3 ,许多卷积神经网络已经得到支持(测试分支包含了一部分)。支持大约 20 个 TFLite 算子。有命令行工具和 Python 接口可用。
目前的限制包括:
- 尚未启用 RNN 或控制流网络。我们计划在下一个里程碑中做些尝试。
- 不支持控制生成的 ONNX 模型的版本控制。为了让 TFLite2ONNX 尽量简单,目前的计划是不支持版本控制,而是将其工作留给 ONNX 版本转换器。
- 目前许多算子尚不支持。如果发现尚不支持某些算子,可以发起新算子支持请求。如果您有兴趣帮助支持新算子,可以查看这一文档。
您可以在href="https://github.com/jackwish/tflite2onnx/issues?q=is%3Aissue+label%3AStory">带有 Story 标记的 GitHub 问题中找到更多开发相关的背景。















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









