






本文主要三个部分:
(1)DNN如何计算字词的语义特征表示
(2)word2vec如何计算字词的语义特征表示
(3)霍夫曼对于word2vec的意义
词嵌入,就是将文本的单词嵌入数学空间中。
不同于one_hot这种暴力映射,无法衡量字词的语义空间距离。Word2vec采用的是低纬稠密矩阵去表征字词的语义关系。
但是如何才能得到每个字/词的低维稠密矩阵呢?
在谈Word2vec的做法之前,先谈谈用一般的DNN模型如何得到。
一、DNN如何计算字词的语义特征表示
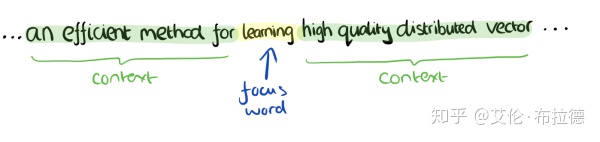
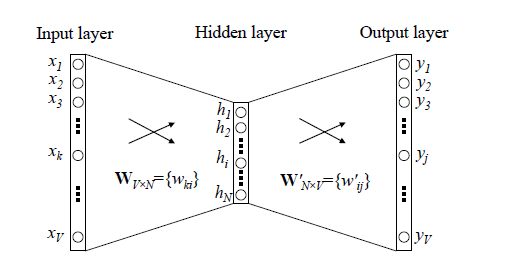
以上图为例,要得到learning的词向量,我们通过滑窗,得到learning前4个单词和后4个单词,并将其转换为one_hot编码作为输入,通过隐藏层输出层,最后softmax预测learning的词向量,预测的值与实际的learning的one_hot编码进行误差计算,从而得到优化函数,通过梯度下降,从而得到隐藏层的权重系数矩阵。

而要求的正是隐藏层的权重系数矩阵,权重系数正是文本中各个词的词向量。
二、word2vec用于计算字词的语义特征表示
相比于DNN的做法,word2vec有很大的不同,甚至可以说面目全非。以CBOW模型为例。
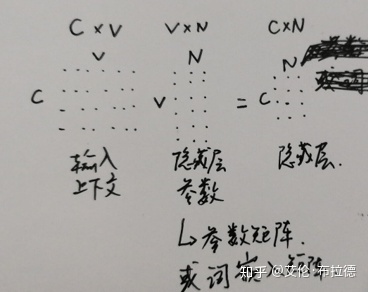
首先,DNN有输入层(输入为one_hot编码)、隐藏层(参数正是要求得的词向量)、输出层(sotfmax)。
1) 输入层,word2vec采用累加求和取平均的方式,而输入也不再是one_hot,而是随机初始化的。

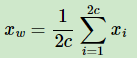
2) 没有了隐藏层,取而代之的是投影层,也就是输入的累加求和的结果。这和DNN就已经有本质上的不同了,我们前面说了隐藏层的参数值正是最后要求得的词向量,那word2vec如何得到每个字词的词向量(或者说语义特征表示)呢?后面在梯度上升的时候会提到,累加求和的Xw会作为变量进行梯度优化,最后去更新每个输入的随机初始化的向量(也就是上面公式的Xi),更新到最后的向量就是最终要求得语义特征表示。
3) word2vec为了解决输出层高维的softmax概率分布(从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值),采用了最优二叉树——霍夫曼树。

下面详细介绍霍夫曼树是如何在word2vec中发挥作用的。
三、 霍夫曼对于word2vec的意义
本节参考:
深入学习二叉树(三) 霍夫曼树www.jianshu.com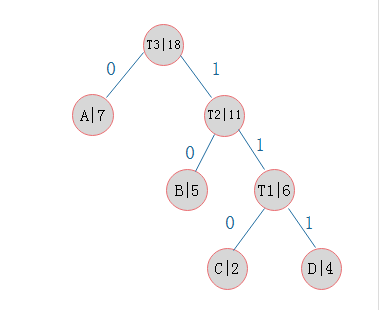

A,B,C,D为叶子节点,每个叶子节点均有权重,而霍夫曼树则是每次合并两个权重最小的节点,最终到达根节点。
而在word2vec中,为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。
正如上文所述,霍夫曼树之于word2vec最大的意义是降低softmax计算量,如何实现这一目的的呢?
Word2vec中的霍夫曼树叶子节点为词汇表中的词,权重为该词的词频,这样离根节点最近的就是词频最大的节点,而词频越大,softmax的概率最大的机率也就越大,也就是神经网络输出层softmax后概率最大的就越可能是词频最大的词,这样路径也就越短,计算量就越小(因为词频越大,越靠近根节点,路径自然就越短,连乘的次数就越少,计算量自然就越小),这是一种贪心策略。
简单来说,我们希望找到输入概率最大的输出,而现在隐藏层到输出层已经被构建成一棵霍夫曼二叉树,那么词频越高的词越有可能是这个输入的输出,计算量相比于词频低的词更小。
通过标注数据相当于我们已经知道叶子节点是哪个,在输入与输出都已知的情况下,我们只需要让这条路径发生的可能性最大就行了。

那么应该如何去度量某条路径发生的概率呢?
在word2vec中,要到达某个叶子节点到底是沿着左叉树还是右叉树是通过simoid函数来确定,并且约定左子树编码为1(负类-),右子树编码为0(正类+),同时约定左子树的权重不小于右子树的权重。
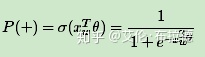
其中Xw是当前内部节点的词向量,而θ则是我们需要从训练样本求出的逻辑回归的模型参数。而负类的概率P(−)=1−P(+)。
那么上图W2的输出概率为:
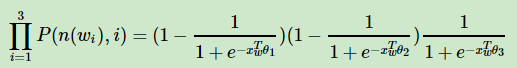
到这里应该就很简单了,概率最大下的参数估计,用最大似然估计计算就好了。
更为一般化的公式:
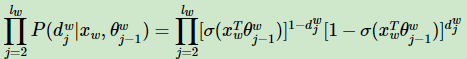
接下来,就可以通过梯度上升法来更新我们的θ和Xw,从而更新Xi,得到最终的每个字词的词向量表示。
















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









