







前言
在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
为了克服上述的问题,项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
redis技术就是NoSQL技术中的一种,但是引入redis又有可能出现缓存穿透,缓存击穿,缓存雪崩等问题。
一、 缓存击穿
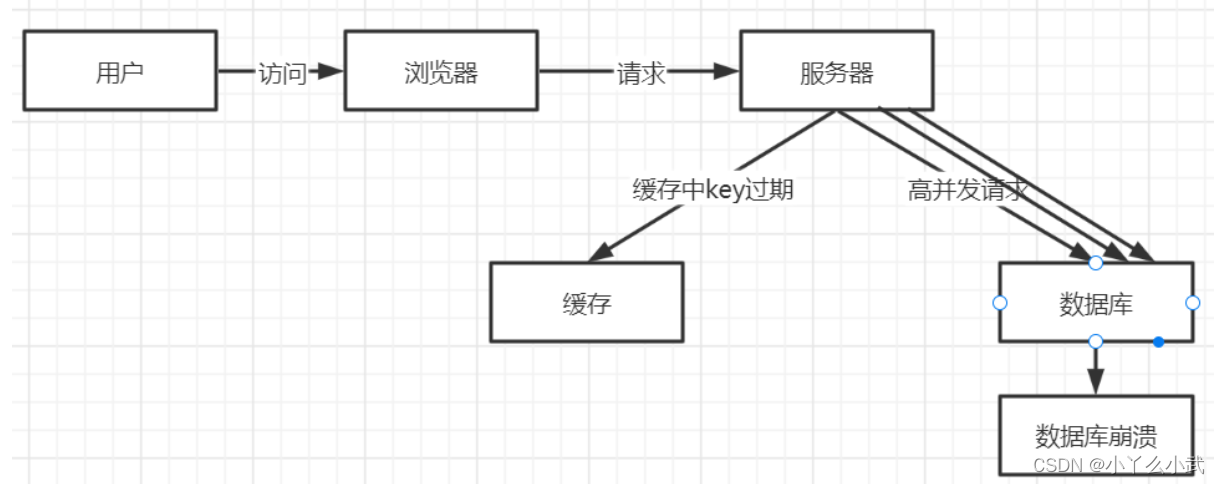
当访问的某一个key过期,此时可能存在缓存击穿。大量请求打到数据库上。
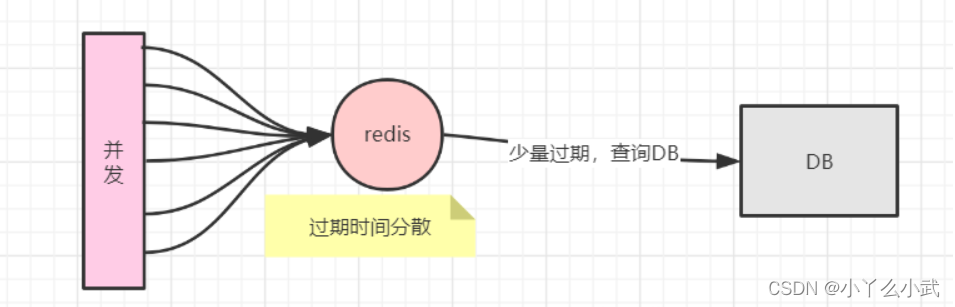
缓存设置时设置一个随机时间可减少击穿概率。
①对于热点key设置永不过期。
②预先设置热门数据:在redis高峰访问时期,提前设置热门数据到缓存中,或适当延长缓存中key过期时间。
③实时调整:实时监控哪些数据热门,实时调整key过期时间。
④分布式锁: 采用分布式锁的方法,重新设计缓存的使用方式,过程如下:
上锁:当我们通过 key 去查询数据时,首先查询缓存,如果没有,就通过分布式锁进行加锁,第一个获取锁的进程进入后端数据库查询,并将查询结果缓到Redis 中。
解锁:当其他进程发现锁被某个进程占用时,就进入等待状态,直至解锁后,其余进程再依次访问被缓存的 key。
二、 缓存雪崩
批量的key中对应数据库数据存在,在某一时刻,缓存中大量key同时过期,而此时大量高并发请求访问,会透过直缓存接访问后端数据库,导致数据库崩溃。
注意:缓存击穿是指一个key对应缓存数据过期,缓存雪崩是大部分key对应缓存数据过期。
public Product create(Product product) {
Product productResult = productDao.create(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),
genProductCacheTimeout(), TimeUnit.SECONDS);
return productResult;
}
private Integer genProductCacheTimeout() {
return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60;
}
三 、缓存穿透
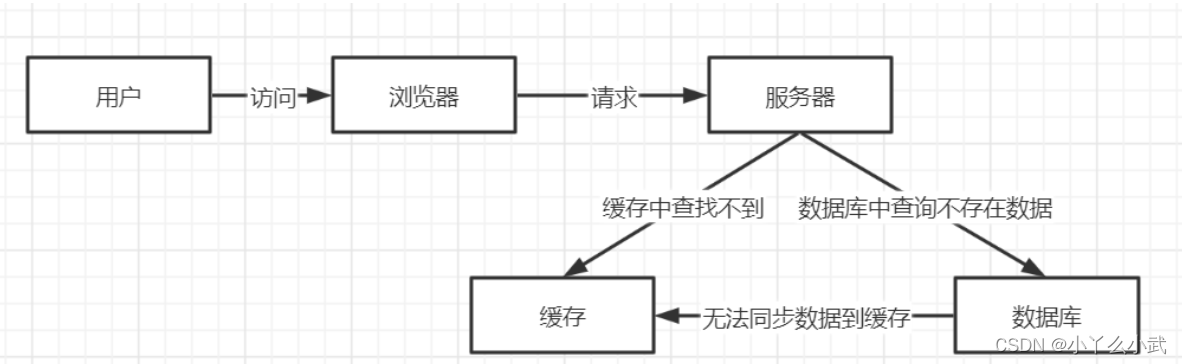
1、假设有个热门商品,很多人访问,突然间后台管理员误删了此商品,这时大量请求过来,缓存和数据库都没有,数据将承受很大压力。
可以将空结果设置到缓存中,但是时间不宜太久,如果太多空缓存攻击的话,会存在很多空缓存,大量占用内存。
(或者黑客发送大量不存在的ID请求服务器,会有大量请求打到数据库,造成数据库压力过大)
try {
product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//RLock updateProductLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock rLock = readWriteLock.readLock();
rLock.lock();
try {
product = productDao.get(productId);
if (product != null) {
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(productCacheKey, product);
} else {
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
} finally {
rLock.unlock();
}
} finally {
hotCacheLock.unlock();
}
2、布隆过滤器
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
三、冷热数据分离
缓存设置过期时间,冷门数据到时间自动过期,热门数据会持续有人访问,过期之后缓存重建,降低数据库压力。
private Product getProductFromCache(String productCacheKey) {
Product product = productMap.get(productCacheKey);
if (product != null) {
return product;
}
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
if (EMPTY_CACHE.equals(productStr)) {
//空数据设置一个空缓存,设置超时时间,防止一段时间内出现重复攻击
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
}
//热点数据在查询到数据之后,重置超时时间可以让热门数据一直不过期,读延期
product = JSON.parseObject(productStr, Product.class);
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期
}
return product;
}
冷热数据全部设置过期时间,冷数据无人访问,到期自动失效。热数据在查询到的时候自动续期,让热数据在缓存中一直存在。
重点就在于:热点数据在查询到数据之后,redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
重置超时时间可以让热门数据一直不过期
四、冷门数据缓存重建问题
冷门数据突然间热门起来,防止大量请求访问数据库,需要缓存重建。
可以使用双重检测锁,使用“缓存+过期时间”的策略既可以加速数据读写, 又保证数据的定期更新, 这种模式基本能够满足绝大部分需求。 但是有两个问题如果同时出现, 可能就会对应用造成致命的危害:
当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
重建缓存不能在短时间完成, 可能是一个复杂计算, 例如复杂的SQL、 多次IO、 多个依赖等。
在缓存失效的瞬间, 有大量线程来重建缓存, 造成后端负载加大, 甚至可能会让应用崩溃。
要解决这个问题主要就是要避免大量线程同时重建缓存。
我们可以利用互斥锁来解决,此方法只允许一个线程重建缓存, 其他线程等待重建缓存的线程执行完, 重新从缓存获取数据即可。
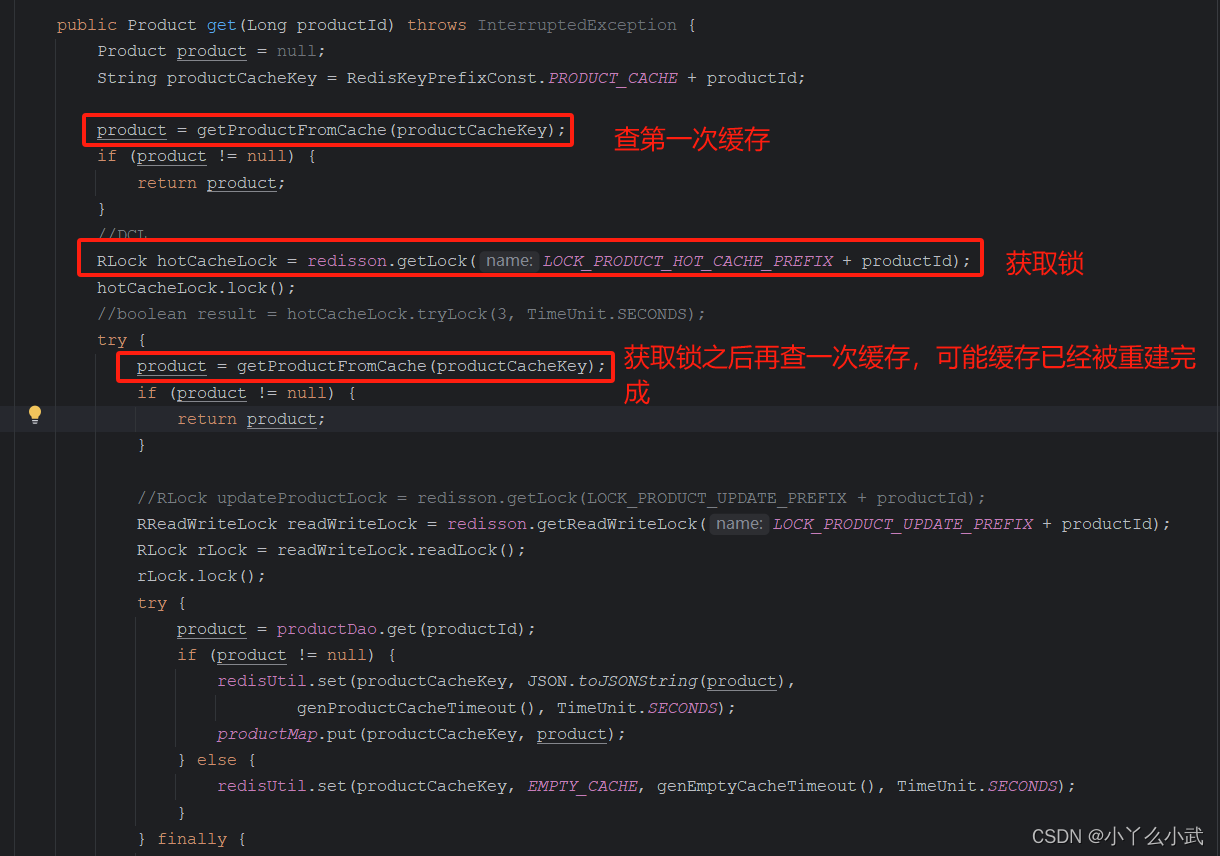
public Product get(Long productId) throws InterruptedException {
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
//第一重检测
product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//DCL 加一把分布式锁,此处只有一个线程可以进入查询逻辑,重置缓存
RLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId);
hotCacheLock.lock();
//boolean result = hotCacheLock.tryLock(3, TimeUnit.SECONDS);
try {
//查询数据库前第二重检测,后续其他线程进来缓存已经有了
product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//RLock updateProductLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock rLock = readWriteLock.readLock();
rLock.lock();
try {
product = productDao.get(productId);
if (product != null) {
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(productCacheKey, product);
} else {
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
} finally {
rLock.unlock();
}
} finally {
hotCacheLock.unlock();
}
return product;
}
private Product getProductFromCache(String productCacheKey) {
Product product = productMap.get(productCacheKey);
if (product != null) {
return product;
}
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
if (EMPTY_CACHE.equals(productStr)) {
//空数据设置一个空缓存,设置超时时间,防止一段时间内出现重复攻击
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
}
product = JSON.parseObject(productStr, Product.class);
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //读延期
}
return product;
}
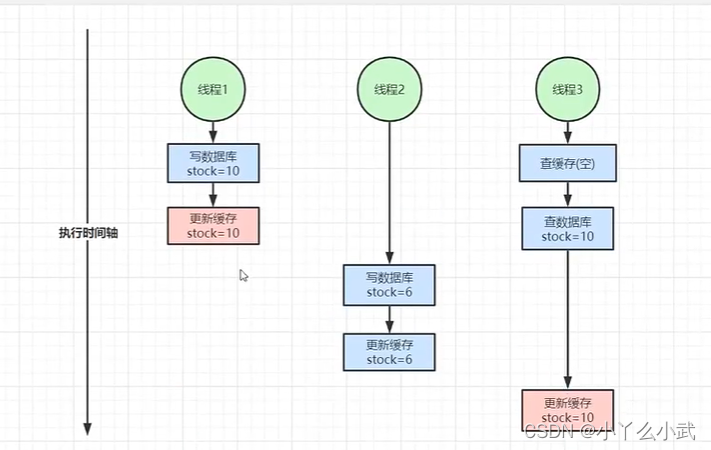
五、缓存数据库双写不一致
先读到数据的线程操作数据时慢了,导致其他线程后读先改,导致数据不一致
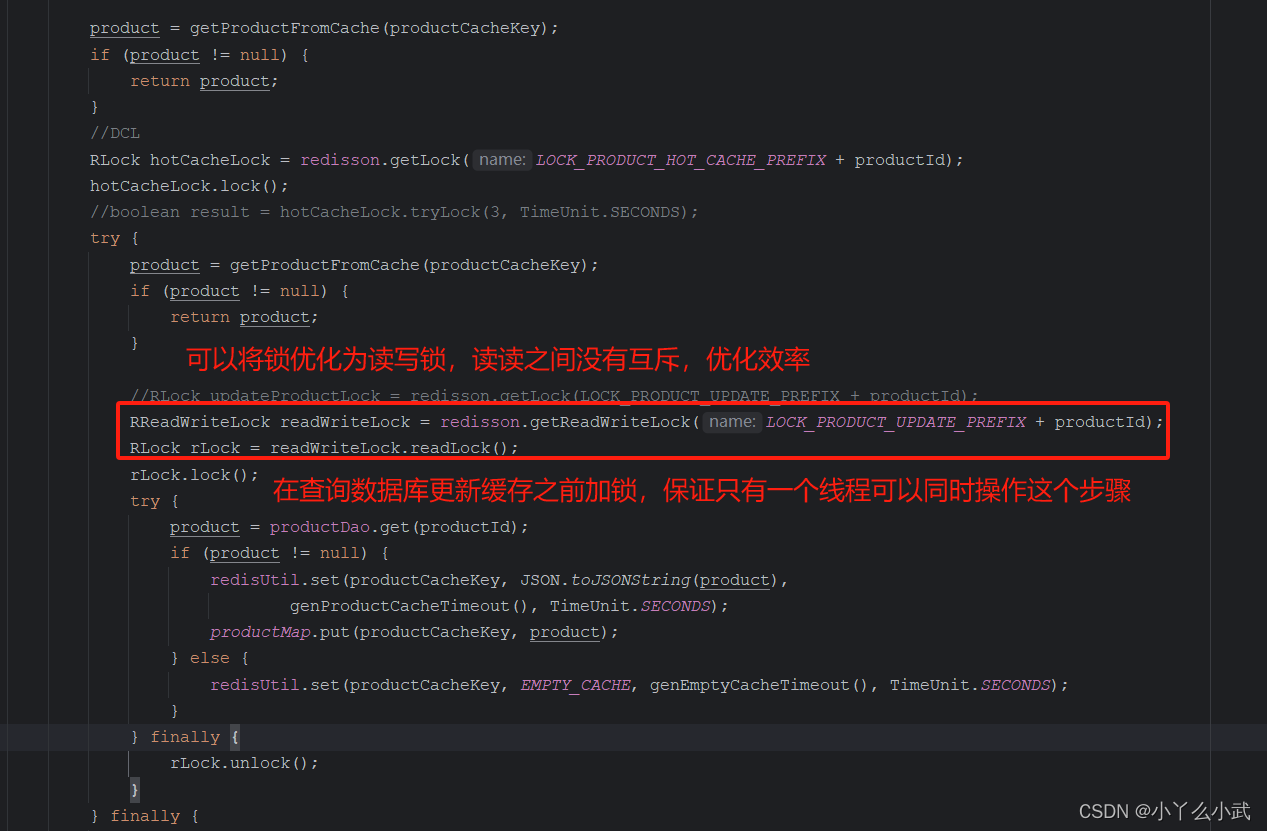
解决方案在查询数据库和更线缓存这段逻辑加上锁,使整个过程具有原子性,保证不被其他线程打断,从而避免双写不一致问题。代码实现如下代码块中。
try {
product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//在此处加一把锁,保证读数据库和操作缓存是原子操作。避免双写不一致问题出现(即保证数据库和redis缓存是原子性操作)
//RLock updateProductLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock rLock = readWriteLock.readLock();
rLock.lock();
try {
product = productDao.get(productId);
if (product != null) {
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
productMap.put(productCacheKey, product);
} else {
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
}
} finally {
rLock.unlock();
}
} finally {
hotCacheLock.unlock();
}
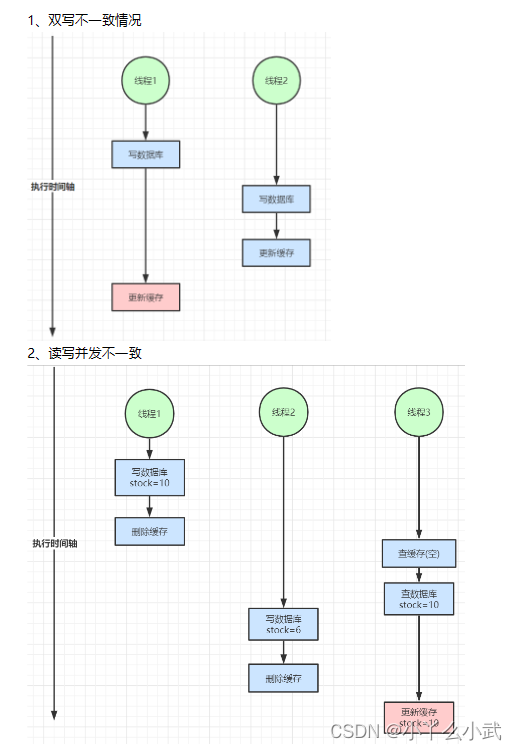
删除缓存的场景,还提供延迟双删策略解决问题,在线程2删除缓存之后,延迟一段时间,再次删除缓存。此时可删除线程3更新的缓存结果。(注意:但是这个方案会损耗性能,所以谨慎选择)
解决方案:
1、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
2、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
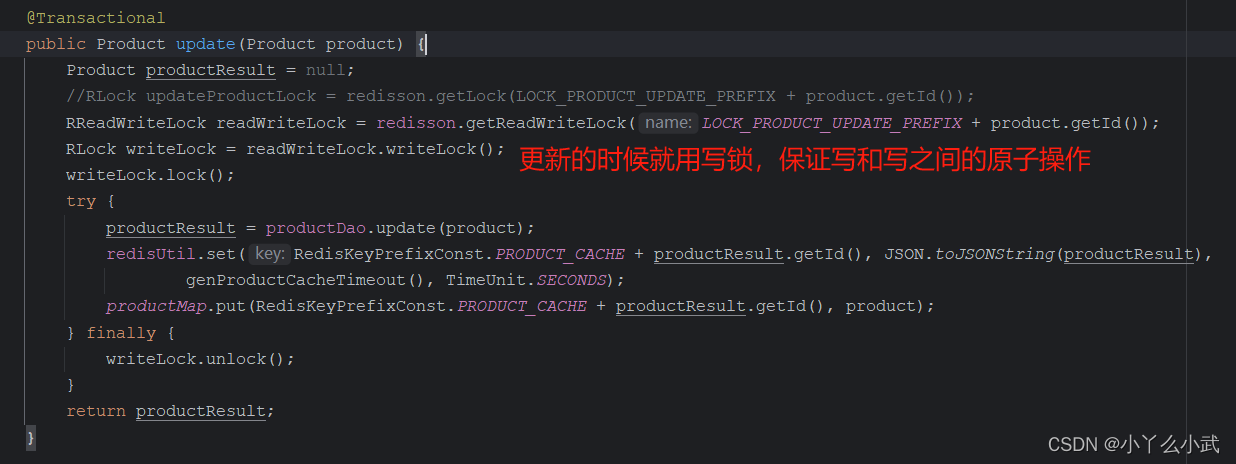
3、如果不能容忍缓存数据不一致,可以通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
4、也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。
六、Redis对于过期键清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
主动清理策略
在Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略,总共8种:
a) 针对设置了过期时间的key做处理: - volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
b) 针对所有的key做处理: - allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
- allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
c) 不处理: - noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作。
LRU 算法(Least Recently Used,最近最少使用)
淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
LFU 算法(Least Frequently Used,最不经常使用)
淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。这时使用LFU可能更好点。
根据自身业务类型,配置好maxmemory-policy(默认是noeviction),推荐使用volatile-lru。如果不设置最大内存,当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap),会让 Redis 的性能急剧下降。当Redis运行在主从模式时,只有主结点才会执行过期删除策略,然后把删除操作”del key”同步到从结点删除数据。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









