







1. 前言:
LinkedHashMap是使用HashMap+LinkedList来实现Map接口。和HashMap的区别在于它维持一个双端链表保存所插入访问的节点。链表定义了迭代顺序,默认情况下顺序就是键值插入到Map的顺序(插入顺序)。
LinkedHashMap主要是基于HashMap中的方法来实现对数据结构的操作的,不同的是,LinkedHashMap维护了一个双向链表来保持顺序,而LinkedHashMap主要是定义了一些方法来维护双向链表。LinkedHashMap是基于HashMap的!!!

构造方法为LinkedHashMap(int,float,boolean)的可用来创建一个按照访问顺序迭代的LinkedHashMap,按照最少访问到最多访问的顺序链接结点,这种LinkedHashMap可用来实现LRU缓存。
另外由于jdk8的HashMap的源码发生了变化,这里我就拿jdk8以后的版本–jdk13的源码来进行学习了,jdk13相当于jdk8并没有做出较大的改变。
此外:想看HashMap源码解析的可以点击:
jdk8HashMap源码解析
jdk1.7HashMap源码解析
2. 定义
2.1 继承和实现
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
可以看出,LinkedHashMap是继承自HashMap的,LinkedHashMap的数据结构基本上和HashMap是相似的都是Node为基础,数组+链表/红黑树的形式来存储,只不过LinkedHashMap的Node多了类似于LinkedList的前标和后标,接下来我们看具体的结构。
2.2 重要字段
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head; // 链表头节点
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail; // 链表尾节点
/**
* The iteration ordering method for this linked hash map: {@code true}
* for access-order, {@code false} for insertion-order.
*
* @serial
*/
final boolean accessOrder; // 迭代顺序 true表示访问顺序,false表示插入顺序
2.3 初始化
可以看出LinkedHashMap的构造方法基本上是调用HashMap的构造方法,同时对accessOrder进行赋值。
由于accessOrder是final修饰的,所以只能在初始化的时候进行赋值
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
2.4 LinkedHashMap中的节点
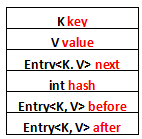
在HashMap中的节点是Node,包括hash,后标,key和值。LinkedHashMap中的节点用的是Entry,继承了Node:(PS:HashMap中的TreeNode继承自该节点)
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
可以看出多了before和after2个节点,这个作用主要是用来存放排序链表中的前标和后标,注意是排序链表中的,不是hash桶节点中的链表。
用图表示就是:
在整个系统中就是:
2.5 整个HashMap的图就像如下的结构:

3. 插入
3.1 put(K key, V value):
假如我执行了如下方法:
LinkedHashMap<String, String> map = new LinkedHashMap<>();
map.put("111", "111");
具体做了什么呢?
3.1.1 首先第一行,调用无参构造。
查看IDEA的debug模式:可以看到没有传入排序方式,所以默认按插入顺序,accessOrder为false

假如传入参数初始化:
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>(13, 0.75f, true);

3.1.2 然后第二行put方法做了什么:
这里的put调用的是HashMap的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // LinkedHashMap重写了该方法
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // LinkedHashMap中重写
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict); // LinkedHashMap中重写
return null;
}
3.2 newNode方法:
首先我们来看newNode方法,LinkedHashMap重写了该方法:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail; // 此时tail为null
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
从代码中我们可以看到,首先创建了我们需要进行插入的节点p,然后如果tail尾节点为null,则我们新插入的节点是尾节点,同时也是头节点;否则p的前顺序节点是原last节点,原last节点的后顺序节点是p节点。
3.3 afterNodeInsertion(boolean evict)实现
afterNodeInsertion(boolean evict)方法,是基于size发生变化的情况。
另外,afterNodeInsertion方法的evict参数如果为false,表示哈希表处于创建模式。只有在使用Map集合作为构造器创建LinkedHashMap或HashMap时才会为false,使用其他构造器创建的LinkedHashMap,之后再调用put方法,该参数均为true。LinkedHashMap的afterNodeInsertion()实现如下:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
可以看出,要想进入if语句,需要满足三个情况:
- evict为true。只要不是在构造方法中插入Map,evict就是true;
- head不为null。表明表不为空,可是之前说过这个方法只有在size发生变化,也就是变长时调用,也就是此时head一定不为空
- removeEldestEntry方法返回true,该方法从名字可以看出来是删除最老的节点。可是我们看到这个方法直接返回了false,什么情况,这个方法会返回true呢?我们需要重写这个方法。
首先,为什么我们要删除最老的节点?比方说,假如我们的链表最多只能维持100个元素,当插入第101个时,我们就需要把最老的那个元素删除,这也就是LRU算法的理念,所以在这里我们可以通过LinkedHashMap实现LRU缓存。
public boolean removeEldestEntry(Map.Entry<K,V> eldest){
return size()>100;
}
3.4 afterNodeAccess(Node e)实现
该方法目的是将当前节点放到顺序链表的最后,同时对顺序链表进行重排序。
在key重复时,会调用此方法,其中e表示插入的节点。该方法在accessOrder为true时才会生效,也就是在按读取顺序排序时才会生效。具体实现:
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 满足按读取顺序排序,并且当前节点不是顺序链表的尾节点
if (accessOrder && (last = tail) != e) {
// 这里定义p为当前节点,b为当前节点的前顺序节点,a为当前节点的后顺序节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null; // 将当前节点的后顺序节点设置为null
if (b == null)
head = a; // 如果当前节点的前节点为null,说明当前节点为顺序链表的头,那么就将当前节点的后节点设置为头
else
b.after = a; // 否则将当前节点的后节点设置为前节点的后节点(断开当前节点的前后联系)
if (a != null)
a.before = b; // 如果当前节点的后节点不为null,将当前节点的前节点设置为后节点的前节点
else
last = b; // 否则说明当前节点是尾,那么将前节点赋值给last,但是最上面if判断时,如果当前节点是尾节点,那么不会进入,这里我认为是容错
if (last == null)
head = p; // 如果尾是空,那么说明b为空,如果b为空,说明当前节点为链表原头节点,说明原链表中只有一个元素
else {
p.before = last; // 将当前节点的前节点设置为原尾节点
last.after = p; // 将尾节点的后节点设置为当前节点
}
tail = p; // 将当前节点设为尾节点
++modCount;
}
}
从中我们可以看出这个方法的目的主要是讲put的元素放到链表的尾端,同时修改链表的关联结构
4. 删除
LinkedHashMap的remove()方法根据键删除节点,如果哈希表中不存在键值,那么返回null。LinkedHashMap的remove()方法继承自HashMap的rmeove()方法,在将节点从链表或红黑树中移除后,调用afterNodeRemoval(Node e)方法,LinkedHashMap实现了该方法,其实现如下:
// e表示待删除的节点
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
从上面可以看到,afterNodeRemoval()方法主要就是将节点从双端链表中移除,具体的步骤和afterNodeAccess较为类似,这里就不做重复讲解了。
5. 获取
LinkedHashMap的get方法用于根据键得到值,如果哈希表中不包含该键,那么返回null,注意如果accessOrder为true,说明根据读取顺序排序,要将当前的key放置到链表尾部其实现如下:
public V get(Object key) {
Node<K,V> e;
//如果哈希表中不存在该键,返回null
if ((e = getNode(hash(key), key)) == null)
return null;
//如果accessOrder为true,即使用访问顺序
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
从上面代码可以看到,get()方法分为2步:
- 调用getNode()方法得到键对应的节点。如果节点为null,表明哈希表中不存在该键,那么返回null
- 如果哈希表中存在该键并且accessOrder为true,那么调用afterNodeAccess(e)将节点移到双端链表的尾部
6. 利用LinkedHashMap实现LRU算法缓存
6.1 首先我们先了解一下什么是LRU:
LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据,最近访问的数据会被排到最后。比如:我们的链表最多只能维持100个元素,当插入第101个时,我们就需要把最老的那个元素删除。
6.2 基于afterNodeInsertion方法实现:
还记得我们上面讲解源码时候说到,当成功插入一个数据时,会执行这个方法:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
上面说到,要想这个方法生效,需要重写removeEldestEntry方法。同时又因为LinkedHashMap初始化时可以传入一个参数accessOrder,如果传入的为true,LinkedHashMap链表就按照访问顺序倒序。
那么很好,我们要想实现一个LRU缓存,只需要继承LinkedHashMap,并重写removeEldestEntry方法:
public class LRUCacheByLinkedHashMap extends LinkedHashMap {
private int count;
public LRUCacheByLinkedHashMap(int count) {
super(count, 0.75f, true);
this.count = count;
}
// 判断长度是否超过限制,超过返回true,否则返回false
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > count;
}
public static void main(String args[]) {
LRUCacheByLinkedHashMap cache = new LRUCacheByLinkedHashMap(5);
for (Integer i = 0; i < 5; i ++) {
cache.put(i, i);
}
System.out.println("插入后:");
System.out.println(cache);
cache.get(2);
System.out.println("读取2后:");
System.out.println(cache);
cache.put(5,5);
System.out.println("插入5后:");
System.out.println(cache);
}
}
测试结果:
插入后:
{0=0, 1=1, 2=2, 3=3, 4=4}
获取2后:
{0=0, 1=1, 3=3, 4=4, 2=2}
插入5后:
{1=1, 3=3, 4=4, 2=2, 5=5}
从结果可以看出:
- LinkedHashMap时有序的
- 基于读取的顺序
- 如果长度超过了指定的长度,那么会删除最老的数据
参考:
https://segmentfault.com/a/1190000012964859
https://www.cnblogs.com/xrq730/p/5052323.html
https://blog.csdn.net/qq_19431333/article/details/73927738















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









