





ResNet的介绍
为什么要用ResNet
我们都知道:在训练卷积神经网络的过程中,当浅层的神经网络训练效果较差时,可以通过适当地加深网络的层数,从而获取一个优化效果更好的模型。这是因为随着网络的深度的增加,网络所能提取的信息就能更加的丰富。然而在实际的实验过程中,我们会发现:随着网络深度的加深,训练集的loss首先会逐渐下降,然后趋于平缓;当我们继续加深网络的深度时,训练集的loss反而开始上升。也就是说,网络出现了“退化”(degradation)的现象。
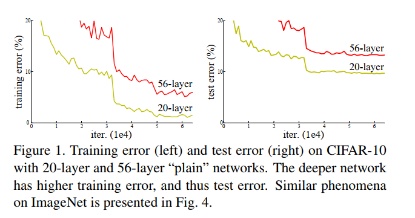
图1 20层和56层的神经网络对CIFAR-10的训练结果图[1]
为了能够让深层的网络训练出来的模型效果优于浅层的网络,何凯明等人提出了一种新的网络结构,这就是ResNet。
ResNet的基本单元
在解释ResNet是如何解决“退化”现象之前,先简单地介绍一下残差网络的基本单元,也就是残差块:
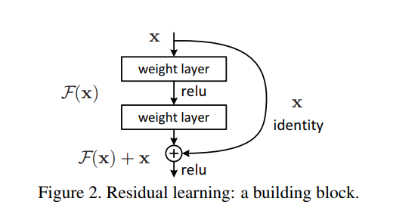
图2 ResNet的基本单元[1]
ResNet的残差块在一个或者多个卷积层之间加上一条“短接线”(shortcut connection),这条“短接线”会起到一个恒等映射(identity mapping )的作用。接下来仔细介绍一下,以这种结构组成的ResNet网络为什么可以避免深层网络的“退化”现象:假设输入为X,将以X为输入的某网络层的输出设为H(X)。在一般的卷积神经网络如VGG中,由输入X,需要通过网络层的训练直接拟合得到输出H(X);而在上图所示的基本单元中,由于存在短接线,由输入X,为得到输出H(X),只需要通过网络层的训练拟合得到残差函数F(X)=H(X)-X,再间接得到基本单元的输出H(X)=F(X)+X。那么,为什么我们要拟合残差函数F(X)=H(X)-X,而不是直接拟合得到H(X)呢?换句话说,拟合残差函数F(X)=H(X)-X,与拟合H(X)相比,有什么好处呢?
现在我们假设网络达到某一深度的时候,该层的输出X已经达到最优状态,也就是说,此时的错误率是最低的时候,再继续加深网络的层数就会出现退化的现象。如果使用一般的卷积神经网络如VGG,现在将该层的输出X作为下一层的输入进行训练,这时更新下一层的权值的代价相对较高,因为下一层的权值要使得输出H(X)仍然保持最佳状态,即H(X)=X。但是采用ResNet时,还是假设网络达到某一深度的时候,该网络的输出X已经达到最优状态,将该层的输出X作为下一层的输入进行训练,为了保证下一层的输出H(X)仍然是最优状态,只需要拟合残差函数F(x)=H(X)-X=0就可以了,这时下一层的输出H(X)就等于X。当然上面提到的只是理想情况,但是总会有那么一个时刻,某一层的输出能够无限接近最优解。所以,相对于使用一般的卷积神经网络如VGG,需要直接拟合得到输出H(X),而采用ResNet只需要拟合残差函数F(x),而得到残差函数F(x)只需要更新F(x)少部分的权值就可以了。
这就是ResNet的基本单元,以及为什么以残差块构成的ResNet可以避免深层网络的“退化”问题的原因。接下来,我介绍一下如何基于tensorflow构成残差块,并以残差块为基础搭建简单的ResNet,并基于CIFAR-10图像集进行图像分类的训练。
ResNet的实现
处理数据集
在本文中,搭建了一个简单的18层的ResNet[2],并基于CIFAR-10图像集进行图像分类的训练。这里,首先介绍一下CIFAR-10图像集的预处理的过程。
# 图像标准化处理,可以增加模型的泛化能力
img_mean = tf.constant([0.485, 0.456, 0.406])
img_std = tf.constant([0.229, 0.224, 0.225])
def normalize(x, mean=img_mean, std=img_std):
x = (x - mean)/std
return x
# 图像的预处理
def preprocess(x, y):
x = tf.image.random_flip_left_right(x) # 图像增强:图像随机地左右翻转
x = tf.cast(x, dtype=tf.float32) / 255. # [0,255]->[0,1]
x = normalize(x) # 标准化处理
y = tf.cast(y, dtype=tf.int32)
return x, y
# 载入数据并进行预处理
(x, y), (x_val, y_val) = datasets.cifar10.load_data() # 载入CIFAR-10图像集
y = tf.squeeze(y) # 压缩张量为1的轴
y_val = tf.squeeze(y_val)
y = tf.one_hot(y, depth=10) # 将标签转化为one-hot形式
y_val = tf.one_hot(y_val, depth=10)
train_db = tf.data.Dataset.from_tensor_slices((x,y)) # 转化为tensor方便进一步处理
train_db = train_db.map(preprocess).shuffle(10000).batch(256) # 对训练集数据进行预处理,batchsize=256
test_db = tf.data.Dataset.from_tensor_slices((x_val, y_val))
test_db = test_db.map(preprocess).batch(256)
sample = next(iter(train_db))
搭建神经网络
在本文中,通过BasicBlock类和ResNet类,搭建了一个如下结构的18层的ResNet。
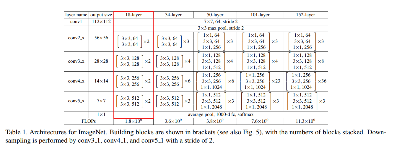
图3 红框内即所搭建的18层ResNet的结构[1]
# 残差块,即ResNet的基本单元
class BasicBlock(layers.Layer): # 主要是由两个卷积层和一条短接线组成
def __init__(self, filter_num, stride=1): # filter_num:卷积层通道数,stride:步长
super(BasicBlock, self).__init__()
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')# 卷积层1
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu') #激活函数为relu
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')# 卷积层2
self.bn2 = layers.BatchNormalization()
if stride != 1: # stride!=1需要下采样
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else:
self.downsample = lambda x:x
def call(self, inputs, training=None): # 前向传播
out = self.conv1(inputs)
out = self.bn1(out, training=training)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out, training=training)
identity = self.downsample(inputs)
output = layers.add([out, identity])
output = tf.nn.relu(output)
return output
class ResNet(keras.Model): # 构建ResNet网络
# 若layer_dims=[2, 2, 2, 2],则生成4个resblock,每个resblock有2个残差块;num_class是分成类别的数目
def __init__(self, layer_dims, num_classes=10):
super(ResNet, self).__init__()
self.stem = Sequential([layers.Conv2D(64, (3, 3), strides=(1, 1)), # 数据预处理层
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 生成4个resblock,每个resblock的卷积层的通道数分别为64,128,256,512
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2) # stride=2使得h和w逐渐变小,有降维的功能
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# output: [b, 512, h, w],h和w未知
self.avgpool = layers.GlobalAveragePooling2D() # 得到[512,1,1],即在h和w上求平均
self.fc1 = layers.Dense(num_classes, activation=tf.nn.softmax) # 全连接层,进行分类输出
def call(self, inputs, training=None):
x = self.stem(inputs,training=training)
x = self.layer1(x,training=training)
x = self.layer2(x,training=training)
x = self.layer3(x,training=training)
x = self.layer4(x,training=training)
x = self.avgpool(x)
x = self.fc1(x)
return x
def build_resblock(self, filter_num, blocks, stride=1): # 构建一个build_resblock,filter_num是残差块中卷积层的通道数,blocks是残差块的数量
res_blocks = Sequential()
res_blocks.add(BasicBlock(filter_num, stride)) # 第一个残差块可能需要下采样
for _ in range(1, blocks): # 后续的残差块不需要下采样的能力
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
# 搭建一个ResNet
model = ResNet([2, 2, 2, 2])
编译模型
使用了常用的Adam优化器,以及CategoricalCrossentropy作为损失函数。
model.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
训练模型
h = model.fit(train_db, epochs=500, validation_data=test_db, validation_freq=1)
可视化结果
模型训练过程中的数据会存放在h中,为了更好地观察迭代过程,将其可视化输出。
def plot_acc_loss(h, nb_epoch):
acc, loss, val_acc, val_loss = h.history['accuracy'], h.history['loss'], h.history['val_accuracy'], h.history['val_loss']
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.plot(range(nb_epoch), acc, label='Train')
plt.plot(range(nb_epoch), val_acc, label='Test')
plt.title('Accuracy over ' + str(nb_epoch) + ' Epochs', size=15)
plt.legend()
plt.grid(True)
plt.subplot(122)
plt.plot(range(nb_epoch), loss, label='Train')
plt.plot(range(nb_epoch), val_loss, label='Test')
plt.title('Loss over ' + str(nb_epoch) + ' Epochs', size=15)
plt.legend()
plt.grid(True)
plt.show()
plot_acc_loss(h, epochs_num) # 将损失函数和精确度随着epoch增加的变化趋势进行可视化
结果如下图所示:
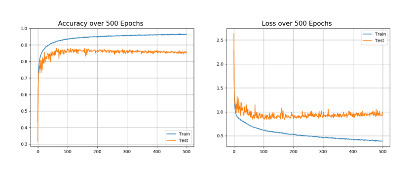
图4 模型训练过程精确度和loss的可视化图像
从图中的训练结果可以看到,随着迭数的增加,训练集准确率逐渐增加,当迭代次数超过400次后,趋向于稳定,证明模型的收敛性良好,在验证集上的精度可以接近90%,说明18层ResNet的效果良好,模型的泛化能力不错。
Reference:
[1] He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[J]. 2015.















 9537
9537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









