





数据集成的的目的是把多个数据存储器(数据库)的数据集中合并在一个数据存储器(数据库)中。因此,在数据集成过程中要考虑以下几个问题:
(1)数据来源可能为数据库、数据立方体、excel 表格、txt 文件等,或者为这些数据不同数据源格式的混合来源。 本章研究的目的是将其应用在实际工程中(具体工程项目将在第 5章中详细阐述),应当根据实际情况,因地制宜。由于所研究的实际问题的数据来源都存在各个工控机的数据库中,因此其来源格式单一,读取方式简单,我们在对这些不同来源的数据进行合并时只需考虑把所需要的数据按照时间相近的关系进行合并,同时对这些合并后的数据进行重新编号(重新定义主键);对于采集频率不同的数据我们仅需将其按照最高频率的数据项进行合并。
(2)数据集成时还要注意检查是否存在数据的值冲突的现象,即有可能同一个数值在单位的表述方式不同而已。 对于该种情况,我们在进行数据合成时要对数据的语义进行适当的分析,确保合成后的数据不存在数据的值冲突的现象。
(3)由(1)中可以看出,数据来源多样,这也不可避免的出现数据冗余的问题,即如果 A 属性可以由另外一个或几个属性推导出,则 A 属性为冗余属性,应该删除。 为了进行数据在集成时对冗余的属性进行删除,在这里引入相关分析(Correlation Analysis)的概念。
1. Pearson属性约简法
相关性分析是英国统计学家 Pearson(皮尔逊)提出的,该分析方法也称为积差相关或积矩相关。 假定在数据集成时有 A 和 B 两个属性,则这两个属性的相关度为:
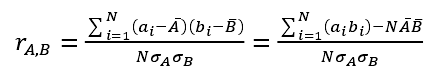
(1)


图.1 相关系数示意图
相关性可以表示输入与输出之间的相关度,也可以表示输入与输出、输出与输出的相关度,根据计算相关度的方式不同,其取舍也截然相反。 如果计算的是输入与输入、输出与输出的相关度,则相关度越高,说明这两者属于冗余属性,应当舍弃一个;如果计算的是输入与输出的相关度,则相关度越高,说明两者紧密相关,应当保留,在实际情况中应当根据分析的对象合理选取。 另外,除了皮尔逊分析法外,邻域粗糙集属性约简算法也可进行相关度分析。与皮尔逊方法相比,邻域粗糙集属性约简算法有个优势,即:皮尔逊分析法一次只能进行两个属性(一个输入属性与一个输出属性、一个输入属性与一个输入属性或者一个输出与一个输出属性)分析,而领域粗糙集可以同时对多个属性(多个输入属性与一个决策属性)进行分析,下面对邻域粗糙集属性约简算法进行简单阐述。
2. 邻域粗糙集属性约简算法

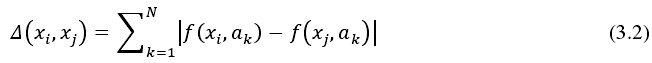
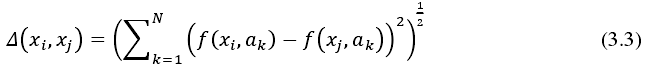
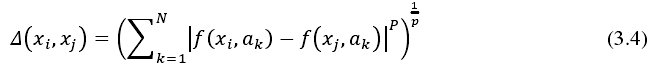

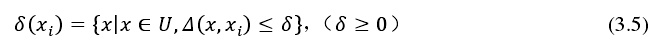

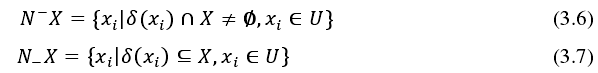
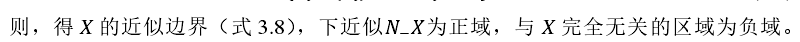
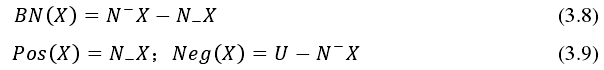
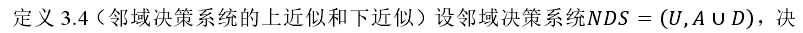
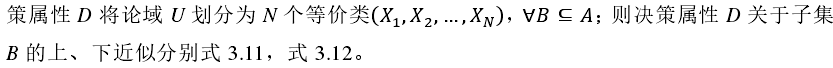
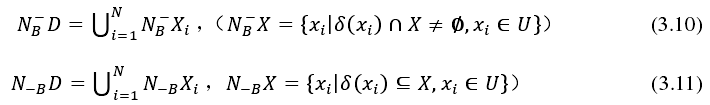
同理得,决策系统的边界、邻域决策系统的正域和负域分别为式 3.13~式 3.15。
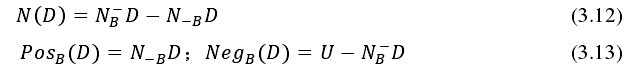
决策 D 对条件 B 依赖度:

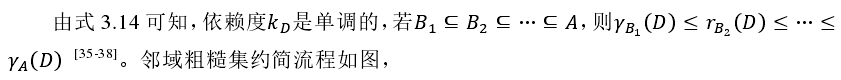
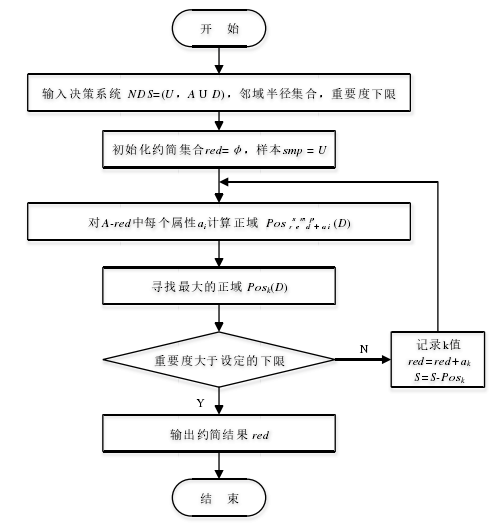
图 1 前向贪心约简算法
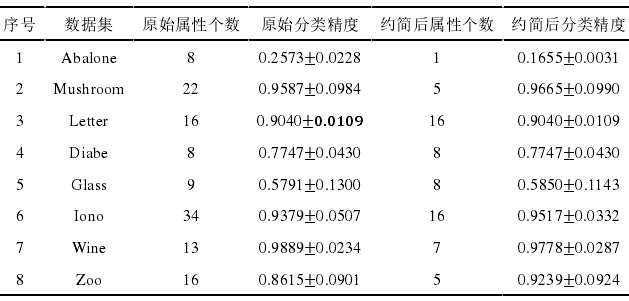
该算法用在属性约简上比较有效,这一结论已在文献[35]中给出,其验证数据来源于 UCI 数据集(表1),其属性简约后的结果见表2。
表 1 数据集描述

表 2 约简后属性数与分类性能比较
《来源于科技文献,经本人分析整理,以技术会友,广交天下朋友》
石显:数据挖掘中海量数据的预处理——数据的降噪zhuanlan.zhihu.com














 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









