







目录
1.TreeSet,LinkedHashSet,TreeSet的区别
概要
List:ArrayList LinkedList
Set:HashSet,LinkedHashSet,TreeSet
Map:HashMap,LinkedHashMap,TreeMap,HashTable
一,集合之间的继承关系

二,List接口
1.List特点
- List是有序的
- List允许插入重复值
- List提供了特殊迭代器Listlterator,改迭代器允许元素插入和替换
2.List子类
- List的实现类有:Vector,ArrayList,LinkedList
(1)ArrayList
- ArrayList是基于数组实现的List类。它封装了一个动态的,增长的,允许再分配的Object[]数组。
- ArrayList适合随机查询和遍历,不适合插入和删除。
(2)Vector
- Vector也是基于数组实现的List类,不同的是它支持线程同步。即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性。因此访问比ArrayList比较慢,已经不常用了。
- Stack(类):是vector提供的一个子类,用于模仿“栈”这种的数据结构(后进先出)
(3)LinkedList
- LinkedList是用链表结构存储数据的。
- LinkedList适合插入删除数据,不适合随机查询和遍历。
- Deque(接口):专门用于操作表头表尾数据,可以当做堆栈,队列和双向队列使用
三,Set接口
1.Set特点
- Set是无序的
- Set是不允许重复值的
2.Set的子类
- Set的实现类有:HashSet,TreeSet,LinkedHashSet(继承HashSet)
(1)HashSet(无序,唯一)
- Hashset是使用Hash算法来存储集合的元素的,因此具有良好的存取和查找性能。当HashSet集合中存入一个元素的时,HasSet会调用改对象的HashCode值,然后根据HashCode来决定该对象在HashSet的存储位置。
- HashSet判断两个元素是否相等是根据equals()方法比较相等,并且两个对象的HashCode()方法的返回值相等。
(2)LinkedHashSet(FIFO插入有序,唯一)
- LinkedHashSet也是根据HashCode值来决定元素位置,但和HashSet不同的是,它同时使用链表维护元素次序,这样元素就是以插入顺序进行保存的。
- 当遍历LinkedHashSet集合的时,LinkedHashSet会将按元素的添加顺序来访问集合里的元素。
- LinkedSet适合遍历
(3)TreeSet(有序,唯一)
- 因为实现SortedSet接口,底层数据结构是红黑树,TreeSet可以确保集合元素处于排序状态。
- 自然排序
- 比较器排序
三,Queue
此接口用于模拟队列数据结构(FIFO)。新插入的元素放在队尾,队头存放着保存时间最长的元素。
1.Queue的子类
(1)PriorityQueue 优先队列
- 按照队列中某个属性大小进行排序
(2)Deque 双端队列
(2.1)ArrayDeque
基于数组实现的双端队列,类似ArrayList中有一个Object[]数组
(2.2)LinkedList
四,Map接口
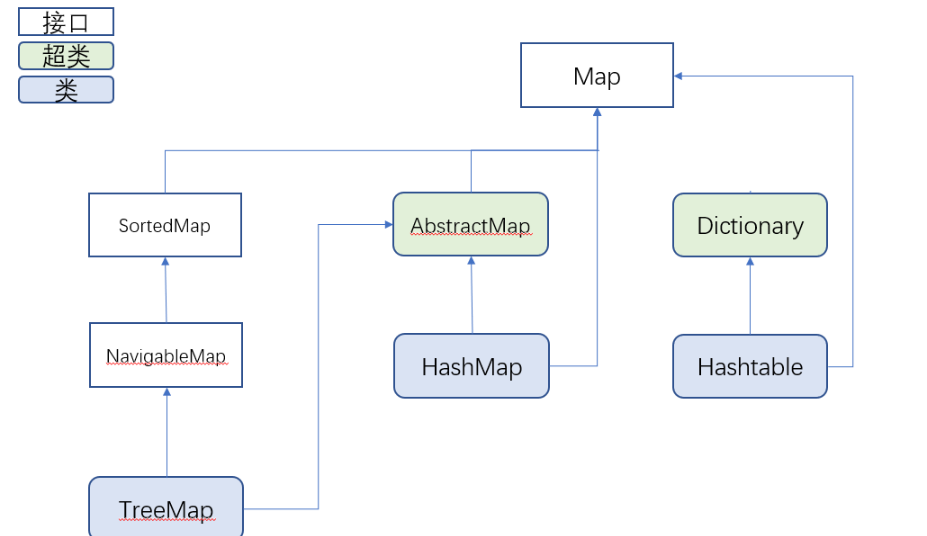
1.Map特点
- Map不是collection的子接口或者实现类。Map是一个接口。
- Map用于保存具有映射关系的数据。key-value,其中key不能有重复值。
- Map可以有多个Value为null,但是只能有一个key为null。
2.Map的子类
(1)HashMap(无序)
- HashMap是无序的。key是根据HashSet实现的,两个key是通过equals()方法比较返回为true,同时两个key的hashCode相等。
(1.1)LinkedHashMap
LinkedHashMap是根据双向链表来维护key-value对的次序的。
(2)HashTable(无序)
HashTable与HashMap的区别:
- HashTable的方法是同步的,HashMap的方法是不同步的。
- HashTable是线程安全的,HashMap不是线程安全的。
- HashTable的效率低,HashMap的效率高。(如果对同步性或与遗留代码的兼容性没有要求,建议使用HashMap。其中HashTable的所有public方法声明都有synchronized关键字,而HashMap没有)
- HashTable不允许有Null值,HashMap允许有Null(key和value都允许)
- 父类不同:HashTable的父类是Dictionary,HashMap的父类是AbstractMap
(3)SortedMap(接口)
(3.1)TreeMap(有序)
TreeMap是一个红黑树接口,每个键值对都作为红黑树的一个节点。TreeMap存储键值对时,根据key来对节点进行排序。TreeMap可以保证所有的key-value处于有序状态的。
重点分析
1.TreeSet,LinkedHashSet,TreeSet的区别
- TreeSet的主要功能用于排序(不允许插入Null数据)
- LinkedHashSet的主要功能用于保证FIFO,即有序的集合(先进先出)
- HashSet只是通用的存储数据的集合
2.TreeSet的两种排序的比较
1.排序的引入(以基本数据类型的排序为例)
public class Study {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet();
set.add(5);
set.add(1);
set.add(3);
set.add(2);
set.add(9);
set.add(12);
set.add(11);
set.add(10);
for(Integer i : set){
System.out.println(i);
}
}
}
运行结果:
1
2
3
5
9
10
11
12
2.基本类型排序
public class Study {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet();
set.add(new Person(1,"A"));
set.add(new Person(6,"B"));
set.add(new Person(9,"C"));
set.add(new Person(10,"D"));
set.add(new Person(4,"E"));
set.add(new Person(3,"F"));
set.add(new Person(2,"G"));
set.add(new Person(2,"A"));
for(Person i : set){
System.out.println(i);
}
}
}
运行结果:
Exception in thread "main" java.lang.ClassCastException: Person cannot be cast to java.lang.Comparable
at java.util.TreeMap.compare(TreeMap.java:1294)
at java.util.TreeMap.put(TreeMap.java:538)
at java.util.TreeSet.add(TreeSet.java:255)
at Study.main(Study.java:6)
程序会报错,因为TreeSet不知道根据什么去排序
解决办法:
1.自然排序
2.比较器排序
(1)自然排序
自然排序要进行一下操作
- Person类中实现Comparable接口
- 重写Comparable接口中的Compareto方法
Compareto比较此对象与指定对象的顺序
public class Person implements Comparable<Person>{
int id;
String name;
public int compareTo(Person p) {
//return -1; //-1表示放在红黑树的左边,即逆序输出
//return 1; //1表示放在红黑树的右边,即顺序输出
//return o; //表示元素相同,仅存放第一个元素
//主要条件 姓名的长度,如果姓名长度小的就放在左子树,否则放在右子树
int num = this.name.length()-p.name.length();
//姓名的长度相同,不代表内容相同,如果按字典顺序此 String 对象位于参数字符串之前,则比较结果为一个负整数。
//如果按字典顺序此 String 对象位于参数字符串之后,则比较结果为一个正整数。
//如果这两个字符串相等,则结果为 0
int num1 = num==0?this.name.compareTo(p.name):num;
//姓名的长度和内容相同,不代表年龄相同,所以还要判断年龄
int num2 =num1==0?this.id-p.id:num1;
return num2;
}
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
运行结果:
Person{id=1, name='A'}
Person{id=2, name='A'}
Person{id=6, name='B'}
Person{id=9, name='C'}
Person{id=10, name='D'}
Person{id=4, name='E'}
Person{id=3, name='F'}
Person{id=2, name='G'}
(2)比较器排序
步骤:
- 单独创建一个比较类,这里以MyComparator为例,并且要让其继承Comparator接口
- 重写Comparator接口中的Compare方法
compare(T o1,T o2) 比较用来排序的两个参数
测试类:
import java.util.TreeSet;
public class Study {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<Person>(new MyComparator());
set.add(new Person(1,"A"));
set.add(new Person(6,"B"));
set.add(new Person(9,"C"));
set.add(new Person(10,"D"));
set.add(new Person(4,"E"));
set.add(new Person(3,"F"));
set.add(new Person(2,"G"));
set.add(new Person(2,"A"));
for(Person i : set){
System.out.println(i);
}
}
}
Person.java
public class Person {
int id;
String name;
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
MyComparator.java
import java.util.Comparator;
public class MyComparator implements Comparator<Person> {
public int compare(Person p1, Person p2) {
//姓名长度
int num = p1.getName().length() - p2.getName().length();
//姓名内容
int num2 = num==0?p1.getName().compareTo(p2.getName()):num;
// ID
int num3 = num2==0?p1.getId() - p2.getId() : num2;
return num3;
}
}
运行结果:
Person{id=1, name='A'}
Person{id=2, name='A'}
Person{id=6, name='B'}
Person{id=9, name='C'}
Person{id=10, name='D'}
Person{id=4, name='E'}
Person{id=3, name='F'}
Person{id=2, name='G'}
3.List去重
(1)LinkedHashSet去重
public class Study {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>(){{
add(1);
add(5);
add(2);
add(6);
add(5);
add(5);
add(4);
add(3);
add(2);
add(1);
}};
LinkedHashSet<Integer> set = new LinkedHashSet<Integer>(list);
for(int i : set){
System.out.print(i);
}
}
}
运行结果:
152643
(2)Stream去重
public class Study {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>(){{
add(5);
add(4);
add(3);
add(9);
add(10);
add(6);
add(4);
add(3);
add(15);
}};
List<Integer> lisdis = list.stream().distinct().collect(Collectors.toList());
System.out.println(lisdis);
}
}
运行结果:
[5, 4, 3, 9, 10, 6, 15]
(3)自定类List去重
- 重写自定义类的hashCode和equlas方法
- 使用Strream中的distinct()方法
参考文章:
JAVA常见容器__走歌_的博客-CSDN博客_java容器有哪几种
Java集合中List,Set以及Map等集合体系详解(史上最全)_游走的大千世界的烤腰子的博客-CSDN博客_java集合
















 28万+
28万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









