





最近在看王喆的机器学习笔记
王喆的机器学习笔记zhuanlan.zhihu.com
发现大部分推荐系统的特征表示都变为了embedding形式(万物皆可embedding), item2vec是根据word2vec演变而来的,因此想仔细的梳理word2vec原理以及优化方法,这篇首先介绍了word2vec的原理。
参考资料:
李宏毅 word embedding/ cs224n word2vec/ Ali Ghodsi, Lec 12-Lec13(非常推荐)/word2vec Parameter Learning Explained
正文笔记开始
one-hot向量
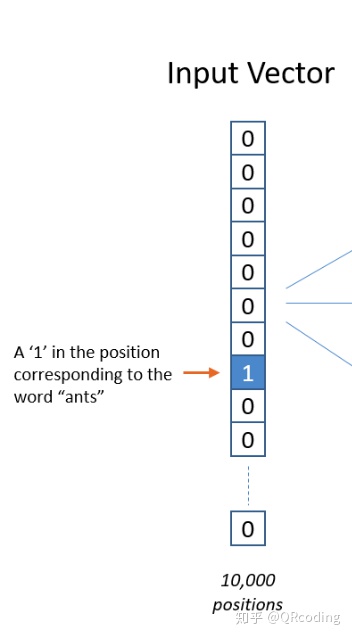
首先来介绍one-hot向量,主要原因是,word2vec的input/output都是将单词作为one-hot向量来表示,我们可以把word2vec认为是词的无监督学习的降维过程。
何为one-hot?就是我们可以认为ants这个单词在索引i处,那么假设我们的词库有10000个词,对于one-hot向量来说,除了i-index的值为1以外,其余都为0。
我们为什么不直接用one-hot 向量来表示词,反而需要将词降维表示呢?
- 通常英文单词/中文词汇都很大,one-hot构造起来的vector就会随着词汇的增多越来越大。
- one-hot词向量⽆法准确表达不同词之间的相似度。由于任何两个不同词的one-hot向量的余弦相似度都为0,多个不同词之间的相似度难以通过onehot向量准确地体现出来。
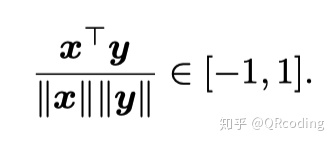
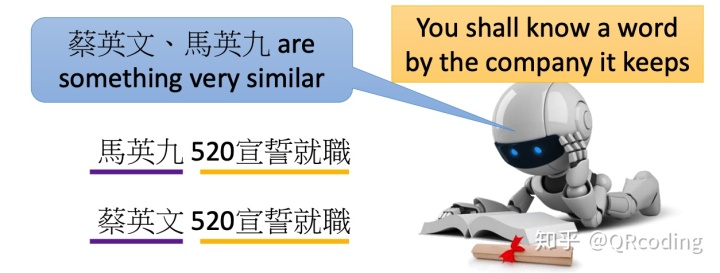
下面我要介绍一个非常主要的现代自然语言处理的思想:一个词汇的意思是通过它周边经常出现的词得到的(A word’s meaning is given by the words that frequently appear close-by),因此我们可以让模型自己在无监督的状态下通过阅读上下文来学习到词与词之间相近的意思。word2vec也是由这一思想指导诞生的~

Note: word vectors are sometimes called word embeddings or word representations. They are a distributed representation.
word2vec
CBOW 连续词袋模型
连续词袋模型假设基于某中⼼词在⽂本序列前后的背景词来⽣成该中⼼词。在⽂本序列... problems turning into banking crises as ...⾥, 以“into”作为中⼼词, 且背景窗口⼤小为2时,连续词袋模型关⼼的是,给定背景词problem turning banking crises⽣成中⼼词into的条件概率。
skip-gram model 跳字模型(一般文章说到word2vec泛指这个模型)
跳字模型假设基于某个词来⽣成在它⽂本序列周围的词。 举个例⼦, 假设⽂本序列是 ... problems turning into banking crises as ...。以“into”作为中⼼词,设背景窗口⼤小为2。 跳字模型所关⼼的是, 给定中⼼词“into”,⽣成与它距离不超过2个词的背景词problem turning banking crises的条件概率。
word2vec的浅层神经网络模型解析(math warning):
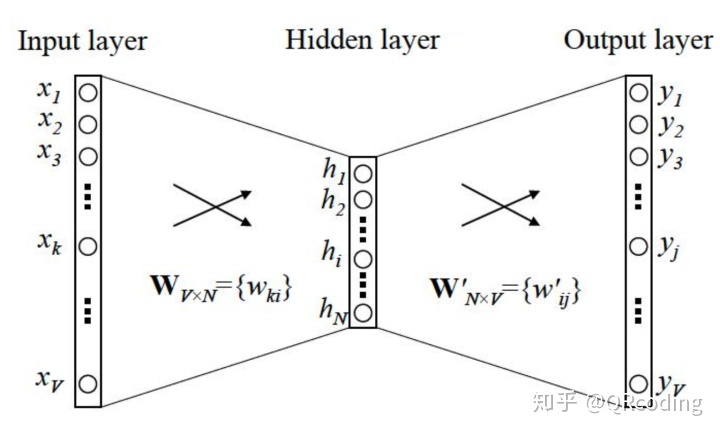
无论是词袋模型还是跳字模型我们都可以用上述图表示,以词袋模型(CBOW)为例。
为了方便阐述,我们假设背景词只有一个,来预测下一个单词。
V 代表词典索引集, N代表隐藏层的神经元数量,即词将会降维成N, 隐藏层
由于X是one-hot向量,因此对于任意一个单词来说只有一个索引k上的值不为0,因此H等于
我们用
对于output layer的每一个neural我们都有
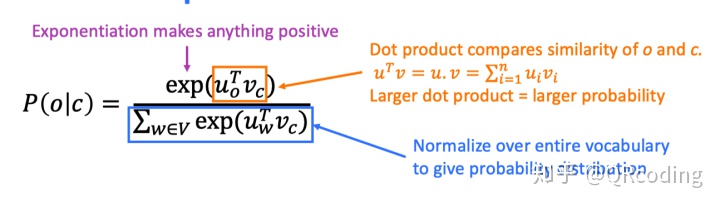
接下来我们希望在给定所有背景词的前提下,可以最大可能性的出现该中心词,最大似然Maximize Likelihood,来使得P(o|c)概率值最大。

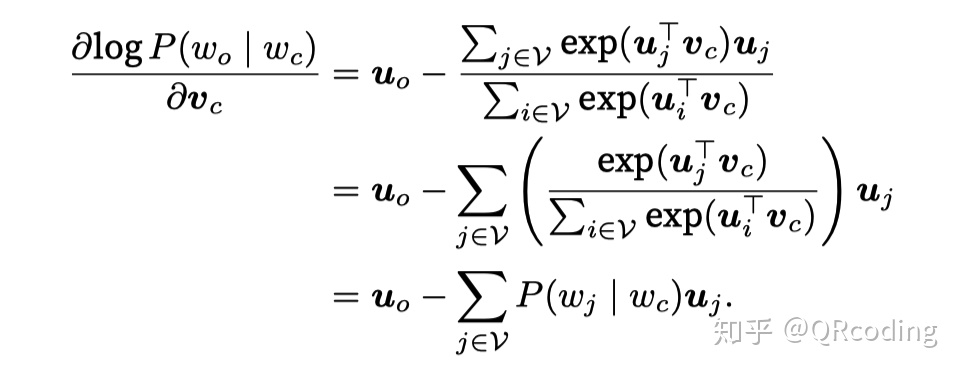
这个公式虽然理论上可以利用梯度下降来求解,但由于词汇量V太大,时间消耗太多,因此一般使用hirerachical softmax,nagative sampling等方法进行优化。















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









