





9.1 Tars RPC服务模型概览
Tars服务模型图如下:
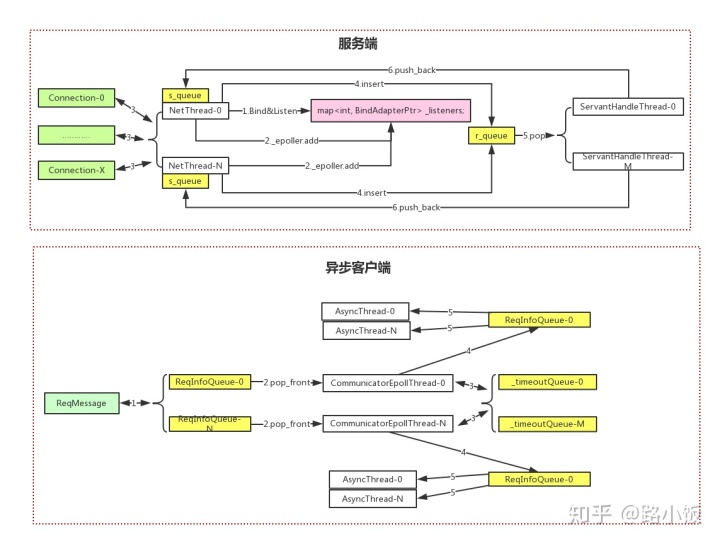
服务端:
- 1 TC_EpollServer中可以配置NetThread的数量,默认为1个,最多为15个。0号NetThread负责处理绑定和监听文件操作符,并保存在_listenners中
- 2 所有NetThread线程中的epoll会通过_epoller.add将_listeners加入到自己的事件集中
- 3 所有NetThread都有可能接收客户端连接,生成Connection,Connection按照一定规则分配到不同的NetThread上
- 4 不同NetThread通过Connection,将接收到的内容放到同一个队列r_queue中(代码里叫做recv_queue _rbuffer)
- 5 多个业务处理线程ServantHandleThread会从r_queue中取出(pop_front)内容进行处理
- 6 ServantHandleThread处理完业务逻辑后会按照一定规则将结果push_back到不同的NetThread的队列(s_queue)中(代码里叫做send_queue _sbuffer;),最后在通过Connection将结果返回给客户端
异步客户端:
- 1 CommunicatorEpollThread的数目也是可配的,最低1个,最多64个。AsyncThread数目默认3个,最多1024个。客户端的请求封装在ReqMessage中,放入到队列ReqInfoQueue中,并通知CommunicatorEpollThread,这里ReqInfoQueue的数目对应了CommunicatorEpollThread的数目
- 2 CommunicatorEpollThread从ReqInfoQueue中获取请求数据ReqMessage
- 3 CommunicatorEpollThread将ReqMessage发送到服务端,同时把ReqMessage保存在_timeoutQueue中。接收到来自服务端的结果后,从_timeoutQueue中拿到对应的ReqMessage,把结果放入ReqMessage中。如果是同步客户端,到这一步就完成了,如果是异步客户端,继续下面步骤
- 4 CommunicatorEpollThread将保存返回结果的ReqMessage放入ReqInfoQueue中,这里的ReqInfoQueue属于每个CommunicatorEpollThread
- 5 AsyncThread线程从ReqInfoQueue中获取ReqMessage进行回调函数的处理
后续会根据上面的框架,去逐步分析其中的一些细节,探究Tars高性能的一些“秘密”
9.2 Tars协议
9.2.1 是什么
借用官方说法:
TARS编码协议是一种数据编解码规则,它将整形、枚举值、字符串、序列、字典、自定义结构体等数据类型按照一定的规则编码到二进制数据流中。对端接收到二进制数据流之后,按照相应的规则反序列化可得到原始数值。
简单理解,TARS编码协议提供了一种将数据序列化、反序列化的方法。其角色和我们认识的protobuf、json、xml等同。
9.2.2 怎么用
一般客户端到服务端的数据交互流程如下:
- 1、客户端原始请求数据---->序列化---->服务端
- 2、服务端---->反序列化---->原始请求数据
- 3、服务端原始返回数据---->序列化----->客户端
- 4、客户端----->反序列化----->原始返回数据
现在来看Tars 官方RPC源码中是怎么实现上面第3、4步的:
首先是服务端将数据序列化:
//位置:cpp/servant/libservant/TarsCurrent.cpp 221
void TarsCurrent::sendResponse(int iRet, const vector<char>& buffer, const map<string, string>& status, const string & sResultDesc)
{
//省略部分代码
………………
TarsOutputStream<BufferWriter> os;
if (_request.iVersion != TUPVERSION)
{
//将数据放到ResponsePacket结构中
ResponsePacket response;
response.iRequestId = _request.iRequestId;
response.iMessageType = _request.iMessageType;
response.cPacketType = TARSNORMAL;
response.iVersion = TARSVERSION;
response.status = status;
response.sBuffer = buffer;
response.sResultDesc = sResultDesc;
response.context = _responseContext;
response.iRet = iRet;
TLOGINFO("[TARS]TarsCurrent::sendResponse :"
<< response.iMessageType << "|"
<< _request.sServantName << "|"
<< _request.sFuncName << "|"
<< response.iRequestId << endl);
//调用序列化方法,response中的数据都保存在了os中
response.writeTo(os);
}
//省略部分代码
…………………………
//获取内容长度
tars::Int32 iHeaderLen = htonl(sizeof(tars::Int32) + os.getLength());
string s = "";
//返回的s的格式是内容长度+内容
s.append((const char*)&iHeaderLen, sizeof(tars::Int32));
s.append(os.getBuffer(), os.getLength());
_servantHandle->sendResponse(_uid, s, _ip, _port, _fd);
}再来看客户端怎样解析来自服务端的返回:
//位置:cpp/servant/libservant/Transceiver.cpp 331
int TcpTransceiver::doResponse(list<ResponsePacket>& done)
{
…………
if(!_recvBuffer.IsEmpty())
{
try
{
//接收到的服务端的序列化好的数据
const char* data = _recvBuffer.ReadAddr();
size_t len = _recvBuffer.ReadableSize();
size_t pos = 0;
//获取协议封装类
ProxyProtocol& proto = _adapterProxy->getObjProxy()->getProxyProtocol();
if (proto.responseExFunc)
{
long id = _adapterProxy->getId();
//将data反序列化到done中
pos = proto.responseExFunc(data, len, done, (void*)id);
}
…………
}
}这里的responseExFunc来自ProxyProtocol::tarsResponse(cpp/servant/AppProtocal.h 398)
template<uint32_t iMaxLength>
static size_t tarsResponseLen(const char* recvBuffer, size_t length, list<ResponsePacket>& done)
{
…………
TarsInputStream<BufferReader> is;
//将数据放入is中
is.setBuffer(recvBuffer + pos + sizeof(tars::Int32), iHeaderLen - sizeof(tars::Int32));
pos += iHeaderLen;
//将is中的数据进行反序列化,填充到rsp中
ResponsePacket rsp;
rsp.readFrom(is);
…………
}从上面代码中可以看出:
- 序列化数据使用的是:ResponsePacket.writeTo()
- 反序列化数据使用的是:ResponsePacket.readFrom()
9.2.3 一个独立的可编译调试的demo
获取代码
下载代码后,进入tup目录
- 执行./rush.sh,可生成proto-demo
- 执行./proto-demo > tmp.txt,可在tmp.txt看到相关调试内容(我自己已经加了一些调试内容)
这个demo就是从9.2.2节中的内容直接抽取出来形成的,可以很方便的进行跟踪调试。
9.2.4 协议序列化分析-HEAD
把结构化数据序列化,用大白话解释就是想办法把不同类型的数据按照顺序放在一个字符串里。反序列化就是还能从这个字符串里把类型和数据正确解析出来。一般来说,要达成正确的效果,有三个因素是必须考虑的:
- 标记数据的位置。例如是位于字符串头部还是字符串末尾,或者中间某个部分
- 标记数据的类型,例如int char float vector等
- 标记数据内容
Tars协议也跳不出这个基本规则,它的数据是由两部分组成:
| HEAD | BUF |
- HEAD为头部信息(包含了数据位置和数据类型),BUF为实际数据。注意BUF里可以继续嵌套| HEAD | BUF |这样的类型,以满足复杂数据结构的需要
- 像char、short、int之类的简单类型时,只需要:| HEAD | BUF |
- 当数据类型为vector< char >时,就变为了| HEAD1 | HEAD2 | BUF |。这时候HEAD1 存储vector类型,HEAD2 存储char类型
我们再具体看下HEAD中包括的内容:
| TAG1(4 bits) | TYPE(4 bits) | TAG2(1 byte或者8 bits)
- TYPE表示类型,用4个二进制位表示,取值范围是0~15,用来标识数据类型。下面的Tars官方代码标明了具体数据类型的TYPE值
//位置:/cpp/servant/tup/Tars.h 60行
//数据头类型
#define TarsHeadeChar 0
#define TarsHeadeShort 1
#define TarsHeadeInt32 2
#define TarsHeadeInt64 3
#define TarsHeadeFloat 4
#define TarsHeadeDouble 5
#define TarsHeadeString1 6
#define TarsHeadeString4 7
#define TarsHeadeMap 8
#define TarsHeadeList 9
#define TarsHeadeStructBegin 10
#define TarsHeadeStructEnd 11
#define TarsHeadeZeroTag 12
#define TarsHeadeSimpleList 13- TAG由TAG1和TAG2一起组成,标识数据的位置。当TAG值不超过14时候,只需要TAG1,当TAG值超过14时候,TAG1为240,TAG2标识TAG的值。下面的代码标明了这个逻辑
//位置:/cpp/servant/tup/Tars.h 96行
#define TarsWriteToHead(os, type, tag)
do {
if (tars_likely((tag) < 15))
{
//只有TAG1
TarsWriteUInt8TTypeBuf( os, (type) + ((tag)<<4) , (os)._len);
}
else
{
//TAG1
TarsWriteUInt8TTypeBuf( os, (type) + (240) , (os)._len);
//TAG2
TarsWriteUInt8TTypeBuf( os, (tag), (os)._len);
}
} while(0)- 具体看个TAG小于14的例子:TAG1为1,TYPE为TarsHeadeInt32(2),用二进制表示的话,TAG1为0001,TYPE为0010,HEAD组成方式是将TAG1二进制和TYPE二进制拼接起来,即:
00010010 换算为10进制是18。 前4位为TAG1,后4位为TYPE,从这样的拼接方式中可以看到,相当于是把TAG1右移了4位再加上TYPE
从上面贴出的代码中我们也可以看到拼接方式的表示:"(type) + ((tag)<<4)",即:HEAD = 2 + (1<<4) = 2 + 16 = 18。就这样Tars协议可以用1byte同时表示数据类型和数据位置
- 再看个TAG大于14的例子:TAG1为240(固定值),TAG2为200,TYPE为TarsHeadeInt32(2),HEAD的二进制表示为:
11110010 11001000 用10进制表示为242 200 前八位中,1111代表TAG1的值240(即11110000),0010代表TYPE的值2(即0010)。后八位为TAG2的值200(即11001000)
9.2.5 协议序列化分析-BUF
| HEAD | BUF |
BUF的内容和所占据的字节数根据不同的TYPE而有所不同
(1)基本类型(Short、UInt16、Int32、UInt32、Int64、Float、Double等)
- 以Short为例:当值在-128和127之间,借用Char来保存BUF,即BUF仅占用sizeof(Char)(一般为1byte)。当值不在上述区间,BUF占用sizeof(Short)(一般为2byte)。具体代码如下:
//位置:cpp/servant/tup/Tars.h 1718行
void write(Short n, uint8_t tag)
{
//if(n >= CHAR_MIN && n <= CHAR_MAX){
if (n >= (-128) && n <= 127)
{
write((Char) n, tag);
}
else
{
/*
DataHead h(DataHead::eShort, tag);
h.writeTo(*this);
n = htons(n);
this->writeBuf(&n, sizeof(n));
*/
//定义HEAD
TarsWriteToHead(*this, TarsHeadeShort, tag);
n = htons(n);
//定义BUF
TarsWriteShortTypeBuf(*this, n, (*this)._len);
}
}具体BUF占用大小在TarsWriteShortTypeBuf中
//位置:cpp/servant/tup/Tars.h 165行
#define TarsWriteShortTypeBuf(os, val, osLen)
do {
TarsReserveBuf(os, (osLen)+sizeof(Short));
(*(Short *)((os)._buf + (osLen))) = (val);
(osLen) += sizeof(Short);
} while(0)其他基本类型都可以在Tars.h找到对应代码,可自行参照
(2)数字0
- 数字0比较特殊,HEAD拼好后,不需要BUF。参见下面代码。
//位置:cpp/servant/tup/Tars.h 1690行
void write(Char n, uint8_t tag)
{
/*
DataHead h(DataHead::eChar, tag);
if(n == 0){
h.setType(DataHead::eZeroTag);
h.writeTo(*this);
}else{
h.writeTo(*this);
this->writeBuf(&n, sizeof(n));
}
*/
if (tars_unlikely(n == 0))
{
//当n为0时候,仅需要在HEAD中保存TarsHeadeZeroTag类型即可,不需要BUF
TarsWriteToHead(*this, TarsHeadeZeroTag, tag);
}
else
{
//写HEAD
TarsWriteToHead(*this, TarsHeadeChar, tag);
//写BUF
TarsWriteCharTypeBuf(*this, n, (*this)._len);
}
}(3)字符串,参见Tars.h中函数:
void write(const std::string& s, uint8_t tag) 1801行
(4)map,参见Tars.h中函数:
void write(const std::map& m, uint8_t tag) 1837行
(5)vector,参见Tars.h中函数:
void write(const std::vector& v, uint8_t tag) 1853行 void write(const std::vector& v, uint8_t tag) 1877行
(6)其他类型
9.2.6 协议序列化实例
以 9.2.3 节中的demo为例,举例说明数据是怎样被序列化的
//learn-tars/tup/main.cpp
14 TarsOutputStream<BufferWriter> os;
15
16 string res = "I am ok";
17
18 vector<char> buffer;
19
20 buffer.assign(res.begin(),res.end());
21
22 map<string, string> status;
23
24 status["test"] = "test";
25
26 map<string, string> _responseContext;
27
28 _responseContext["test1"] = "test1";
29
30 ResponsePacket response;
31
32 response.iRequestId = 1;
33 response.iMessageType = 0;
34 response.cPacketType = TARSNORMAL;
35 response.iVersion = TARSVERSION;
36 response.status = status;
37 response.sBuffer = buffer;
38 response.sResultDesc = "123";
39 response.context = _responseContext;
40 response.iRet = 0;
41
42 response.writeTo(os);- 14行声明了序列化容器
- 16-28行准备了测试数据
- 30-40行对response进行了数据填充
- 42行调用了response.writeTo方法进行序列化
response.writeTo方法是在RequestF.h中实现的,继续看代码:
//learn-tars/tup/RequestF.h
147 template<typename WriterT>
148 void writeTo(tars::TarsOutputStream<WriterT>& _os) const
149 {
150 _os.write(iVersion, 1);
151 _os.write(cPacketType, 2);
152 _os.write(iRequestId, 3);
153 _os.write(iMessageType, 4);
154 _os.write(iRet, 5);
155 _os.write(sBuffer, 6);
156 _os.write(status, 7);
157 if (sResultDesc != "")
158 {
159 _os.write(sResultDesc, 8);
160 }
161 if (context.size() > 0)
162 {
163 _os.write(context, 9);
164 }
165 }- 150-164行说明了序列化的顺序
注意:iVersion为Short,当值在-128和127之间时,是当作Char类型进行处理的,见如下代码:
//learn-tars/tup/Tars.h
1753 void write(Short n, uint8_t tag)
1754 {
1755 std::cout<<"write Short "<<n<<" tag is "<<(int)tag<<std::
endl;
1756 //if(n >= CHAR_MIN && n <= CHAR_MAX){
1757 if (n >= (-128) && n <= 127)
1758 {
1759 write((Char) n, tag);
1760 }
1761 else
1762 {
1763 /*
1764 DataHead h(DataHead::eShort, tag);
1765 h.writeTo(*this);
1766 n = htons(n);
1767 this->writeBuf(&n, sizeof(n));
1768 */
1769 TarsWriteToHead(*this, TarsHeadeShort, tag);
1770 n = htons(n);
1771 TarsWriteShortTypeBuf(*this, n, (*this)._len);
1772 }
1773 }而在Char类型处理时候,n为0时候,TYPE取值TarsHeadeZeroTag,不为0时候,TYPE取值TarsHeadeChar,见如下代码:
//learn-tars/tup/Tars.h
1722 void write(Char n, uint8_t tag)
1723 {
1724 std::cout<<"write Char "<<n<<" tag is "<<(int)tag<<std::e
ndl;
1725 /*
1726 DataHead h(DataHead::eChar, tag);
1727 if(n == 0){
1728 h.setType(DataHead::eZeroTag);
1729 h.writeTo(*this);
1730 }else{
1731 h.writeTo(*this);
1732 this->writeBuf(&n, sizeof(n));
1733 }
1734 */
1735 if (tars_unlikely(n == 0))
1736 {
1737 std::cout<<"write n == 0 "<<n<<std::endl;
1738 TarsWriteToHead(*this, TarsHeadeZeroTag, tag);
1739 }
1740 else
1741 {
1742 std::cout<<"write n != 0 "<<n<<std::endl;
1743 TarsWriteToHead(*this, TarsHeadeChar, tag);
1744 TarsWriteCharTypeBuf(*this, n, (*this)._len);
1745 }
1746 }- 根据上面思路,可以看到其他类型的数据也都对应着一套HEAD和BUF的拼装方法,由此可以整理出demo中数据的逻辑处理顺序(如果图片看不清楚,可右键选择“在新标签页中打开图片”)
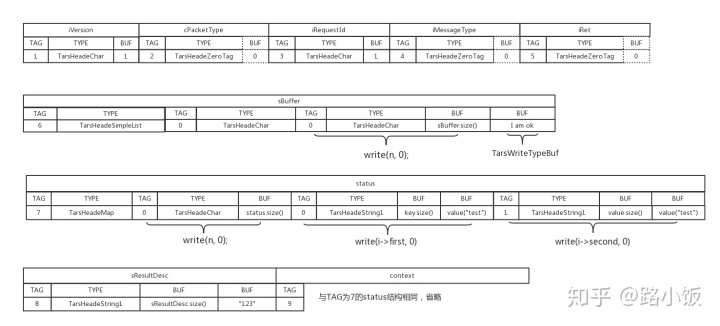
根据上面的逻辑图,可以得到序列化后的真实数据
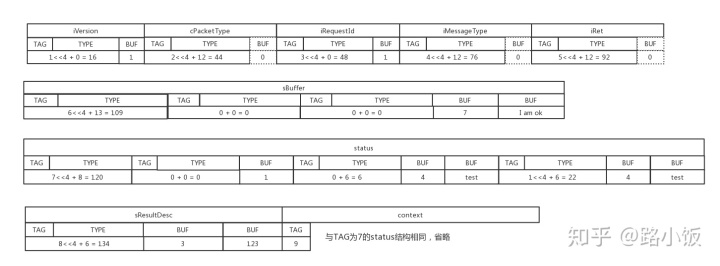
在调试9.2.3节demo时候,打印出来的数据默认是字符的,所以可以看到iVersion第一个打印出来的字符是^P(即整数16)
9.2.7 协议反序列化分析
理解了协议的序列化,反序列化就比较简单了,假设已经知道iVersion的反序列化数据为^P^A,其中|HEAD|为^P(注意,HEAD只占一个Byte)
- ^P转为十进制整数为16,转为二进制为00010000
- 将数据00010000右移4位为00000001,这就是TAG的值1
- 将数据00010000做与运算:00010000 & 0x0F = 0, 这就是TYPE的值0,即TarsHeadeChar
- 知道了TYPE的值,后面|BUF|所占长度可由TYPE得到,本例中也占一个字节,及^A,转为十进制整数为1
- 这样就完成了iVersion的反序列化
9.2.8 协议反序列化实例
再复习下9.2.3节的代码中是如何反序列化的
//learn-tars/tup/main.cpp
56 //反序列化
57
58 list<ResponsePacket> done;
59
60 ProxyProtocol _proxyProtocol;
61
62 _proxyProtocol.responseFunc = ProxyProtocol::tarsResponse;
63
64 const char* data = s.c_str();
65
66 size_t len = s.size();
67
//反序列化方法,反序列化完的数据放入done中
68 size_t pos = _proxyProtocol.responseFunc(data, len, done);- 这里的responseExFunc来自ProxyProtocol::tarsResponse,其中最主要的逻辑是
//learn-tars/tup/AppProtocal.h
451 ResponsePacket rsp;
452 rsp.readFrom(is);- rsp.readFrom(is)中readFrom的实现代码如下:
//learn-tars/tup/RequestF.h
166 template<typename ReaderT>
167 void readFrom(tars::TarsInputStream<ReaderT>& _is)
168 {
169 resetDefautlt();
170 _is.read(iVersion, 1, true);
171 _is.read(cPacketType, 2, true);
172 _is.read(iRequestId, 3, true);
173 _is.read(iMessageType, 4, true);
174 _is.read(iRet, 5, true);
175 _is.read(sBuffer, 6, true);
176 _is.read(status, 7, true);
177 _is.read(sResultDesc, 8, false);
178 _is.read(context, 9, false);
179 }同样以iVersion为例,简要说明代码处理流程:
- 上面170行代码会调用:
//learn-tars/tup/Tars.h
1105 void read(Short& n, uint8_t tag, bool isRequire = true)
1106 {
1107 std::cout<<"read Short "<<std::endl;
1108 uint8_t headType = 0, headTag = 0;
1109 bool skipFlag = false;
//TarsSkipToTag方法会确认TYPE和TAG的值
1110 TarsSkipToTag(skipFlag, tag, headType, headTag);
1111 if (tars_likely(skipFlag))
1112 {
//根据headType的值确定后面|BUF|内容的长度
1113 switch (headType)
1114 {
1115 case TarsHeadeZeroTag:
1116 std::cout<<"read Short TarsHeadeZeroTag"<<std::endl;
1117 n = 0;
1118 break;
1119 case TarsHeadeChar:
1120 std::cout<<"read Char TarsHeadeChar"<<std::endl;
1121 TarsReadTypeBuf(*this, n, Char);
1122 break;
1123 case TarsHeadeShort:
1124 std::cout<<"read Short TarsHeadeShort"<<std::endl;
1125 TarsReadTypeBuf(*this, n, Short);
1126 n = ntohs(n);
1127 break;
1128 default:
1129 {
1130 char s[64];
1131 snprintf(s, sizeof(s), "read 'Short' type mism
atch, tag: %d, get type: %d.", tag, headType);
1132 throw TarsDecodeMismatch(s);
1133 }
1134 }
1135 }
1136 else if (tars_unlikely(isRequire))
1137 {
1138 char s[64];
1139 snprintf(s, sizeof(s), "require field not exist, tag:
%d, headTag: %d", tag, headTag);
1140 throw TarsDecodeRequireNotExist(s);
1141 }
1142 std::cout<<"read Short n is "<<n<<std::endl;
1143
1144 }- 1110行函数TarsSkipToTag会确认TYPE和TAG的值
- 1113行会根据headType的值确定后面|BUF|内容的长度
再看下TarsSkipToTag是怎么处理的:
//learn-tars/tup/Tars.h
335 #define TarsSkipToTag(flag, tag, retHeadType, retHeadTag)
336 do {
337 try
338 {
339 uint8_t nextHeadType, nextHeadTag;
340 while (!ReaderT::hasEnd())
341 {
342 size_t len = 0;
//TarsPeekFromHead里进行了运算,得到TYPE和TAGE
343 TarsPeekFromHead(*this, nextHeadType, nextHeadTag, len);
344 if (tars_unlikely(nextHeadType == TarsHeadeStructEnd || ta
g < nextHeadTag))
345 {
346 break;
347 }
348 if (tag == nextHeadTag)
349 {
350 std::cout<<"TarsSkipToTag tag == nextHeadTag"<<std::en
dl;
351 (retHeadType) = nextHeadType;
352 (retHeadTag) = nextHeadTag;
353 TarsReadHeadSkip(*this, len);
354 (flag) = true;
355 break;
356 }
357 std::cout<<"TarsSkipToTag tag != nextHeadTag"<<std::endl;
358 TarsReadHeadSkip(*this, len);
359 skipField(nextHeadType);
360 }
361 }
362 catch (TarsDecodeException& e)
363 {
364 }
365 } while(0)- 343 行TarsPeekFromHead函数里得到了nextHeadType和nextHeadTag,对应着9.2.7节中的运算
//learn-tars/tup/Tars.h
255 #define TarsPeekFromHead(is, type, tag, n)
256 do {
257 std::cout<<"TarsPeekFromHead begin"<<std::endl;
258 (n) = 1;
259 uint8_t typeTag, tmpTag;
260 TarsPeekTypeBuf(is, typeTag, 0, uint8_t);
261 std::cout<<"TarsPeekFromHead typeTag "<<(int)typeTag<<std::endl;
262 tmpTag = typeTag >> 4;
263 std::cout<<"TarsPeekFromHead tmpTag "<<(int)tmpTag<<std::endl;
264 (type) = (typeTag & 0x0F);
265 std::cout<<"TarsPeekFromHead type "<<(int)type<<std::endl;
266 if(tars_unlikely(tmpTag == 15))
267 {
268 std::cout<<"TarsPeekFromHead unlikely tmpTag "<<(int)tmpTag<<s
td::endl;
269 TarsPeekTypeBuf(is, tag, 1, uint8_t);
270 (n) += 1;
271 }
272 else
273 {
274 (tag) = tmpTag;
275 }
276 } while(0)














 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









