





目的
通过爬取基金持仓信息,我们可以了解基金的资金流向,说白了,就是知道大型基金公司都买了什么股票,买了多少。也可以跟踪一些知名的基金,看看他们都买了什么股票,从而跟买或者不买,估值便宜的股票,又有很多基金入场,很可能这家公司大家都非常看好,未来业绩很可能增长,可能是一次比较好的投资机会;而有些股票,估值已经很高了,里边还有很多的基金公司,这就需要注意了,很可能基本面发生一点点恶化,或者达不到预期,基金公司可能就会大幅的抛售,导致股价大跌。
本文分上、下两个部分。
第一部分,讲解如何爬取数据并存储到mysql数据库。
第二部分,对爬取出来的数据进行可视化分析。
1分析要爬取的网页数据
需要获取所有的基金代码
http://fund.eastmoney.com/allfund.html
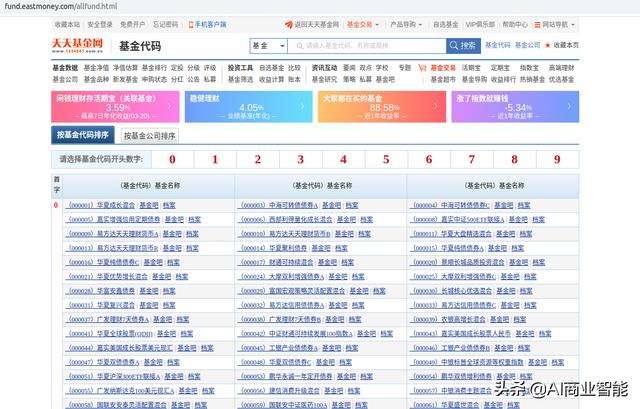
获取基金里的前10大持仓数据
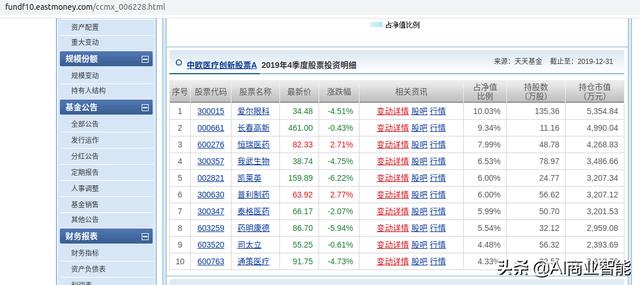
2确定获取数据页面后开始写代码
导入包
"""爬取天天基金持仓数据"""from bs4 import BeautifulSoupimport timeimport pandas as pdimport requestsimport datetimefrom selenium import webdriverfrom sqlalchemy import create_enginefrom lxml import etree#连接数据库engine = create_engine('mysql+pymysql://root:123456@localhost/tushare_db?charset=utf8mb4')#请求头headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}插入数据库
def insert_sql(data): # 使用try...except..continue避免出现错误,运行崩溃 try: #jjcc_data 数据库表名 data.to_sql("jjcc_data", engine,if_exists='append', index=False) except Exception as e: print(e)解析详细页面,获取前10大持仓股
因为网页抓取后需要渲染才能获得数据所以使用selenium包的webdriver。
def get_info(url): option = webdriver.ChromeOptions() option.add_argument('headless') option.add_argument('no-sandbox') option.add_argument('disable-dev-shm-usage') driver = webdriver.Chrome('/usr/local/bin/chromedriver',options=option) driver.maximize_window() driver.get(url) driver.implicitly_wait(5) day = datetime.date.today() today = '%s' % day with open('test.html', 'w', encoding='utf-8') as f: f.write(driver.page_source) time.sleep(1) file = open('test.html', 'r', encoding='utf-8') soup = BeautifulSoup(file, 'lxml') driver.quit() try: fund = soup.select('#bodydiv > div > div > div.basic-new > div.bs_jz > div.col-left > h4 > a')[0].get_text() scale = soup.select('#bodydiv > div > div.r_cont > div.basic-new > div.bs_gl > p > label > span')[2].get_text().strip().split()[0] table = soup.select('#cctable > div > div > table') trs = table[0].select('tbody > tr') for tr in trs: code = tr.select('td > a')[0].get_text() name = tr.select('td > a')[1].get_text() price = tr.select('td > span')[0].get_text() try: round(float(price), 2) except ValueError: price = 0 num = tr.select('td.tor')[3].get_text() market = float(num.replace(',', '')) * float(price) data = { 'crawl_date': today, 'code': code, 'fund': fund.split(' (')[0], 'scale': scale, 'name': name, 'price': round(float(price), 2), 'num': round(float(num.replace(',', '')), 2), 'market_value': round(market, 2) } data=pd.DataFrame([data]) insert_sql(data) except IndexError: info = { 'url': url } print(info)获取所有的基金代码,循环调用get_info
def get_code(url): html = requests.get(url, headers=headers) html.encoding = 'gbk' document = etree.HTML(html.text) info = document.xpath('// *[ @ id = "code_content"] / div / ul / li / div / a[1] /text()') i = 0 for fund in info: str = fund.split(')')[0] code = str.split('(')[1] url = 'http://fundf10.eastmoney.com/ccmx_%s.html' % code get_info(url)if __name__ == "__main__": found_url = 'http://fund.eastmoney.com/allfund.html' get_code(found_url)好了,4段简单的代码就可以讲天天基金网里的数据都爬取到数据库里了。
下次给大家讲解如何用爬到的数据做可视化分析。
谢谢关注















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









