





引言
前段时间,我负责的远程控制手机的功能新加了动态修改手机端网络延迟的功能(网络测试),所以当时 Infra 团队为我们构建了一个 WiFi 网络环境,并通过两台 Linux 主机进行实际的网络控制。不过后来我们对其软件解决方案进行了改善,使其不仅能够修改网络的延迟,还能够修改网络的带宽和丢包情况,本文就介绍了这整个实现方案。
网络结构
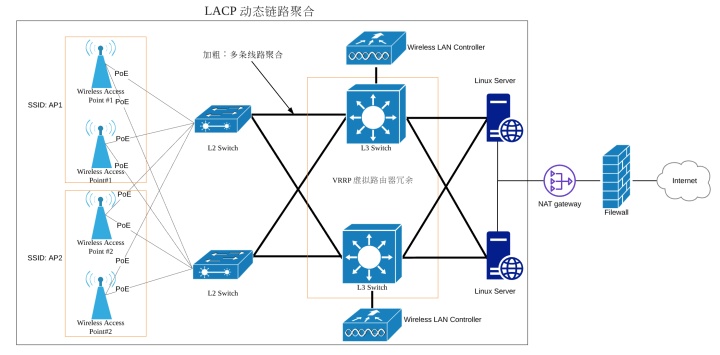
上图是整个 WiFi 网络环境的结构的简化图。
1. 同一 WiFi 由多个 AP 负责,它们使用同一个 SSID,密码,但是工作在不同的信道上。当任一 AP 故障时,连在 L3 交换机上的无线网络控制器,将负责故障的无缝转移。
2. 整个网络链路中,从 AP 开始到 Linux Server 上,均采用了链路聚合技术,而且呈网状连接,来达到容灾和负载均衡的功效。
3. 其中 L3 交换机部分,采用了 VRRP 协议组建成一个虚拟路由器冗余。
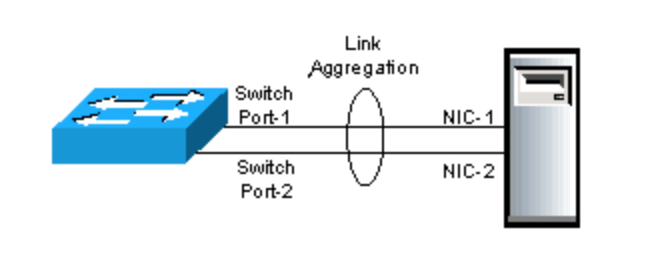
链路聚合(英语:Link Aggregation)是一个计算机网络术语,指将多个物理端口汇聚在一起,形成一个逻辑端口,以实现出/入流量吞吐量在各成员端口的负荷分担,交换机根据用户配置的端口负荷分担策略决定网络封包从哪个成员端口发送到对端的交换机。当交换机检测到其中一个成员端口的链路发生故障时,就停止在此端口上发送封包,并根据负荷分担策略在剩下的链路中重新计算报文的发送端口,故障端口恢复后再次担任收发端口。链路聚合在增加链路带宽、实现链路传输弹性和工程冗余等方面是一项很重要的技术。
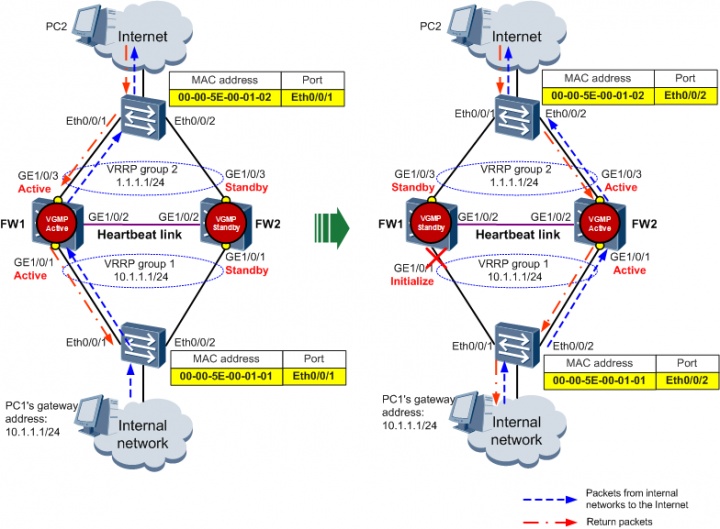
VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)将可以承担网关功能的一组路由器加入到备份组中,形成一台虚拟路由器,这样主机的网关设置成虚拟网关,就能够实现冗余。 VRRP 将局域网内的一组路由器划分在一起,称为一个备份组。备份组由一个 Master 路由器和多个 Backup 路由器组成,功能上相当于一台虚拟路由器。 VRRP 备份组具有以下特点:
- 虚拟路由器具有 IP 地址,称为虚拟 IP 地址。局域网内的主机仅需要知道这个虚拟路由器的 IP 地址,并将其设置为缺省路由的下一跳地址。
- 网络内的主机通过这个虚拟路由器与外部网络进行通信。
- 备份组内的路由器根据优先级,选举出 Master 路由器,承担网关功能。其他路由器作为 Backup 路由器,当 Master 路由器发生故障时,取代 Master 继续履行网关职责,从而保证网络内的主机不间断地与外部网络进行通信。
关于偏硬件这部分的内容,可能我的理解也不一定正确,如果哪位同学发现我理解的有问题,还望留言告诉我。
Linux 网络接口配置
因为和 Linux Server 直接相连的的是一个基于 VRRP 的虚拟冗余路由,而且 Linux Server 上也使用了动态链路聚合技术,所以每台 Linux Server 上都有 4 个网络接口,每一个 L3 交换机会使用到其中的两个接口,这两个接口会聚合在一起。
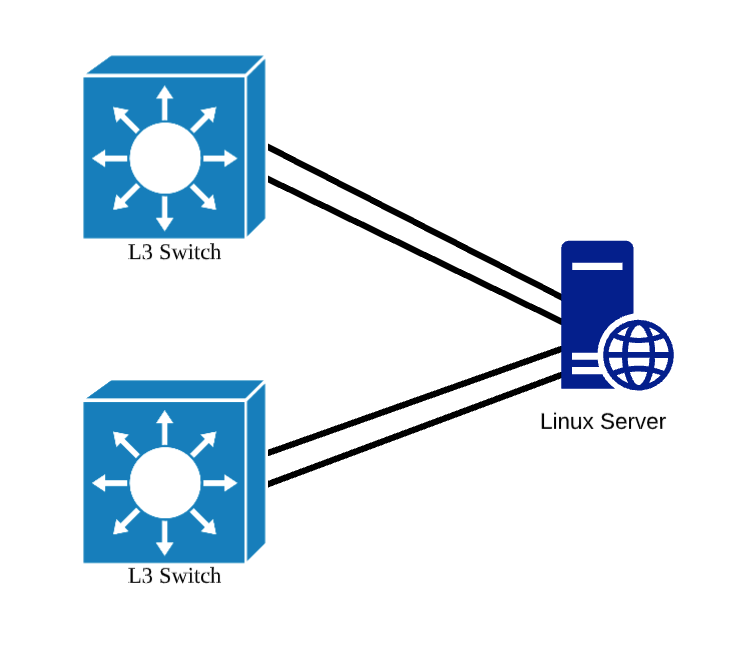
在每台 Linux Server 上有四个物理网卡,它们两两组合。通过 Linux 提供的网卡 bonding 功能聚合在一起。不过在下面的介绍中,因为我没有可供实验的实体机,所以我将采用 2 对 veth peer 虚拟网卡的方式模拟 Linux Server 和一台 L3 交换机的连接过程。
我这里创建了 2 对 veth peer 网卡,假设 veth1 veth3 是在 L3 交换机上的两个网卡,这样就能模拟出 Linux Server 与 L3 交换机之间通过两条网线连通,Linux Server 和 L3 交换机上各有 2 个网络接口的效果。
# 创建两对 veth peer
ip link add veth0 type veth peer name veth1
ip link add veth2 type veth peer name veth3
# 启动四个 veth 接口
ip link set veth0 up
ip link set veth2 up
ip link set veth1 up
ip link set veth3 up
# 确认 Linux Server 上的网络接口
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3f:ad:cd:f8 brd ff:ff:ff:ff:ff:ff
inet 10.231.227.166/18 brd 10.231.255.255 scope global dynamic eth0
valid_lft 3492sec preferred_lft 3492sec
3: veth3@veth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:30:f1:52:80:e2 brd ff:ff:ff:ff:ff:ff
4: veth2@veth3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether b2:96:e5:2d:46:db brd ff:ff:ff:ff:ff:ff
5: veth1@veth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
6: veth0@veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff接下来,我们创建两个 bond 将 Linux Server 上这两对 veth 网卡聚合在一起,这需要修改 /etc/sysconfig/network-scripts/ 下的网卡配置。
# 注意 DEVICE 需要和 ifcfg- 后面的文本内容一致,HWADDR 要和设备 MAC 地址一致
vi /etc/sysconfig/network-scripts/ifcfg-bond0
DEVICE=bond0
ONBOOT=yes
BOOTPROTO=static
USERCTL=no
BONDING_OPTS="miimon=100 mode=4 xmit_hash_policy=2"
vi /etc/sysconfig/network-scripts/ifcfg-bond1
DEVICE=bond1
ONBOOT=yes
BOOTPROTO=static
USERCTL=no
BONDING_OPTS="miimon=100 mode=4 xmit_hash_policy=2"
vi /etc/sysconfig/network-scripts/ifcfg-veth0
DEVICE=veth0
ONBOOT=yes
USERCTL=no
MASTER=bond0
SLAVE=yes
BOOTPROTO=no
HWADDR=a6:04:98:44:cd:5f
vi /etc/sysconfig/network-scripts/ifcfg-veth1
DEVICE=veth1
ONBOOT=yes
USERCTL=no
MASTER=bond1
SLAVE=yes
BOOTPROTO=no
HWADDR=62:b0:ec:1e:03:b6
vi /etc/sysconfig/network-scripts/ifcfg-veth2
DEVICE=veth2
ONBOOT=yes
USERCTL=no
MASTER=bond0
SLAVE=yes
BOOTPROTO=no
HWADDR=b2:96:e5:2d:46:db
vi /etc/sysconfig/network-scripts/ifcfg-veth3
DEVICE=veth3
ONBOOT=yes
USERCTL=no
MASTER=bond1
SLAVE=yes
BOOTPROTO=no
HWADDR=62:30:f1:52:80:e2在上述的配置中,我们先是创建了 bond0 和 bond1 网络接口,我们通过它们来 bonding 另外两对虚拟网卡,BONDING_OPTS="miimon=100 mode=4 xmit_hash_policy=2 说明这个 bond 接口我们使用了模式 4,也就是前面所说的 IEEE 802.3ad 动态链路聚合,连通性检查的间隔为 100 ms, xmit_hash_policy=2 表示哈希策略是 layer2 + layer3,根据 MAC 和 IP 地址进行。而另外两对虚拟网卡的配置中,需要设定其从属于其中一个 bond。
配置完成后,我们重启网络模块,启用 bond0 接口并查看,就能看到刚才创建出的 bond0 接口,它的 MAC 地址会变成 veth0 的 MAC,此外 veth2 也会将自己的 MAC 地址虚拟为 veth0 的 MAC,bond1 网卡的情况也类似。
# 重启网络
service NetworkManager restart
Redirecting to /bin/systemctl restart NetworkManager.service
service network restart
ip link set bond0 up
ip link set bond1 up
# 确认当前 Linux Server 网络状况
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3f:ad:cd:f8 brd ff:ff:ff:ff:ff:ff
inet x.x.x.x/18 brd 10.231.255.255 scope global dynamic eth0
valid_lft 3063sec preferred_lft 3063sec
3: veth3@veth2: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond1 state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
4: veth2@veth3: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond0 state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
5: veth1@veth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond1 state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
6: veth0@veth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond0 state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
7: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
8: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff此外,我们还可以通过 /proc/net/bonding/bond0 查看当前 bond0 接口的状态,其中我们会看到该接口的 bonding 模式是动态链路聚合,hash 策略是 layer 2+3,还能看到其下的两块虚拟网卡 veth0 和 veth2 的原始 MAC 和使用的 MAC,以及该聚合链路对端的 MAC 地址,也就是 bond1 的 MAC 地址。同理,bond1 的信息也可以通过类似的方式查看。
cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer2+3 (2)
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
802.3ad info
LACP rate: slow
Min links: 0
Aggregator selection policy (ad_select): stable
System priority: 65535
System MAC address: a6:04:98:44:cd:5f
Active Aggregator Info:
Aggregator ID: 1
Number of ports: 2
Actor Key: 15
Partner Key: 15
Partner Mac Address: 62:b0:ec:1e:03:b6
Slave Interface: veth0
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: a6:04:98:44:cd:5f
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: monitoring
Partner Churn State: monitoring
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: a6:04:98:44:cd:5f
port key: 15
port priority: 255
port number: 1
port state: 61
details partner lacp pdu:
system priority: 65535
system mac address: 62:b0:ec:1e:03:b6
oper key: 15
port priority: 255
port number: 1
port state: 61
Slave Interface: veth2
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: b2:96:e5:2d:46:db
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: monitoring
Partner Churn State: monitoring
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: a6:04:98:44:cd:5f
port key: 15
port priority: 255
port number: 2
port state: 61
details partner lacp pdu:
system priority: 65535
system mac address: 62:b0:ec:1e:03:b6
oper key: 15
port priority: 255
port number: 2
port state: 61
cat /proc/net/bonding/bond1
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer2+3 (2)
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
802.3ad info
LACP rate: slow
Min links: 0
Aggregator selection policy (ad_select): stable
System priority: 65535
System MAC address: 62:b0:ec:1e:03:b6
Active Aggregator Info:
Aggregator ID: 1
Number of ports: 2
Actor Key: 15
Partner Key: 15
Partner Mac Address: a6:04:98:44:cd:5f
Slave Interface: veth1
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 62:b0:ec:1e:03:b6
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 62:b0:ec:1e:03:b6
port key: 15
port priority: 255
port number: 1
port state: 61
details partner lacp pdu:
system priority: 65535
system mac address: a6:04:98:44:cd:5f
oper key: 15
port priority: 255
port number: 1
port state: 61
Slave Interface: veth3
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 62:30:f1:52:80:e2
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 62:b0:ec:1e:03:b6
port key: 15
port priority: 255
port number: 2
port state: 61
details partner lacp pdu:
system priority: 65535
system mac address: a6:04:98:44:cd:5f
oper key: 15
port priority: 255
port number: 2
port state: 61然后,我们需要为 bond0 创建两个 vlan,一条 vlan 用作控制流向 bond0 的流量,一条 vlan 用作控制流出 bond 0 的流量。我们同样需要修改 /etc/sysconfig/network-scripts/ 下的配置。
# 创建 vlan
vi /etc/sysconfig/network-scripts/ifcfg-bond0.90
DEVICE="bond0.90"
BOOTPROTO=none
ONPARENT=yes
IPADDR=192.168.10.1
NETMASK=255.255.255.0
VLAN=yes
NM_CONTROLLED=no
vi /etc/sysconfig/network-scripts/ifcfg-bond0.91
DEVICE="bond0.91"
BOOTPROTO=none
ONPARENT=yes
IPADDR=192.168.11.1
NETMASK=255.255.255.0
VLAN=yes
NM_CONTROLLED=no
# 启动 vlan
ifup /etc/sysconfig/network-scripts/ifcfg-bond0.90
ifup /etc/sysconfig/network-scripts/ifcfg-bond0.91
# 查看当前网络
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3f:ad:cd:f8 brd ff:ff:ff:ff:ff:ff
inet x.x.x.x/18 brd 10.231.255.255 scope global dynamic eth0
valid_lft 2482sec preferred_lft 2482sec
3: veth3@veth2: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond1 state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
4: veth2@veth3: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond0 state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
5: veth1@veth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond1 state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
6: veth0@veth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond0 state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
7: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
8: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
9: bond0.90@bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
inet 192.168.10.1/24 brd 192.168.10.255 scope global bond0.90
valid_lft forever preferred_lft forever
10: bond0.91@bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
inet 192.168.11.1/24 brd 192.168.11.255 scope global bond0.91
valid_lft forever preferred_lft forever这时候 bond0.90 和 bond0.91 已经有 IP 了,不过 bond 1 还没有 IP 地址,这里我们假设 bond 0 代表了 Linux Server,bond1 代表了 L3 交换机,接下来的任务就是如何为 L3 交换机分配 IP 地址,bond 1 的 IP 分配和 bond 0类似,我们也为其分配两个 vlan,90 和 91,vlan 90 代表的是从 bond0(Linux Server) 发往 bond1(L3-Switch) 的数据,vlan 91 代表从 bond1(L3-Switch) 发往 bond0(Linux Server)的数据。总结来说 bond0.90 和 bond1.90 在一个 vlan 中,只是 IP 不同,同理 bond0.91 和 bond1.91 在一个 vlan 中,只是 IP 不同。
# 创建 vlan
vi /etc/sysconfig/network-scripts/ifcfg-bond1.90
DEVICE="bond1.90"
BOOTPROTO=none
ONPARENT=yes
IPADDR=192.168.10.2
NETMASK=255.255.255.0
VLAN=yes
NM_CONTROLLED=no
vi /etc/sysconfig/network-scripts/ifcfg-bond1.91
DEVICE="bond1.91"
BOOTPROTO=none
ONPARENT=yes
IPADDR=192.168.11.2
NETMASK=255.255.255.0
VLAN=yes
NM_CONTROLLED=no
# 启动 vlan
ifup /etc/sysconfig/network-scripts/ifcfg-bond1.90
ifup /etc/sysconfig/network-scripts/ifcfg-bond1.91
# 查看网络设备
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:16:3f:ad:cd:f8 brd ff:ff:ff:ff:ff:ff
inet x.x.x.x/18 brd 10.231.255.255 scope global dynamic eth0
valid_lft 2127sec preferred_lft 2127sec
3: veth3@veth2: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond1 state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
4: veth2@veth3: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond0 state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
5: veth1@veth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond1 state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
6: veth0@veth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc noqueue master bond0 state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
7: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
8: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
9: bond0.90@bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
inet 192.168.10.1/24 brd 192.168.10.255 scope global bond0.90
valid_lft forever preferred_lft forever
10: bond0.91@bond0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:04:98:44:cd:5f brd ff:ff:ff:ff:ff:ff
inet 192.168.11.1/24 brd 192.168.11.255 scope global bond0.91
valid_lft forever preferred_lft forever
13: bond1.90@bond1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.2/24 brd 192.168.10.255 scope global bond1.90
valid_lft forever preferred_lft forever
14: bond1.91@bond1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 62:b0:ec:1e:03:b6 brd ff:ff:ff:ff:ff:ff
inet 192.168.11.2/24 brd 192.168.11.255 scope global bond1.91
valid_lft forever preferred_lft forever上述的这套方案就是各个设备之间(Linux、L3 Switch、AP 控制器)连接的建立方式,因为我这里没有可用的物理设备做实验,所以只能以模拟的方式进行,不过即便是模拟的方式也和实际在物理机上进行的方案如出一辙,至少从网络接口的属性上来看和物理机上的状态是类似的。因为 veth 不能跨越多台 Linux 设备,也不能将 bond 设备放入命名空间中(我还尝试过在容器中创建 bond 设备,也不允许),所以接下来的部分我就不能以模拟的方式进行了。相反的,我会更多的以图文的形式介绍整个网络的组件过程。
这里总结一下从 Linux Server 到 L3 Switch 的连接方式,之前说过它们之间的连接建立在双方的 2 条物理连接上(上例中通过 2 对 veth peer 模拟),这两条物理连接构成一个基于 LACP 协议的聚合链路。在物理链路上,我们创建了两个虚拟网络 vlan90 和 vlan91,分别对应了不同的数据流向。这时候,我们只需要配置一下路由表,就能保证 Linux 和 L3 Switch 之间的连通性,如下图所示。不仅 Linux 和 L3 Switch 之间采用了虚拟网络 vlan 的方式进行路由,L3 Switch 和 AP 控制器之间也是通过这种方式连接,我们后面会介绍到它。
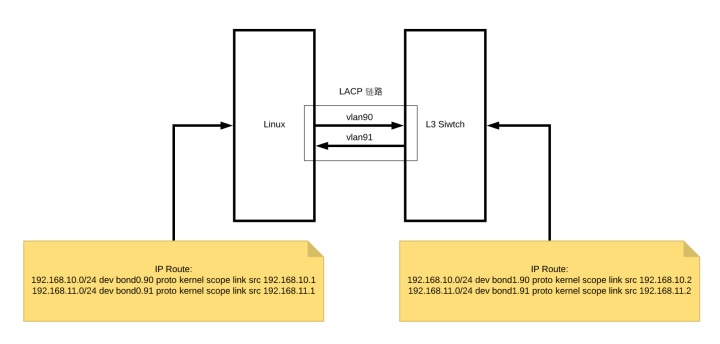
这里之所以特意分出两个 vlan 代表不同的传输方向,是想要通过 vlan 网络接口控制网络的带宽,延迟等。因为,tc 只能控制从一个网卡发出的数据带宽和延迟,而不能控制从一个网卡接收到的数据带宽和延迟。所以,你会发现实际物理连接的对应接口 bond0 并没有绑定 IP 地址,IP 地址实际上绑定在了 bond0 下的 vlan 网络接口上,这时候当内核从 bond 0 收到一个数据包时,发现该包实际上对应的网络设备应该是 bond0.91,这时候内核就会将该包转发到 bond0.91 这个网络接口上,这就涉及到了向一个网卡发送数据的过程,也就是说只要将 tc(传输控制)规则加载 bond0.91 这个网卡上,就能达到控制流入数据包的效果。
IP 分配方案
理解了 vlan 的构建方式和 LACP 链路的构建方式之后,我们从更高的视角来看一下整个网络中是如何分配 IP 和路由的。这里我们假设 L3 交换机和 AP 控制器之间也是通过 LACP(L3 交换机使用 bond2 <-> bond3 连通 AP 控制器,L3 交换机使用 bond4 连通交换机,AP 1 使用 bond5,AP 2 使用 bond 6 连通交换机) 和 vlan 进行通讯,这不过这里的每个 vlan 已经不再代表一个方向了,而是一个 vlan 代表一个 AP 的双向数据,这也是很自然的,因为 tc 并不会作用于 AP 控制器和 L3 交换机之间,所以没必要再将每个方向的流量拆分成不同的虚拟网络。这时候路由表中需要新添加几项内容,才能保证 L3 交换机和 AP,AP 控制器之间的连通。
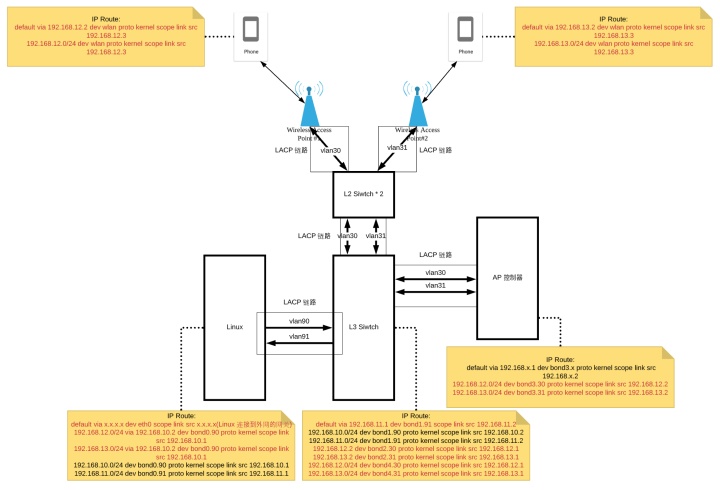
在上图中,L3 交换机与 AP 控制器之间是通过两条物理网线直接连接的,建立在这两条物理网线之上的 LACP 链路(bond2<->bond3)上衍生出了 vlan 30 和 vlan31。而从 L3 交换机到 AP 之间是通过两个 L2 交换机连接的,L2 交换机到 L3 交换机之间的连接构成了一个 LACP 聚合链路(bond4)。各个 AP 又分别通过两个 L2 交换机构成了多条 LACP 链路(bond5 和 bond6)。
最后,手机上的默认网关是 AP 控制器,数据从手机通过 L2 交换机 -> L3 交换机-> AP 控制器,AP 控制器的默认网关是 L3 交换机,数据再流回 L3 交换机,L3 交换机的默认网关是 Linux Server,数据通过 vlan 91 流向 Linux,Linux 再将数据包发给自己的 NAT 网关,通过它发送到互联网中。
而从互联网中流回手机的数据包通过 NAT 网关流入 Linux Server,Linux Server 再通过 vlan90 将数据包传送给 L3 交换机,L3 交换机再将数据发给对应的手机。
IP 划分的方案就已经介绍完了,接下来我们再说一下 IP 地址分配的方式,这里我们在 Linux Server 上使用到了 dnsmasq。dnsmasq 提供 DNS 缓存和 DHCP 服务功能。作为域名解析服务器(DNS),dnsmasq 可以通过缓存 DNS 请求来提高对访问过的网址的连接速度。作为 DHCP 服务器,dnsmasq 可以用于为局域网电脑分配内网 IP 地址和提供路由。DNS 和 DHCP 两个功能可以同时或分别单独实现。dnsmasq 轻量且易配置,适用于个人用户或少于 50 台主机的网络。
DHCP(动态主机配置协议)是一个局域网的网络协议。指的是由服务器控制一段 IP 地址范围,客户机登录服务器时就可以自动获得服务器分配的 IP 地址和子网掩码。它通常被应用在大型的局域网络环境中,主要作用是集中的管理、分配 IP 地址,使网络环境中的主机动态的获得 IP 地址、Gateway 地址、DNS 服务器地址等信息,并能够提升地址的使用率。DHCP 协议采用客户端/服务器模型,主机地址的动态分配任务由网络主机驱动。 当一个主机新加入局域网中时会以广播的形式发出 DHCP Discover 报文,一旦 DHCP Server 接收到 Discover 报文,就会向 DHCP Client 发送一个 Offer 报文,该报文中包含为 Client 分配的 IP 地址,这时候 Client 会选择一个 IP (一般按照 Offer 报文的先后顺序)并广播发送一个 Request 报文,其中包含选中的 DHCP Server IP 和自己准备使用的 IP 地址。如果 DHCP Server 收到该 Request 报文后,如果发现该 IP 就是自己刚才为该 Client 分配的 IP,就会回复一个 ACK 报文。之后 Client 会不断地续期该 IP。当 Client 不再需要该 IP 地址时,会向 DHCP Server 发送释放请求。
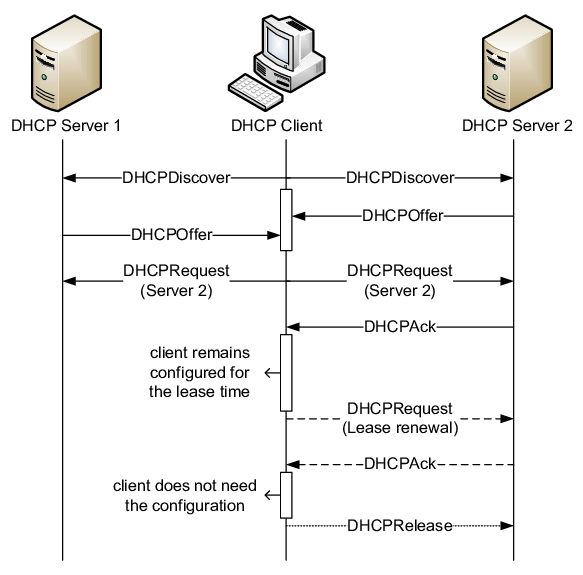
理解了 dnsmasq 和 DHCP 的概念后,我们看看如何安装并使用它。
# 安装 dnsmasq
sudo yum install dnsmasq
# 修改配置
vi /etc/dnsmasq.conf
# 注意这里需要监听的接口是 bond0.90 因为从这里发出的包才能发送到手机上
interface=bond0.90
# 接下来是 ap1 和 ap2 的子网配置
conf-file=/path/to/dhcp/option/option-ap1.conf
dhcp-hostsfile=/path/to/dhcp/subnet/subnet-ap1.conf
conf-file=/path/to/dhcp/option/option-ap2.conf
dhcp-hostsfile=/path/to/dhcp/subnet/subnet-ap2.conf
# 我们以 ap1 为例介绍子网配置和 dhcp 配置
vi /path/to/dhcp/option/option-ap1.conf
dhcp-range=tag:ap1,192.168.12.3,192.168.12.199,12h # IP 分配范围
dhcp-option=tag:ap1,option:router,192.168.12.2 # AP 控制器在 vlan30 网段的 ip
dhcp-option=tag:ap1,option:dns-server,192.168.10.3 # 自己搭设的一个 DNS 服务器
# 为了方便管理,这里我们为每个设备指定了其独享的 IP 地址
vi /path/to/dhcp/subnet/subnet-ap1.conf
11:11:11:11:11:11,set:ap1,192.168.12.3,PHONE-001
12:12:12:12:12:12,set:ap1,192.168.12.4,PHONE-002
# ap2 的配置就十分类似了
vi /path/to/dhcp/option/option-ap2.conf
dhcp-range=tag:ap2,192.168.13.3,192.168.13.199,12h # IP 分配范围
dhcp-option=tag:ap2,option:router,192.168.13.2 # AP 控制器在 vlan31 网段的 ip
dhcp-option=tag:ap2,option:dns-server,192.168.10.3 # 自己搭设的一个 DNS 服务器
# 为了方便管理,这里我们为每个设备指定了其独享的 IP 地址
vi /path/to/dhcp/subnet/subnet-ap2.conf
21:21:21:21:21:21,set:ap2,192.168.13.3,PHONE-001
22:22:22:22:22:22,set:ap2,192.168.13.4,PHONE-002
# 配置好 dnsmasq 之后重启该服务
sudo systemctl restart dnsmasq
# 查看 Linux log 就能看到 dnsmasq 的 DHCP 响应情况
tail -f /var/log/messagesLinux iptables 配置
在我们的场景中需要通过 iptables 对数据包进行进行分类的工作,因为我们需要同时控制从手机到互联网的网络状况以及从互联网流向手机的网络情况,这就需要我们不仅要将不同手机的数据包识别出来,还要将同一手机的不同方向数据包识别出来,然后为各类数据包设定不同的网络限制。
在介绍我们对 iptables 的使用之前,我们先简单地介绍一下 iptables 是什么。iptables 是一个配置 Linux 内核防火墙的命令行工具,它基于内核的 netfilter 机制。
看过我之前的 Linux 系列文章的同学可能还对 netfilter 记忆犹新,netfilter 是 Linux 内核的包过滤框架,它提供了一系列的钩子(Hook)供其他模块控制包的流动。这些钩子包括
- NF_IP_PRE_ROUTING:刚刚通过数据链路层解包进入网络层的数据包通过此钩子,它在路由之前处理
- NF_IP_LOCAL_IN:经过路由查找后,送往本机(目的地址在本地)的包会通过此钩子
- NF_IP_FORWARD:不是本地产生的并且目的地不是本地的包(即转发的包)会通过此钩子
- NF_IP_LOCAL_OUT:所有本地生成的发往其他机器的包会通过该钩子
- NF_IP_POST_ROUTING:在包就要离开本机之前会通过该钩子,它在路由之后处理
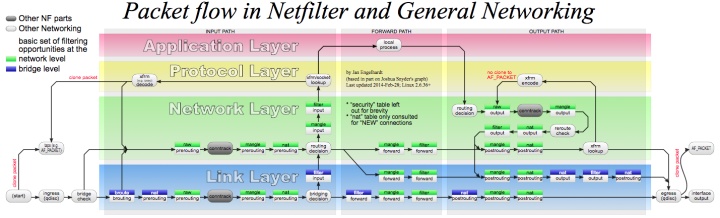
iptables 通过表和链来组织数据包的过滤规则,每条规则都包括匹配和动作两部分。默认情况下,每张表包括一些默认链,用户也可以添加自定义的链,这些链都是顺序排列的。这些表和链包括:
- raw 表用于决定数据包是否被状态跟踪机制处理,内建 PREROUTING 和 OUTPUT 两个链
- filter 表用于过滤,内建 INPUT(目的地是本地的包)、FORWARD(不是本地产生的并且目的地不是本地)和 OUTPUT(本地生成的包)等三个链
- nat 表用于网络地址转换,内建 PREROUTING(在包刚刚到达防火墙时改变它的目的地址)、INPUT、OUTPUT 和 POSTROUTING(要离开防火墙之前改变其源地址)等链
- mangle 表用于对报文进行修改,内建 PREROUTING、INPUT、FORWARD、OUTPUT 和 POSTROUTING 等链
- security 表用于根据安全策略处理数据包,内建 INPUT、FORWARD 和 OUTPUT 链
在 iptables 中的默认链 PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING 实际上就对应了 netfilter 中的各个钩子,也就是说如果我们在 iptables 中配置了一些网络包的处理策略,那么这些策略的真正执行,就会在 netfilter 框架在执行对应的钩子函数时进行。
理解了 iptables 是什么之后,我们怎么用它才能达到我们的目的呢?我们需要使用 iptables 的 mangle 表,因为它可以对报文进行一些修改,我们要通过 IP 地址筛选出不同的手机,进一步地根据源 IP 地址和目标 IP 地址筛选出不同方向的数据包,然后将它们分到不同的类型中。这里所说的类型大家可能不是特别理解,简单地讲,我们可以将一批类似的数据包(比如:从手机 A 发出的包)分到一类中(类通过数字进行标示),随后我们就可以在传输控制模块 tc 中对各个类型的数据包(根据类型编号)加上传输控制策略(比如带宽限制,延迟限制等)。
理解了理论基础之后,终于到实际的操作环节了,不过你很可能会有些失望,实际的操作两行命令就够了。
# 添加 iptables 策略,该策略在 FORWORD 钩子中执行,策略的内容是:从手机(192.168.13.3)发出的包,将其分配到 1:2 类型中
iptables -t mangle -A FORWARD -s 192.168.13.3 -j CLASSIFY --set-class 1:2
# 添加 iptables 策略,该策略在 FORWORD 钩子中执行,策略的内容是:发往手机(192.168.13.3)的包,将其分配到 1:3 类型中
iptables -t mangle -A FORWARD -d 192.168.13.3 -j CLASSIFY --set-class 1:3
# 查看现有规则
iptables -t mangle -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
CLASSIFY all -- 192.168.13.3 anywhere CLASSIFY set 1:2
CLASSIFY all -- anywhere 192.168.13.3 CLASSIFY set 1:3
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
# 当我们不需要再为手机加网络传输控制时,可以通过如下指令删除刚才创建的分类策略
iptables -t mangle -D FORWARD -s 192.168.13.3 -j CLASSIFY --set-class 1:2
iptables -t mangle -D FORWARD -d 192.168.13.3 -j CLASSIFY --set-class 1:3iptables 的操作命令很简单 -t mangle 表明我们要操作 mangle 表,-A 表示要添加规则,-D 表示要删除规则,随后的 FORWARD 表明我们要操作的是 FORWARD 链。-s 192.168.13.3 表示匹配源地址是 192.168.13.3 的包,-d 192.168.13.3 表示匹配目标地址是 192.168.13.3 的包。-j CLASSIFY 表示对于刚才匹配到的包要执行的目标操作是分类操作。--set-class 1:2 表示将匹配到的包分配到 1:2 类别中。
这里大家可能会好奇为啥分的类由两部分组成(冒号分割),前面部分都是 1,后半部分各不一样。这部分内容,我们随后介绍 tc 的时候在说,这里我们只要保证各种数据包分配的类型是唯一的就行了,这就需要我们在自己的管理程序中维护当前类型分配的情况(我们是在 Java 中维护的,然后Java 再通过命令行操纵 iptables),在要分配新的类型时选择一个当前未被占用的类型即可。此外值得一提的是,因为手机上的数据包会通过网关进行转发才能到 Linux Server,所以我们只能通过 IP 地址来过滤出特定的手机,而不能使用报文的 MAC 地址过滤,这也就是为什么我们前面采用的是静态 DHCP 分配方案(每个 MAC 地址只会分配一个绑定的 IP 地址),而不是动态分配 IP。
Linux tc 配置
为每个手机的每个方向分配不同的类型之后,我们终于可以加网络限制策略了,这里我们使用到的 tc 命令行工具。它是 Linux 操作系统中的流量控制器 TC(Traffic Control),它利用队列规定建立处理数据包的队列,并定义队列中的数据包被发送的方式,从而实现对流量的控制。
tc 流量的处理由三种对象控制,它们是:qdisc(queueing discipline,排队规则)、class(类别) 和 filter(过滤器)。
- qdisc 通过队列将数据包缓存起来,用来控制网络收发的速度
- class 用来表示控制策略
- filter 用来将数据包划分到具体的控制策略中
QDisc(排队规则)是 queueing discipline 的简写,它是理解流量控制(traffic control)的基础。无论何时,内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的 qdisc(排队规则)把数据包加入队列。然后,内核会尽可能多地从 qdisc 里面取出数据包,把它们交给网络适配器驱动模块。最简单的 QDisc 是 pfifo 它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。不过,它会保存网络接口一时无法处理的数据包。
QDisc 有分为可分类的和不可分类的,不可分类的可以认为是整个队列的处理规则加在整个网络接口上,所有从该接口出去的数据包都在这个 QDisc 管理。而可分类的 QDisc 可以向下细分出更多的子队列。
无类别 QDISC 包括:
- p/b fifo
使用最简单的 qdisc,纯粹的先进先出。只有一个参数:limit,用来设置队列的长度, pfifo 是以数据包的个数为单位;bfifo是以字节数为单位。
- pfifo_fast
在编译内核时,如果打开了高级路由器(Advanced Router)编译选项,pfifo_fast 就是系统的标准 QDISC。它的队列包括三个波段(band)。在每个波段里面,使用先进先出规则。而三个波段(band)的优先级也不相同,band 0 的优先级最高,band 2 的最低。如果 band0 里面有数据包,系统就不会处理 band 1 里面的数据包,band 1 和 band 2 之间也是一样。数据包是按照服务类型(Type of Service,TOS) 被分配多三个波段(band)里面的。
- red
red 是 Random Early Detection(随机早期探测)的简写。如果使用这种 QDISC,当带宽的占用接近于规定的带宽时,系统会随机地丢弃一些数据包。它非常适合高带宽应用。
- sfq
sfq 是 Stochastic Fairness Queueing 的简写。它按照会话(session–对应于每个TCP连接或者UDP流)为流量进行排序,然后循环发送每个会话的数据包。
- tbf
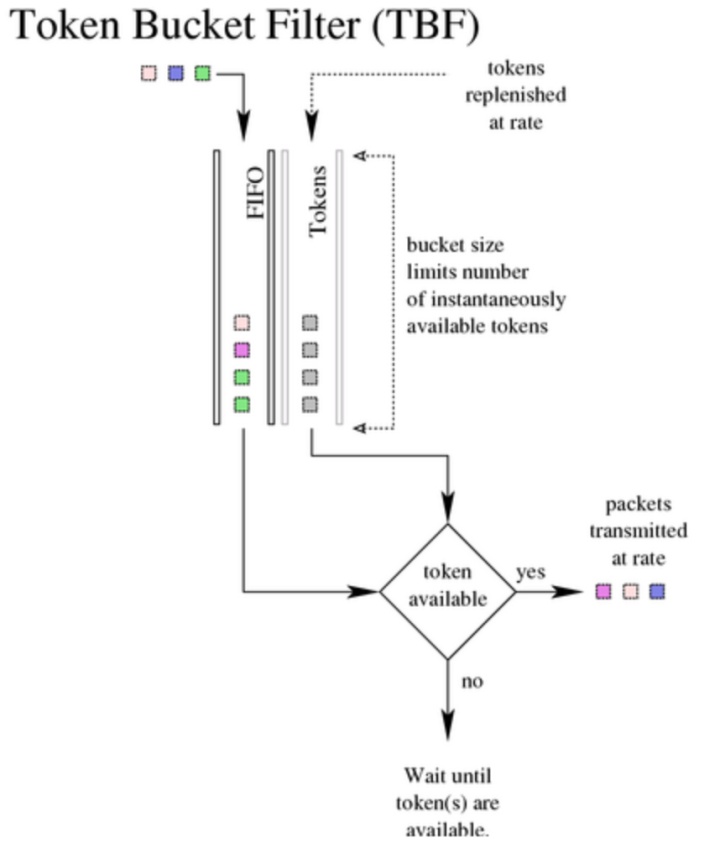
tbf 是 Token Bucket Filter 的简写,适合于把流速降低到某个值。
可分类 QDISC 包括:
- CBQ
CBQ 是 Class Based Queueing(基于类别排队)的缩写。 它实现了一个丰富的连接共享类别结构,既有限制(shaping)带宽的能力,也具有带宽优先级管理的能力。 带宽限制是通过计算连接的空闲时间完成的。 空闲时间的计算标准是数据包离队事件的频率和下层连接(数据链路层)的带宽。
- HTB
HTB 是 Hierarchy Token Bucket 的缩写。 通过在实践基础上的改进,它实现了一个丰富的连接共享类别体系。使用 HTB 可以很容易地保证每个类别的带宽,虽然它也允许特定的类可以突破带宽上限,占用别的类的带宽。
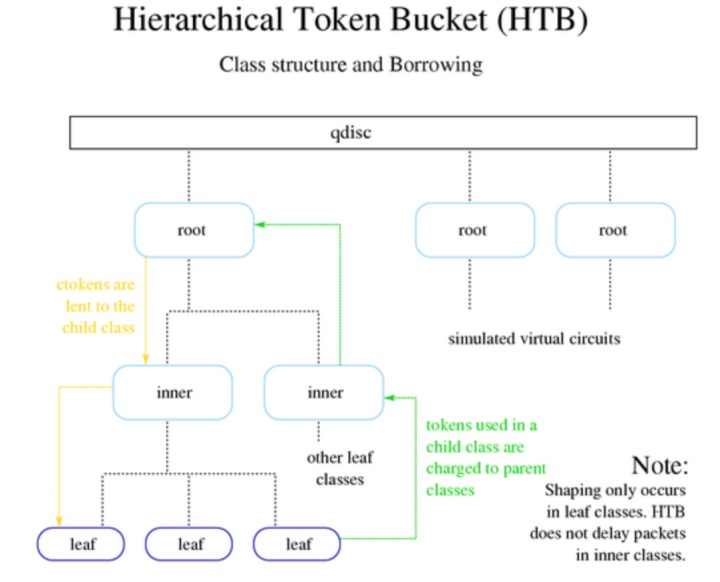
HTB 可以通过 TBF(Token Bucket Filter)实现带宽限制,也能够划分类别的优先级。
关于 HTB 算法的更详细介绍感兴趣,可以看一下这篇文章。
- PRIO
PRIO QDisc 不能限制带宽,因为属于不同类别的数据包是顺序离队的。 使用 PRIO QDisc 可以很容易对流量进行优先级管理,只有属于高优先级类别的数据包全部发送完毕,才会发送属于低优先级类别的数据包。 为了方便管理,需要使用 iptables 或者 ipchains 处理数据包的服务类型(Type Of Service,ToS)。
class 某些 QDisc(排队规则)可以包含一些类别,不同的类别中可以包含更深入的 QDisc(排队规则),通过这些细分的 QDisc 还可以为进入的队列的数据包排队。通过设置各种类别数据包的离队次序,QDisc 可以为设置网络数据流量的优先级。
filter Filter(过滤器)用于为数据包分类,决定它们按照何种 QDisc 进入队列。无论何时数据包进入一个划分子类的类别中,都需要进行分类。分类的方法可以有多种,使用 fileter(过滤器)就是其中之一。使用 filter(过滤器)分类时,内核会调用附属于这个类(class)的所有过滤器,直到返回一个判决。如果没有判决返回,就作进一步的处理,而处理方式和 QDISC 有关。需要注意的是,filter(过滤器)是在 QDisc 内部,它们不能作为主体。
tc 中的规则是按照网络接口各自隔离开的,每个网络接口中,会按照树形结构维护其下的所有规则,每个规则对应了树中的一个节点,每个节点都包含一个唯一的类别标识,又包含一个队列。而过滤器则是根据数据包的特征将其分到更下层规则中的选择器。
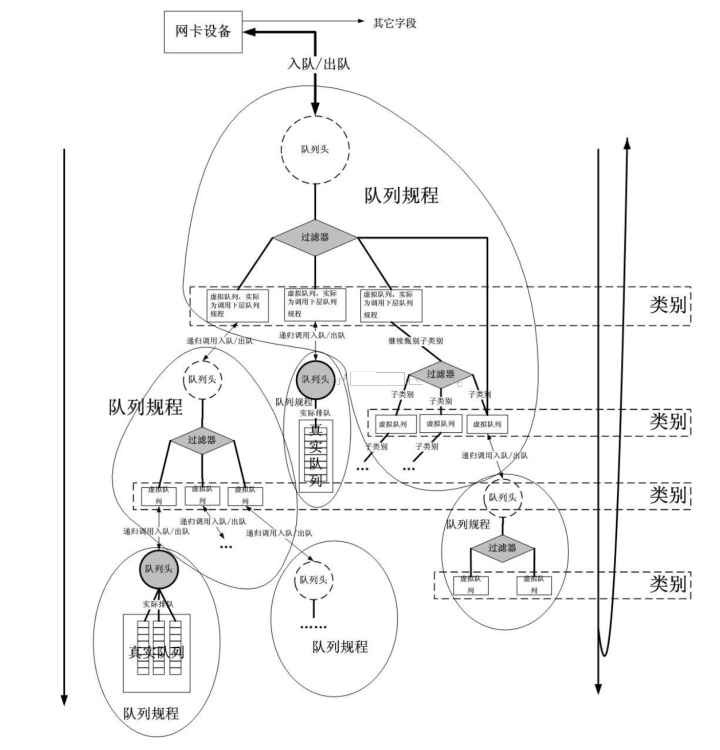
理解了 tc 中三个管理对象的角色之后,我们就开始实际的操作起来吧。因为分类的工作我们已经在 iptables 中处理完了,所以这里我们不会使用到 filter 对象,只会使用到 class 和 qdisc。
# 为 bond0.90 和 bond0.91 这两个网络接口创建根规则
# dev bond0.9X 表明规则要加在哪个网卡
# root 表示为网卡添加的是一个根队列
# handle 1: 表示队列的句柄是 1:
# 队列类型是 htb
# default 9999 表示默认子类别是 9999(1:9999)
tc qdisc add dev bond0.90 root handle 1: htb default 9999 r2q 100
tc qdisc add dev bond0.91 root handle 1: htb default 9999 r2q 100
# 创建默认子规则,防止 iptables 没有分到类
# 这里指定新 class 的父节点是根队列 1:
# 类型编号是1:9999,就和父节点的 default 9999 对应
# 同样采用 htb 队列
# rate 1Gbit 表示带宽权重是 1Gbit,如果父节点带宽够大,则该子分类的带宽至少为 1Gbit
# 可能会获得更高的带宽(如果带宽有冗余),如果父节点带宽不够大,那么多个子节点按照 rate 的值进行等比例分配
# ceil 1Gbit 表示带宽最大值是 1Gbit
# prio 1 表示它们对报文处理的优先级是相同的,对于不同优先级的过滤器, 系统将按照从小到大的优先级处理
# burst cburst 表示突然要发送很大的数据包时,起始速度是多少
tc class add dev bond0.90 parent 1: classid 1:9999 htb prio 1 rate 1Gbit ceil 1Gbit burst 1375b cburst 1375b
tc class add dev bond0.91 parent 1: classid 1:9999 htb prio 1 rate 1Gbit ceil 1Gbit burst 1375b cburst 1375b
# 为 iptables 中分好的 1:2 和 1:3 指定规则
# 其中 1:2 对应从手机发出的包,所以规则应该加在 bond0.91 上
# 1:3 对应的是发往手机的包,所以规则应该加在 bond0.90 上
# 为 1:2 和 1:3 创建对应的 class 并限制它们的带宽
# 假设我们手机下载带宽设置为 100 Mbit,上传带宽设置为 50 Mbit
tc class add dev bond0.90 parent 1: classid 1:3 htb prio 1 rate 100Mbit ceil 100Mbit burst 1600b cburst 1600b
tc class add dev bond0.91 parent 1: classid 1:2 htb prio 1 rate 50Mbit ceil 50Mbit burst 1600b cburst 1600b
# 为 1:2 和 1:3 创建其下的队列,在队列规则中限定数据包的延迟
# 假设我们手机下载延迟设置为 100 ms,上传延迟设置为 50 ms
# netem 表示我们使用 Network Emulator 组件来模拟网络的延迟
# limit 1000 表示等待队列最多包含多少字节
# delay 100ms 表示数据包等待延迟
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms
tc qdisc add dev bond0.91 parent 1:2 handle 5: netem limit 1000 delay 50ms
# 查看当前的所有规则
tc class show dev bond0.90
class htb 1:9999 root prio 1 rate 1Gbit ceil 1Gbit burst 1250b cburst 1250b
class htb 1:3 root leaf 4: prio 1 rate 100Mbit ceil 100Mbit burst 1600b cburst 1600b
tc class show dev bond0.91
class htb 1:9999 root prio 1 rate 1Gbit ceil 1Gbit burst 1250b cburst 1250b
class htb 1:2 root leaf 5: prio 1 rate 50Mbit ceil 50Mbit burst 1600b cburst 1600b
tc qdisc show dev bond0.90
qdisc htb 1: root refcnt 2 r2q 100 default 9999 direct_packets_stat 0 direct_qlen 1000
qdisc netem 4: parent 1:3 limit 1000 delay 100.0ms
tc qdisc show dev bond0.91
qdisc htb 1: root refcnt 2 r2q 100 default 9999 direct_packets_stat 0 direct_qlen 1000
qdisc netem 5: parent 1:2 limit 1000 delay 50.0ms下图总结了上述的的配置内容,它们分别由网络接口出发,以树形结构维护,根节点是两个 qdisc 配置,这两个根节点只加了默认子类的设定 1:9999(带宽限制 1Gbit),这两个默认子类是用来处理 iptables 中未分类的数据。对于 iptables 中分类的数据包,即手机的数据包,每个手机都有属于自己的子类,如 1:2 和 1:3,这两个类中分别定义了手机上传和下载的带宽。在这两个类型下,又细化地进行了队列的配置,从而限制了数据包的延迟。
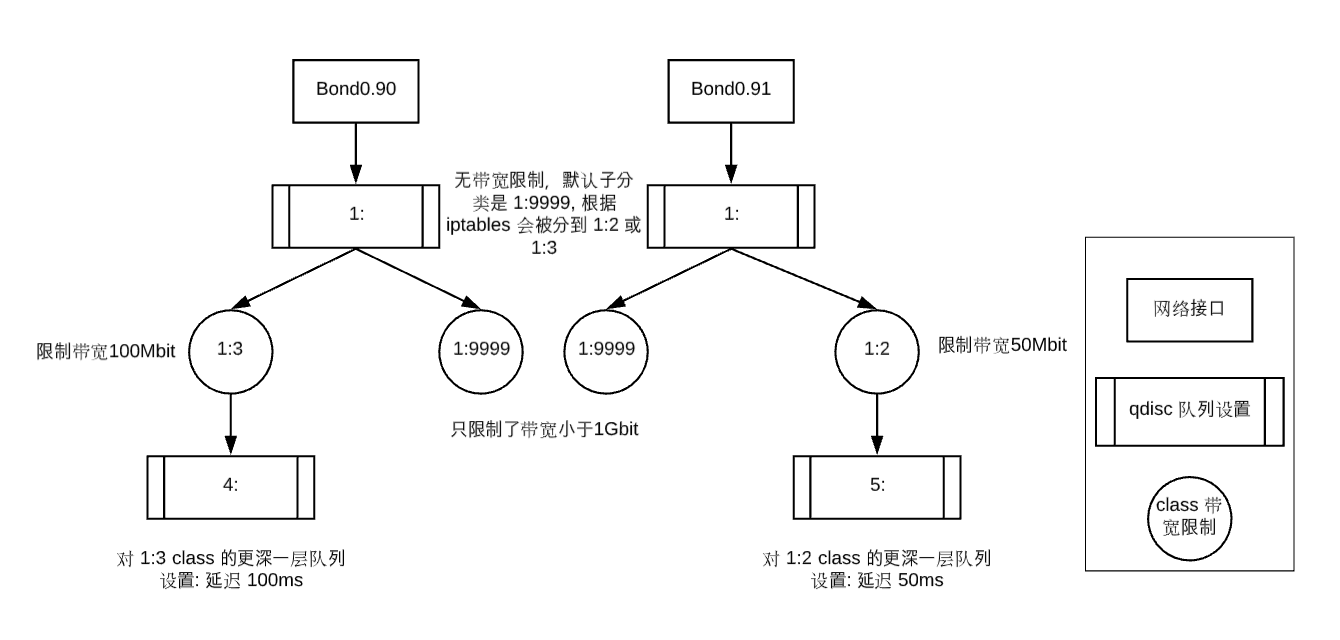
这里除了简单的延迟之外,我们还可以定义很多与延迟相关的参数。
- JITTER:抖动,增加一个随机时间长度,让延迟时间出现在某个范围
- CORRELATION:相关,下一个报文延迟时间和上一个报文的相关系数
- distribution:分布,延迟的分布模式,可以选择的值有 uniform、normal、pareto 和 paretonormal
JITTER 应该很好理解,如果设置 20ms,那么报文的延迟在会在 100ms +- 20 ms 之间波动。
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms 20msCORRELATION 指相关性,因为网络状况是平滑变化的,短时间里相邻报文的延迟应该是近似的而不是完全随机的。这个值是个百分比,如果为 100%,就退化到固定延迟的情况;如果是 0% 则退化到随机延迟的情况。
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms 20ms 50%报文的分布和很多现实事件一样都满足某种统计规律,比如最常用的正态分布。因此为了更逼近现实情况,可以使用 distribution 参数来限制它的延迟分布模型。比如让报文延迟时间满足正态分布:
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms 20ms distribution normal除了延迟相关的设置之外,我们还能指定诸如丢包率,重复包,坏包,乱序等情况,这里只做简单的演示,更详细的参数介绍可以参考文档。
# 丢包
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms loss 50%
# 重复包
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms duplicate 50%
# 坏包
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms corrupt 2%
# 乱序
tc qdisc add dev bond0.90 parent 1:3 handle 4: netem limit 1000 delay 100ms reorder 2%参考内容
[1] https://zh.wikipedia.org/wiki/%E9%93%BE%E8%B7%AF%E8%81%9A%E5%90%88
[2] http://koolshare.cn/thread-10008-1-1.html
[3] https://www.jianshu.com/p/4b46586e79aa
[4] http://blog.itpub.net/31015730/viewspace-2150185/
[5] https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/deployment_guide/sec-configuring_a_vlan_over_a_bond
[6] https://www.tecmint.com/setup-a-dns-dhcp-server-using-dnsmasq-on-centos-rhel/
[7] https://www.lijiawang.org/posts/linux-bond.html
[8] http://abcdxyzk.github.io/blog/2016/03/09/kernel-net-bonding/
[9] http://m.cfan.com.cn/pcarticle/125997
[10] https://www.cnblogs.com/embedded-linux/p/9345899.html
[11] https://lrita.github.io/images/posts/linux/%E6%B7%B1%E5%BA%A6%E5%88%86%E6%9E%90Linux%E4%B8%8B%E5%8F%8C%E7%BD%91%E5%8D%A1%E7%BB%91%E5%AE%9A%E4%B8%83%E7%A7%8D%E6%A8%A1%E5%BC%8F.pdf
[12] https://blog.51cto.com/linuxnote/1680315
[13] https://blog.51cto.com/lixin15/1769338
[14] https://sstompkins.wordpress.com/2010/04/01/%E5%9B%9E%E5%BF%86l2l3%E4%BA%A4%E6%8D%A2%E5%99%A8%E7%9A%84%E5%8E%9F%E7%90%86/
[15] https://blog.csdn.net/pengpengjy/article/details/79057252
[16] https://wiki.archlinux.org/index.php/Dnsmasq_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
[17] https://baike.baidu.com/item/DHCP
[18] https://tonydeng.github.io/sdn-handbook/linux/iptables.html
[19] https://qwertwwwe.github.io/Linux-iptables-information/
[20] https://tonydeng.github.io/sdn-handbook/basic/dhcp.html
[21] http://codeshold.me/2017/01/tc_detail_inro.html
[22] https://blog.7street.top/2018/03/27/tc/
[23] https://www.cnblogs.com/CasonChan/p/5033956.html
[24] https://cizixs.com/2017/10/23/tc-netem-for-terrible-network/
[25] https://www.cnblogs.com/acool/p/7779159.html
[26] http://perthcharles.github.io/2015/06/12/tc-tutorial/
- 本文作者: 贝克街的流浪猫
- 本文链接:https://www.beikejiedeliulangmao.top/JNI-%E8%B0%83%E8%AF%95%E6%8A%80%E6%9C%AF/
- 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
- 创作声明: 本文基于上述所有参考内容进行创作,其中可能涉及复制、修改或者转换,图片均来自网络,如有侵权请联系我,我会第一时间进行删除。
















 1515
1515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









