






0 前言
作为一名数据分析小白,经过一轮融汇贯穿学习后,也迫不及待想做一份数据分析报告,于是选取了现阶段最感兴趣的数据分析相关岗位招聘信息进行一波数据分析。
1 理解问题
确定分析的目的和方向
因为目前正在转型成为一名数据分析师的路上,希望找些项目练练手,熟悉数据分析的完整流程,但又想着一箭双雕,项目输出的结果能够服务于己,因此最终选择了对招聘数据做分析,并从中窥探该行业的冰山一角(看下把自己拎到市场上能卖多少钱)并挖掘有利于自身发展的关键信息(怎样才能卖个好价格)。
2 理解数据
结合业务,对数据透彻理解
此次获取的数据是在GitHub上看到的爬虫项目:招聘网站爬虫,没做太多改动就应用上了,爬取的是「前程无忧」含“数据分析”关键词近两个月的招聘信息,地点选取了两处:广州、深圳,最后一共爬取了5.2W+条数据,广深各占一半。
ps_1:这里为何没有选取各发展水平的代表城市,只因纯属个人喜好,钱多离家近,事少不少就布吉岛(是份带有个人感情的数据分析报告)
ps_2:本来打算把大湾区也带上,无奈发现除广深外整个珠三角的招聘数据加起来与广深都不是同一个量纲就放弃了
首先预览下数据概况:
cv.info()
cv.head()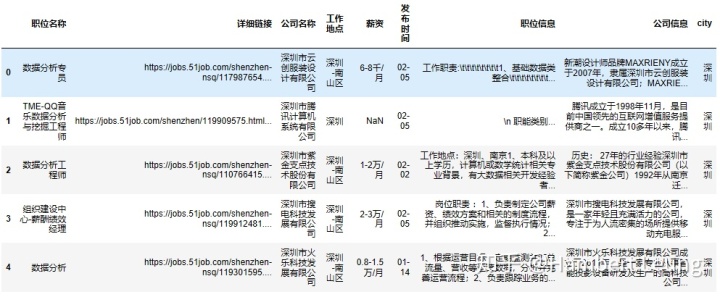
可以发现:
- 薪资、发布时间、职位信息有部分缺失值;
- 发布日期缺失年份信息,存在跨年时不便于排序;
- 薪资一列,格式不统一,而常见薪资单位为 千/月;
于是理解数据后进入下一环节:数据清洗。
3 数据清洗
对数据进行预处理,包括缺失值、异常值和重复值的处理
- 重复值处理;考虑到同一条招聘可能会多次发布,因此去重时以 职位名称+公司名称 为唯一索引,进行去重处理,并保留最新记录:
cv.drop_duplicates(['职位名称','公司名称'], keep='first', inplace=True)- 缺失值处理:首先计算缺失率,发现薪资一列的缺失率为1.55%左右,占比较少;
cv.apply(lambda x: np.sum(x.isnull()) / len(x))['薪资']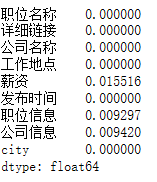
故作删除薪资缺失记录处理:
cv.dropna(subset=['薪资'], how='any', inplace=True)而对于职位信息、公司信息的缺失值,由于存在相应的薪资数据,不做删除处理,而是用“暂无”填充;同时对职位信息做转化为小写处理,方便后续文本匹配。
cv['职位信息'] = cv['职位信息'].fillna('暂无').str.lower()
cv['公司信息'] = cv['职位信息'].fillna('暂无')- 异常值处理:重点关注薪资一列,先来看下目前的格式统计情况:
cv['薪资'].str[-3:].value_counts(normalize = True)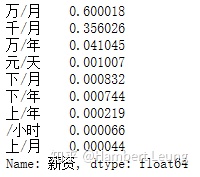
考虑到招聘信息中可能包含部分实习岗位,不在本次分析范围内,故做删除处理(考虑到删除操作的重复调用,故定义了删除函数drops(col, tag);
def drops(col, tag):
cv.drop(cv[cv[col].str.contains(tag)].index, inplace=True)
drops('职位名称', '实习') 由于主流的工资标签格式都是前三类,因此删除其余格式的记录:
drops('薪资', '元/天'); drops('薪资', '/小时'); drops('薪资', '下/月'); drops('薪资', '上/月'); drops('薪资', '下/年'); drops('薪资', '上/年');薪资列的类型是文本,不方便做统计分析,因此进行文本处理,分离出薪资下限、薪资上限、薪资标签,计算薪资均值,并统一以 千/月 为基准单位:
# 添加薪资标签,区分年薪和月薪,薪资单位千和万
# ['万/月':0, '万/年':1, '千/月':2]
cv['salary_tag'] = np.where(cv['薪资'].str.contains('年'), 1, np.where(cv['薪资'].str.contains('千'),2 ,0))
cv['divisor'] = np.where(cv['薪资'].str.contains('年'), 12, np.where(cv['薪资'].str.contains('千'),10 ,1))
cv['salary_min'] = (cv['薪资'].apply(lambda x: str(x).split('-')[0]).astype('float') / cv['divisor'] * 10).astype('int')
cv['salary_max'] = (cv['薪资'].apply(lambda x: str(x).split('-')[1][:-3]).astype('float') / cv['divisor'] * 10).astype('int')
cv['salary_unit'] = cv['薪资'].apply(lambda x: str(x).split('-')[1][-3:])
cv['salary_avg'] = (cv['salary_min'] + cv['salary_max']) / 2通过观察升序后的薪资尾部数据,发现有部分异常大的离群值(个数均为1),因此删除部分离群值,便于后续分析统计与展示;
# 删掉部分离群值,薪资下限高于30k的,占比为0.59%
print(cv['salary_min'].value_counts().tail(10))
#print((round((cv[cv['salary_min'] > 30]['salary_min'].count() / cv.shape[0] * 100), 2)).astype('str') + '%' ) #Out: 0.59%
cv.drop(cv[cv['salary_min'] > 30].index, inplace=True) 
至此,数据预处理暂告一段落。
数据分析和可视化
按照相关方法,对数据进行分析并通过可视化展示结果
- 考虑到招聘单位往往按薪资区间的下限开工资,因此后续分析薪资时主要以薪资下限(对应列 cv['salary_min'] )做分析;
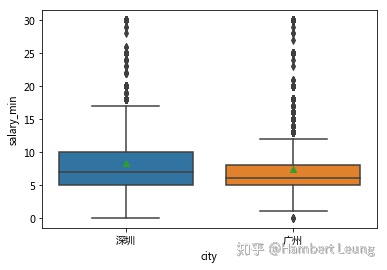
- 通过按城市分类展示箱图发现,深圳的薪资表现整体都要优于广州;虽下四分位数持平,但其余指标深圳的表现均超过广州,说明数据分析相关的起步工作两地薪资持平,但发展空间和天花板实属深圳占优。
- 以薪资下限与上限为坐标,以城市为分类变量绘制散点图,观察薪资定位情况;可以发现,同样的薪资下限,深圳在薪资上限的表现会更加突出
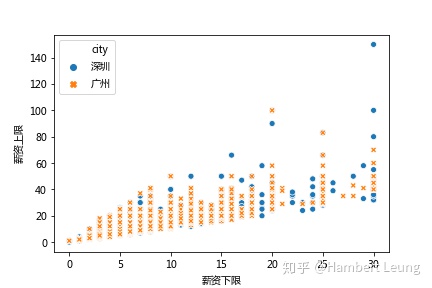
- 从散点图也可以看出,薪资区间定位较为散乱,因此考虑对薪资利用cut()进行月薪重分类,分区方式参考“前程无忧”的过滤条件(此处区间为左闭右开,如 8-10 为 8k ≤ x<10k)
cv.salary_min.sort_values()
bins = [0, 2, 3, 4.5, 6, 8, 10, 15, 20, 30]
level = ['0-2','2-3','3-4.5','4.5-6','6-8','8-10','10-15','15-20','20-30']
cv['level'] = pd.cut(cv['salary_min'], bins = bins, labels=level, right=False) #right=False表示左闭右开
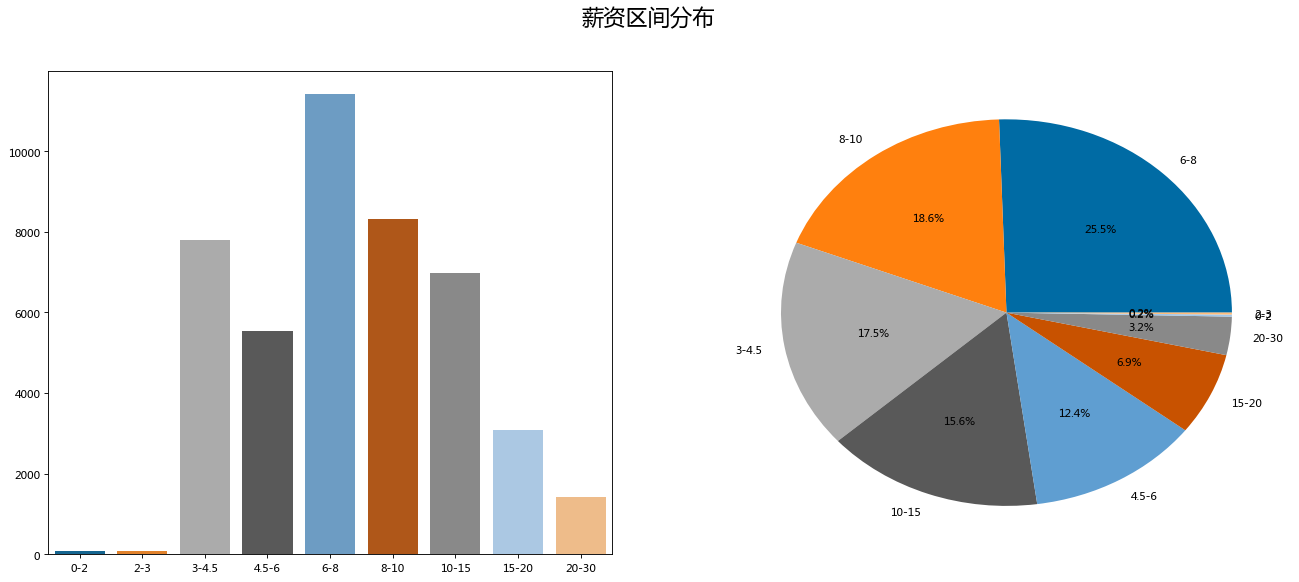
cv_level = cv['level'].value_counts()- 对重采样后的薪资区间进行分类统计,可以发现,整体薪资分布符合721原则,即TOP 20%,中间70%,末尾10%;6-8k的月薪分布最多,占据了四分之一。
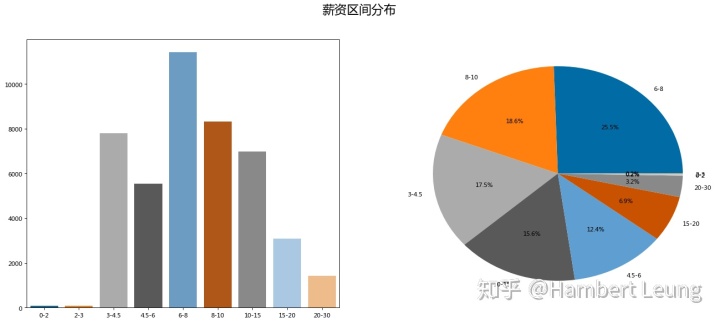
- 若将城市分类加入区间分布图,绘制叠加柱状图,结论大体如箱图所示
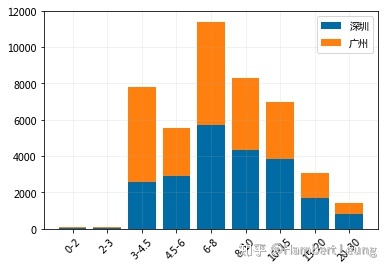
- 做完了薪资整体分布的概览以及按城市分类对比后,发现“数据分析”岗位并没有想象中高薪,8k以下的月薪占比超过半数(55.43%),不过万的月薪占比更是接近四分之三(73.92%),那么究竟“月薪过万的数据分析师”是否唬人呢?
print('%.2f%%' %((cv[cv['salary_min'] < 8].count() / cv.shape[0])['salary_min'] * 100))
print('%.2f%%' %((cv[cv['salary_min'] < 10].count() / cv.shape[0])['salary_min'] * 100))
cv['salary_min'].describe()- 挑选发布“数据分析”相关的职位名称用词频率前20名进行观察,发现大多数岗位都不符合“数据分析师”的头衔,但回到开头数据源的获取阶段,抓取的是含“数据分析”关键词的职位,而“数据分析”这个概念本身就非常宽泛,因为在实际工作中和数据打交道是司空见惯的事情,难易不同,主辅不同,工作性质不同,都会使得“数据分析”这项技能的实际应用有所不同。
cv.groupby(by=['职位名称'])['职位名称'].count().sort_values(ascending=False).head(20)
- 因此考虑对职位名称的判断,添加分类变量列,来区分不同种类的工作:
- 数据挖掘、算法工程师为一类,理解为偏技术数据分析类岗位(下简称挖掘岗);
- 数据分析、BI、数据运营为一类,理解为偏业务数据分析类岗位(下简称分析岗);
- 其余的判断为非数据分析类岗位(下简称其他岗)
# 对职位进行重分类:数据挖掘|算法 == 2, 数据分析|数据运营|BI == 1, 其余 == 0
is_skill = re.compile(r'数据挖掘|算法')
is_analyst = re.compile(r'数据分析|数据运营|BI')
cv['job_type'] = np.where(cv['职位名称'].apply( lambda x: is_skill.search(x) != None ), 2,
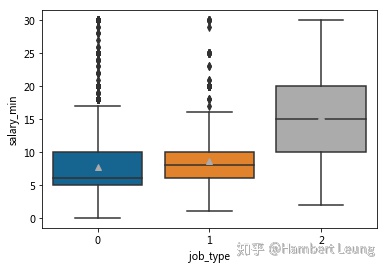
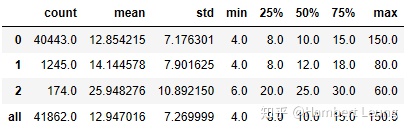
np.where(cv['职位名称'].apply( lambda x: is_analyst.search(x) != None ), 1, 0))- 经过重新分类后,value_counts()的结果为:挖掘岗有174条、分析岗有1245条、其他岗为40443条;结合箱图分析,挖掘岗的整体表现远超过其余两类岗位,而分析岗相较于其他岗的起步更高,不过从高薪层面看则差距不大;
- 通过pandas的describe()也能反映不同职位类别的对比情况;回到刚提出的问题,数据分析工作是否稳妥月薪过万呢?从中位数的情况来看(此处不分析平均值,是因为预处理时删除了部分月薪过高的离群值,平均值可能偏低,但对中位数影响较小),并不乐观,分析岗的中位数仅为8k;
def salary_type_desc(col):
type = cv.groupby('job_type')[col].describe()
all = pd.DataFrame(cv[col].describe()).T
all.index = ['all']
return pd.concat([type, all])
# 按职位分类的月薪统计信息(薪资下限)
salary_type_desc('salary_min')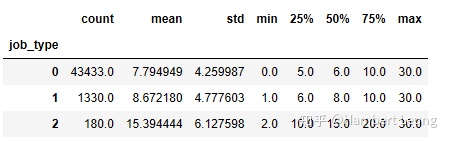
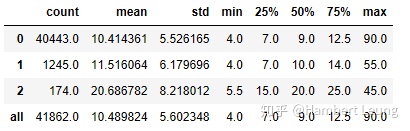
- 于是掏出了沉箱底已久的薪资均值、薪资上限,发现月入过万这个指标藏在了分析师的「薪资均值」中位数,以及“数据分析”相关岗位「薪资上限」中位数里。
- 既然已经知道高薪往哪找,那么就来看看如何往心仪的岗位靠拢。首先尝试统计出常见技能的出现频次并绘制柱状图,可以发现排名前十的分别是:EXCEL、PPT、SQL、Python、MySQL、Hadoop、Oracle、SPSS、Spark、HIVE;
#关键词搜索函数封装,传入关键词列表,输出计数列表
def key_list_search(key):
cnt = []
for i in range(0, len(key)):
cnt.append(cv[cv['职位信息'].str.contains(key[i])]['职位信息'].count())
return cnt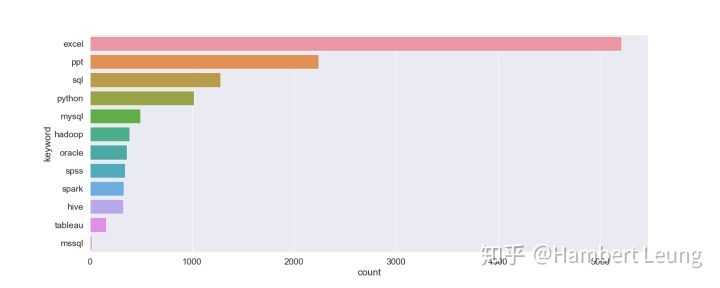
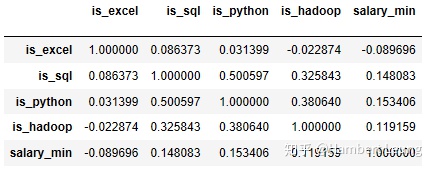
- 那么技能要求究竟和薪资是否挂钩呢?不妨来对技能与薪资的相关性进行评估,此处挑选了四大技能EXCEL、SQL、Python、Hadoop作为二分类变量,通过相关系数来评估相关性。
#定义匹配函数,挑选四个主流技能观察相关性
def is_match(col, key):
return cv[col].str.contains(key)
cv['is_sql'] =np.where(is_match('职位信息', 'sql'), 1, 0)
cv['is_python'] =np.where(is_match('职位信息', 'python'), 1, 0)
cv['is_hadoop'] =np.where(is_match('职位信息', 'hadoop'), 1, 0)
cv['is_excel'] =np.where(is_match('职位信息', 'excel'), 1, 0)
cv[['is_excel', 'is_sql', 'is_python', 'is_hadoop', 'salary_min']].corr(method = 'spearman') - 结果显示,四大技能均呈若弱相关,其中正相关性强弱排名为 Python ≥ SQL > Hadoop,而EXCEL呈现负相关;另外,值得注意的是 SQL 和 Python 通常在招聘要求上经常成对出现(其相关系数高达0.5)
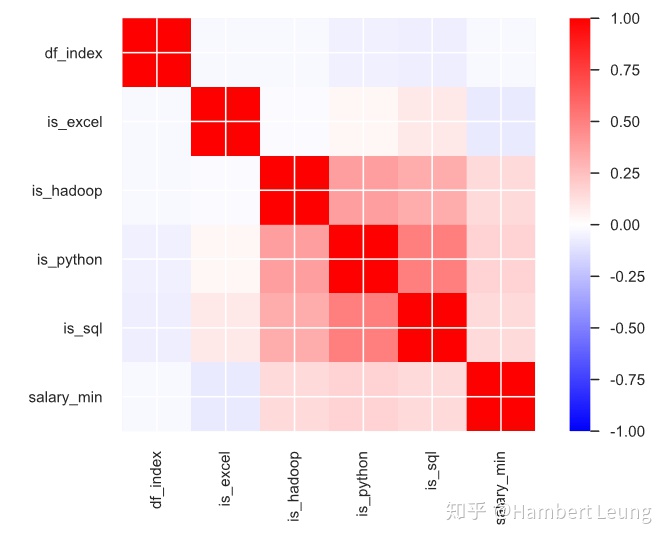
同样地,也将相关系数矩阵可视化(此处利用的是pandas_profiling)
结论和建议
根据结果得出结论并提出有价值的建议
- Q1:数据分析师真的月入过万吗?
- A1:既假亦真。假就假在以偏概全,准确来说,应是数据分析师的「薪资均值」中位数过万,也可以说“数据分析”相关岗位「薪资上限」中位数过万;但按照实际市场供求,数据分析师的「薪资下限」中位数并未过万。
- Q2:广深两地哪家好?
- A2:刚起步不纠结,有好机会就上,想要做大做强还是在深圳为妙。
- Q3:(偏业务)数据分析师必备技能?
- A3:
- EXCELPPTSQLPython是四大天王;
- 而且对SQL有要求的企业,通常也要求会Python;
- 技能与薪资不具备强相关性,但技能永远只是辅助,数据敏感和熟悉业务才是王牌。














 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









