





知乎上有一个问题是这样的:
堆排序是渐进最优的比较排序算法,达到了O(nlgn)这一下界,而快排有一定的可能性会产生最坏划分,时间复杂度可能为O(n^2),那为什么快排在实际使用中通常优于堆排序?
昨天刚好写了一篇关于快排优化的文章,今天再多做一个比较吧。首先先看一个排序算法图:
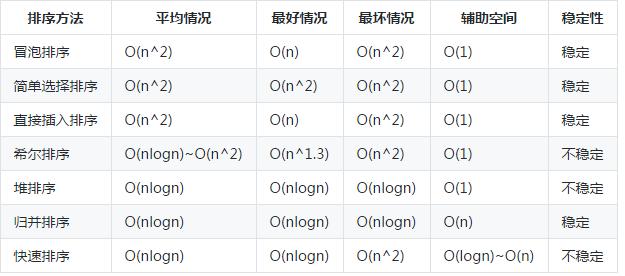
可以看到,到达nlogn级别的排序算法,一共有三种,分别是堆排序,归并排序以及快速排序,其中只有归并排序最稳定。那么,为什么要说快速排序的平均情况是最快的呢?
实际上在算法分析中,大O的作用是给出一个规模的下界,而不是增长数量的下界。因此,算法复杂度一样只是说明随着数据量的增加,算法时间代价增长的趋势相同,并不是执行的时间就一样,这里面有很多常量参数的差别,比如在公式里各个排序算法的前面都省略了一个c,这个c对于堆排序来说是100,可能对于快速排序来说就是10,但因为是常数级所以不影响大O。
另外,即使是同样的算法,不同的人写的代码,不同的应用场景下执行时间也可能差别很大。下面是一个测试数据:
测试的平均排序时间:数据是随机整数,时间单位是s数据规模 快速排序 归并排序 希尔排序 堆排序1000万 0.75 1.22 1.77 3.575000万 3.78 6.29 9.48 26.54 1亿 7.65 13.06 18.79 61.31堆排序每次取一个最大值和堆底部的数据交换,重新筛选堆,把堆顶的X调整到位,有很大可能是依旧调整到堆的底部(堆的底部X显然是比较小的数,才会在底部),然后再次和堆顶最大值交换,再调整下来,可以说堆排序做了许多无用功。
总结起来就是,快排的最坏时间虽然复杂度高,但是在统计意义上,这种数据出现的概率极小,而堆排序过程里的交换跟快排过程里的交换虽然都是常量时间,但是常量时间差很多。














 5878
5878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









