






前言
我们在数据读取和处理的时候,常常会遇到很不规整的数据,需要我们自己去写脚本或者程序去批量处理,这个工作是很常见的,并且对于遍历的时候如何正确运用os、open、pandas、re等都是十分重要的,对于我们的数据主要分为.csv .txt等等,对于其他很多类型比如DAT其实和.csv的读取相似,都是用pandas去读取较为方便处理,而对于可以用Notepad++来打开的文本文件,一般来说pandas处理较为不方便或者不能处理,一般都是用open来打开进行遍历每一行进行处理的,这里我对处理这些文件做一个小小的总结和总体写的框架的分享。
一、文件的组成
这边demo我设计为差不多四层,如下图所示,不在赘述

这边我使用jupyter lab去编写.ipynb的程序,位置关系如下:
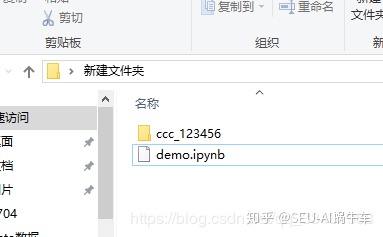
二、读取文件夹名称
首先我们需要先利用os读取每个最底层文件夹名称 这里都是基本的代码写法,我不想做过多说明,自行捋一下肯定都明白了。
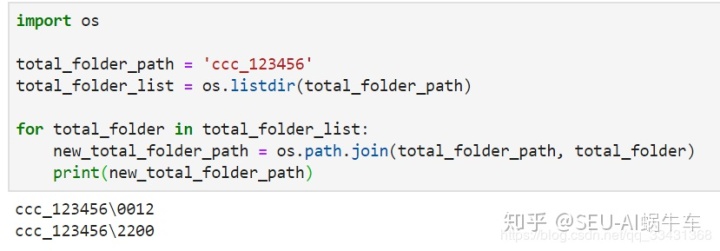
之后我们获取每个底层文件夹中的所有文件,也就是说我们要处理这些文件我们需要得到 这些所有最终文件的相对路径。 这边的做法就是再来一次一样的操作进行循环遍历即可获得,如下:
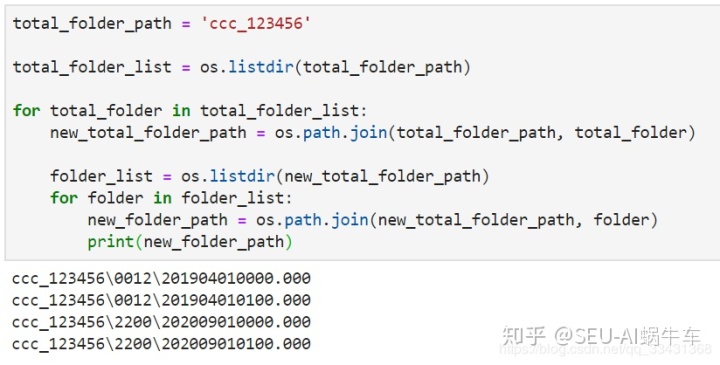
步骤如下: 1. os.listdir得到这个路径文件夹下一层的所有文件名,并组成list 2. 通过这个list进行每个文件夹名遍历,并利用os.path.join形成对应于上一层的绝对路径 3. 利用这个思维可以嵌套出下下层的所有文件路径
三、读取文本内容
3.1 读文本内容
很多很不常见的格式比如.000等文本格式,其实都是可以用Notepad++打开,基本上都是用open来读取 文件为
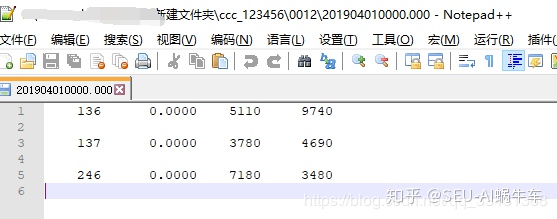
代码如下:
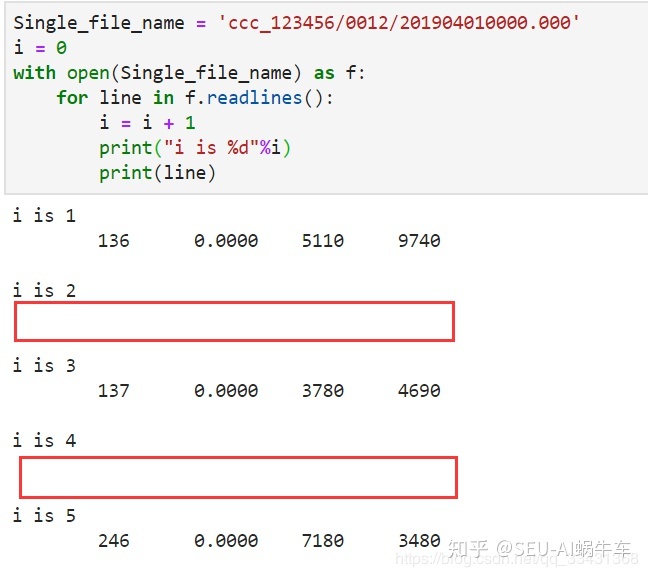
可见空行依然会读出来, 我这里设置i的作用就是让大家一下子明白for循环的那句的具体作用是读取文本中的每一行内容。
3.2 内容解析
首先看看读取的是什么类型的。
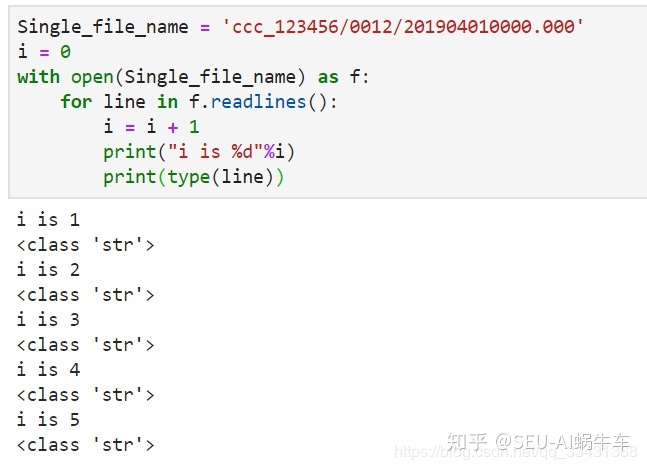
读取的都是string类型。
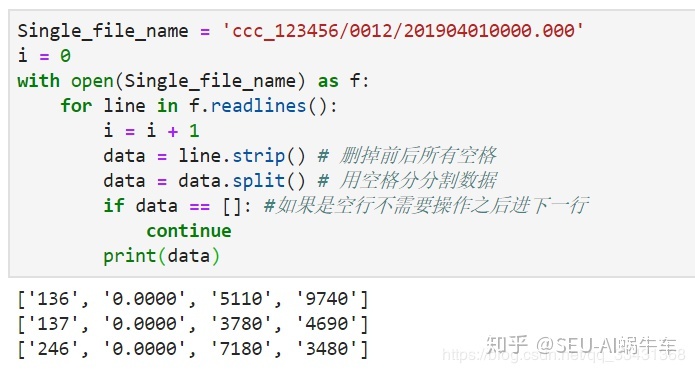
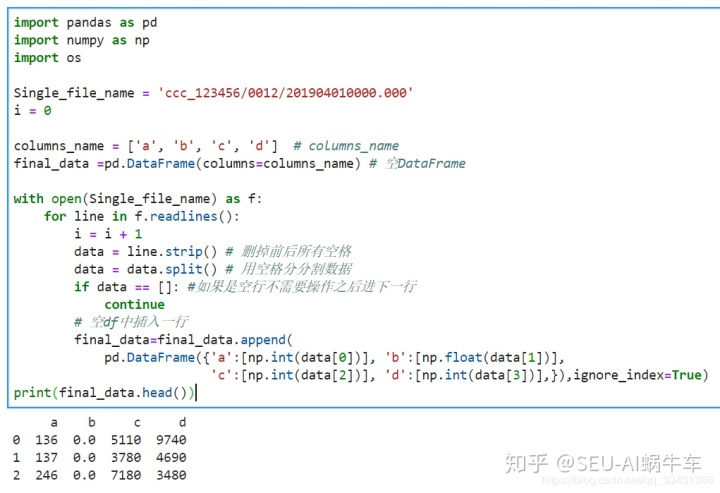
取出来之后一般都尝试着把所有的数据整理到一起输出.csv文件或者.h5文件,这里为了让大家看到更直观,我们生成.csv,主要思路就是创建一个空的dataframe,之后把每一个line的数据进行插入,当然在插入之前需要最好确定下columns和每一个插入的数据的具体类型。 这里除了第二列都是int型。
3.3 输出文件

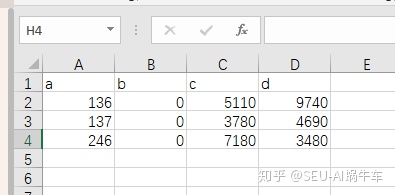
打开如下:
四、总体完整程序
import 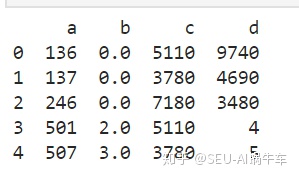
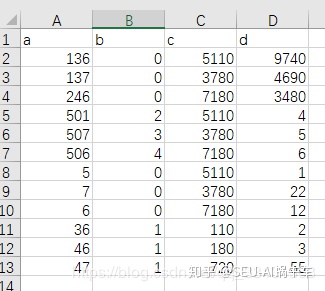
五、总结
- 主要思路就是先读到每个文本的绝对路径之后进行打开读取。
- 以上代码可以稍作修改就可以用在读者您的数据处理问题上,当然是在绝大部分情况下。














 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









