







1.维度
维度就是功能shape返回的结果,shape中返回了几个数字,就是几维索引以外的数
据,不分行列的叫一维(此时shape返回唯一的维度上的数据个数),有行列之分叫二维(shape返回行x列),也称为表。一张表最多二维,复数的表构成了更高的维度。当一个数组中存在2张3行4列的表时,shape返回的是(更高维,行,列)。当数组中存在2组2张3行4列的表时,数据就是4维,shape返回(2,2,3,4)。

Q:特征矩阵——特指一个表,二维表
数组中的每一张表,都可以是一个特征矩阵或一个DataFrame,这些结构永远只有一张表,所以一定有行列,其中行是样本,列是特征
Q:降维的目的
降维算法中的”降维“,指的是降低特征矩阵中特征的数量。
降维的目的是为了让算法运算更快,效果更好
另一种需求:数据可视化。
1.2 sklearn中的降维算法
sklearn中降维算法都被包括在模块decomposition中,这个模块本质是一个矩阵分解模块
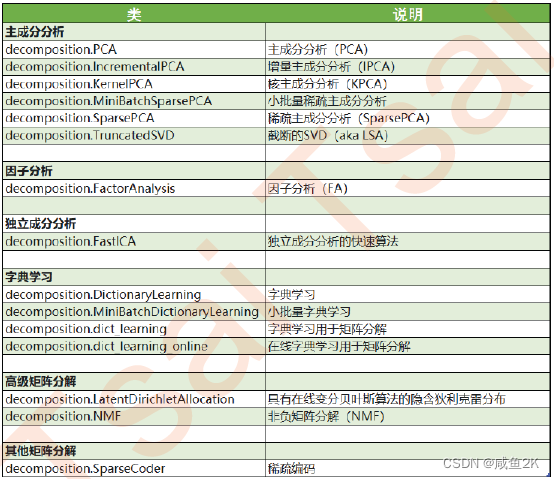
SVD和主成分分析PCA都属于矩阵分解算法中的入门算法,都是通过分解特征矩阵来进行降
躲不过数学
2 PCA与SVD
希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。

Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,xhat代表这一列样本的均值。
Q:方差计算公式中为什么除数是n-1?
这是为了得到样本方差的无偏估计
2.1 降维究竟是怎样实现?
总方差一样,就可以实现降维。降维中,特征值的关键信息不是会损失太多。
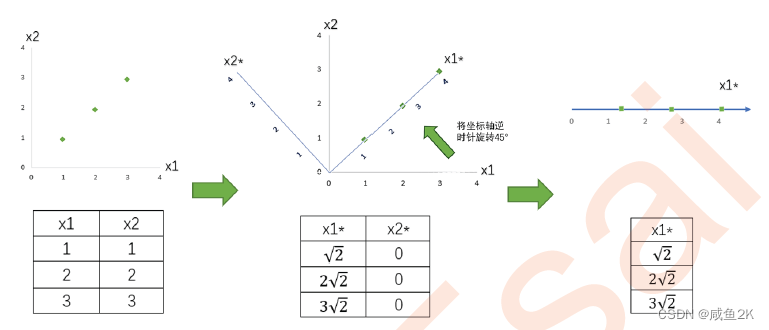

在步骤3当中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。
PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。

而SVD使用奇异值分解来找出空间V,其中Σ也是一个对角矩阵,不过它对角线上的元素是奇异值,这也是SVD中用来衡量特征上的信息量的指标。U和V^{T}分别是左奇异矩阵和右奇异矩阵,也都是辅助矩阵
![]()
在数学原理中,无论是PCA和SVD都需要遍历所有的特征和样本来计算信息量指标。并且在矩阵分解的过程之中,会产生比原来的特征矩阵更大的矩阵,比如原数据的结构是(m,n),在矩阵分解中为了找出最佳新特征空间V,可能需要产生(n,n),(m,m)大小的矩阵,还需要产生协方差矩阵去计算更多的信息。
无论是Python还是R,或者其他的任何语言,在大型矩阵运算上都不是特别擅长
因此,降维算法的计算量很大,运行比较缓慢,但无论如何,它们的功能无可替代
Q::PCA和特征选择技术都是特征工程的一部分,它们有什么不同

PCA是特征创造,已经不知道新的特征在现实世界中的含义了。
PCA用法也不适合于探索特征和标签之间的关系的模型。
2.2 重要参数n_components
#1. 调用库和模块
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
#2. 提取数据集
iris = load_iris()
y = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5139
5139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









