






本篇主要介绍神经网络的参数更新方法
在介绍参数更新方法之前,需要知道损失函数(loss function)。
损失函数的作用是衡量模型预测值与实际值之间的差异。
一般神经网络用的损失函数是:交叉熵损失(cross entropy)。
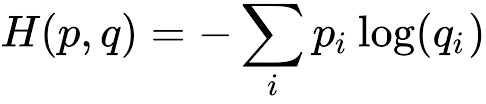
当pi=1时,函数图像如下:

x轴为qi,y轴为loss值(x轴的定义域一般在[0,1]之间)
上面公式pi指模型的实际值,qi值的是通过神经网络得到的预测值。n为模型预测值qi拥有的类别数量。上篇讲过一般输出层为一维向量,对应的loss就是pi和qi的点乘再求和,因为一般预测的pi是one-hot类型,只有一个值为1,其余都为0。所以loss是pi为1的对应的log(qi)。可以看出如果qi接近于1,那么loss的值就为0(如上面函数图像)。所以我们的目的就是使所有训练样本loss的值接近0。我们通过更新权重w来使模型的loss接近0,那么这些w到底如何更新才算最好?从上面图像看(定义域[0,1]之间),如果qi=1的值是函数的最小值,求w使得函数loss最小,有木有很熟悉。没错,这就需要用到偏导数了!!即梯度下降算法
前向传播与反向传播
前向传播:沿着神经网络输入到输出,更新权重w
反向传播:沿着神经网络输出到输入,更新权重w
其实这两种参数更新方法的本质都是基于梯度下降算法。只是由于神经网络的层数过多,参数量过大,再使用前向传播时,计算速度和资源消耗过大。这个时候才出现了反向传播算法。
在了解前向传播和反向传播之前,需要了解复合函数求导法。因为神经网络就可以写成一个复合函数,我们要求使得loss最小的每个w,就需要计算每个w的偏导数。
一般网络都是需要对loss求导,但下面为了方便我只用优化S(即目标y)

整个网络的复合函数为:
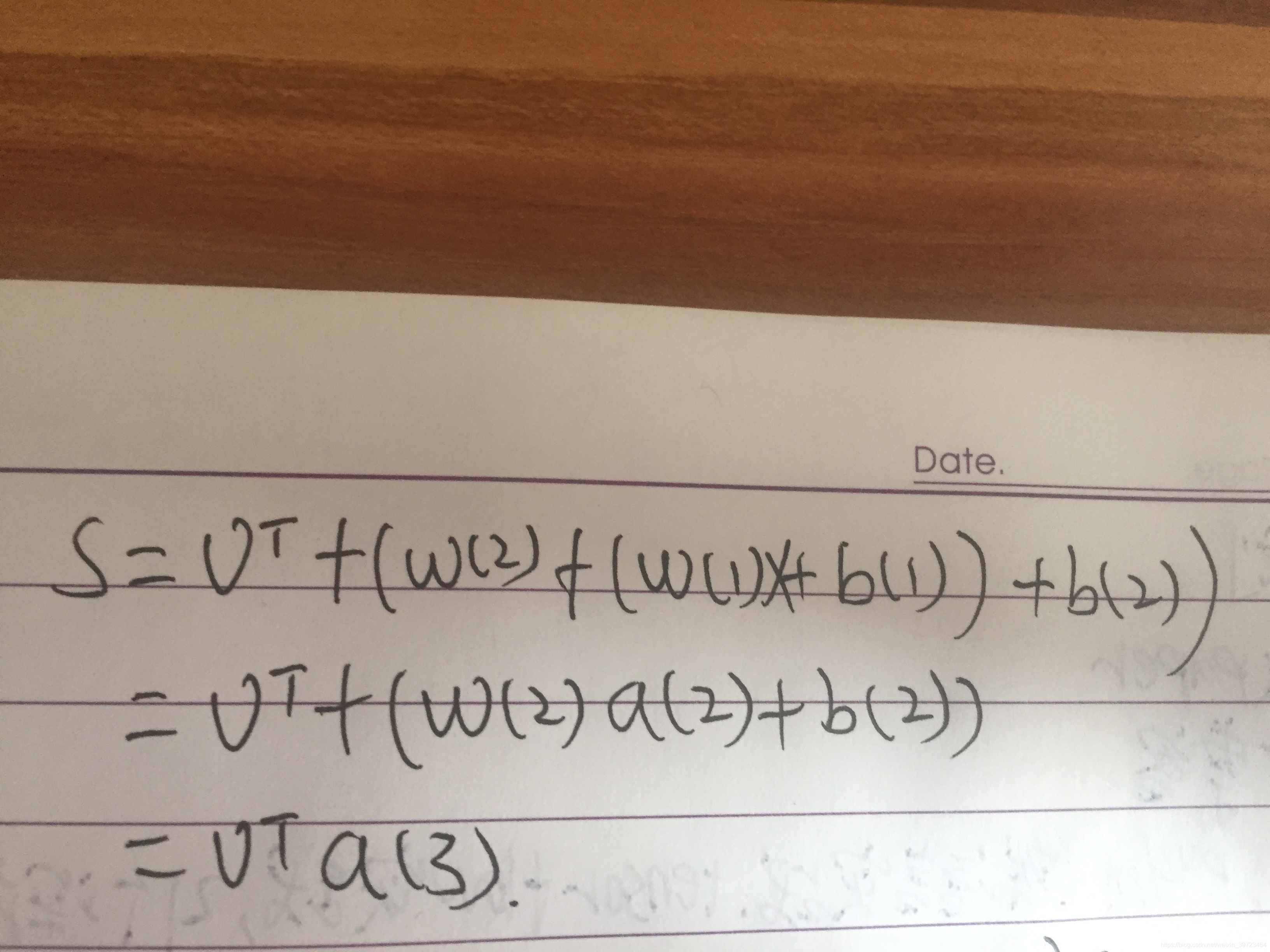
对权重w求导可以抽象为:
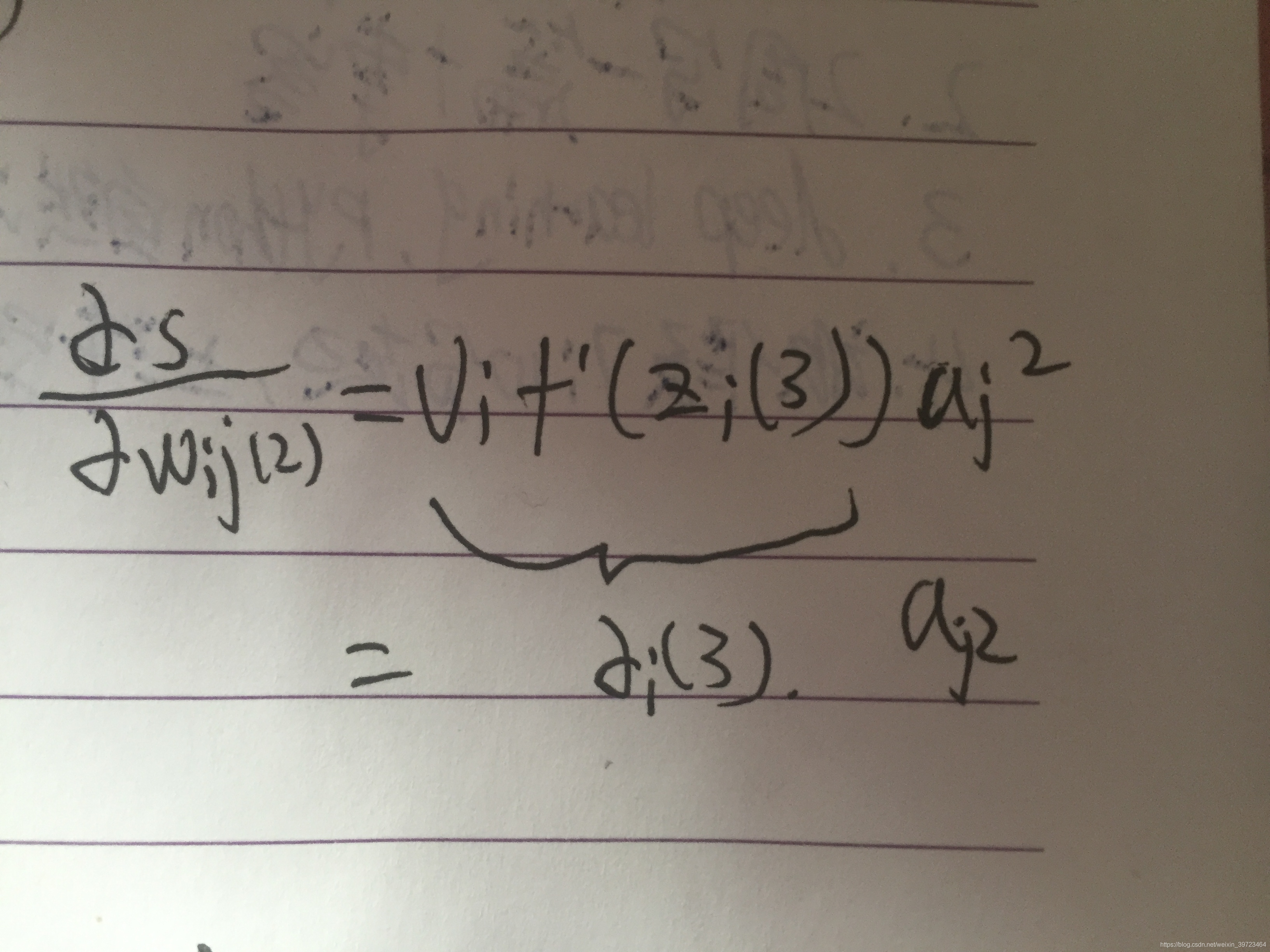
其中δi(3)为上一步求导结果,aj2为前向传播计算的结果。
以上述网络结构示意,带入w求导公式为:

可以看到δ(2)是δ(s)/δ(w2)的结果,之前已经计算过了,而a(1)也是在计算y的预测值时计算过了。
所以反向传播算法是,先进行前向传播计算a(1),a(2)的值,并存储在内存中。然后从更新输出层到倒数第一个隐藏层之间的权重,将计算的梯度保存到内存中,再更新倒数第一个隐藏层到倒数第二个隐藏层之间的梯度,这个时候需要用到之前保存的梯度,计算方式为之前保存的梯度*倒数第二隐藏层计算的a(n-1)的值。
使用反向传播比直接从输入层到输出层更新,计算量要小很多。直接前向更新参数,会做许多重复的运算,白白浪费计算资源。
本文主要参考了stanford的CS224N关于反向传播的例子。














 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









