







泰坦尼克号幸存者预测是kaggle上一个较为经典的数据分析案例,之前做了这个案例,今天向大家分享一下自己的学习笔记。
数据集来源:
https://www.kaggle.com/c/titanicwww.kaggle.com为了让部分没看过《泰坦尼克号》这部电影的小伙伴也能对数据背景有一个基本认识,我们简单概括一下背景:
泰坦尼克号的沉没是世界上最严重的海难事故之一,造成了大量的人员伤亡。这是一艘号称当时世界上最大的邮轮,船上的人年龄各异,背景不同,有贵族豪门,也有平民旅人,邮轮撞击冰山后,船上的人马上采取措施安排救生艇转移人员,从本次海难中存活下来的,也就是幸存者。
在上一篇中,我们通过数据挖掘,得出了一些与获救率有关的结论,感兴趣的同学可以回顾一下:
侦探L:数据挖掘经典实例——泰坦尼克号幸存者预测zhuanlan.zhihu.com今天我们采用另一种方法——决策树来进行幸存者预测。
下面,正文开始~
一、数据导入及基本了解
import numpy as np
import pandas as pd
df = pd.read_csv(r'C:UsersAdministratorDesktopdata.csv',encoding='utf-8')1、查看前10行数据
df.head(10)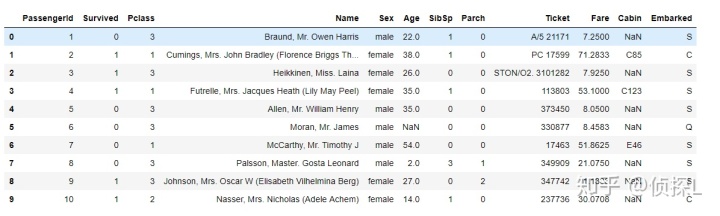
2、查看数据大小
df.shape
可以看到,我们的数据集有891个样本,12个特征。
3、查看特征
df.info()
其中,
Survived:代表是否幸存,0否,1是
Pclass:船舱等级,1最好,2次之,3最后
SibSp:该名乘客上船后,与其一起同行上船的兄弟姐妹的个数
Parch:该名乘客上船后,与其一起同行上船的家里的老人与孩子的个数
Ticket:船票编号
Fare:船票价格
Cabin:该名乘客在船舱内的编号
Embarked:该名乘客登船的码头,有三个:S、C、Q三个码头。
4、查看数据缺失情况
df.isnull().sum() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2352
2352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









