







一、特征处理是什么
通过特定的统计学方法或数学方法,将数据转化成算法要求的数据
转成数值型的数据
标准缩放:1.归一化;2.标准化;3.缺失值
类别型数据:one-hot编码
时间类型:时间的切分
所有预处理的方法都在这个模块里面
sklearn.preprocessing
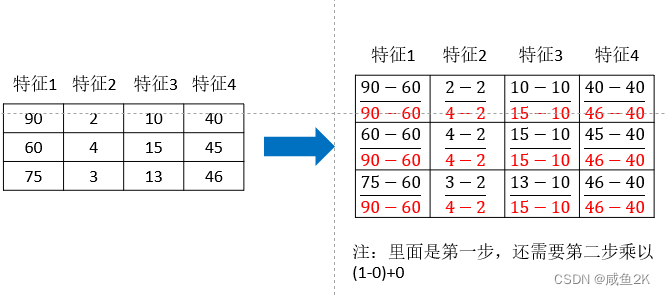
1.归一化
所有数据都会映射到[0,1]之间

mx,mi默认为1和0,是因为需要其在[0,1]这个区间
例子:
sklearn归一化API: sklearn.preprocessing.MinMaxScaler
归一化的步骤:
1、实例化MinMaxScalar
2、通过fit_transform转换
def mm():
"""
归一化处理
:return: NOne
"""
#mm = MinMaxScaler()默认是(0,1)
mm = MinMaxScaler(feature_range=(2, 3))
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
if __name__=='__main__':
mm()结果:
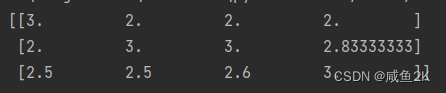
归一化的原因:使得某一特征不会对结果产生更大的影响
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1080
1080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









