






1 引言
数据统计是PostgreSQL中重要的组成部分,PostgreSQL的SQL优化、执行方式为代价模型。而这里的各路径的代价计算,则是依赖于系统表中的统计信息。
2 统计信息的来源
pg_statistic系统表里的数据不易查看,可以通过视图pg_stats查看
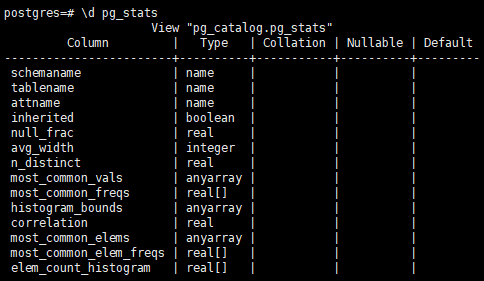
attname:列名,对应pg_attribute的attname
Inherited:如果为真,那么这行包含继承的子字段,不只是指定表的值
null_frac:字段为空的百分比
avg_width:平均宽度(字节)
n_distinct:如果大于零,就是非重复值的数量。如果小于零,则是非重复值的个数除以行数然后取负。(用负数形式是因为analyze认为非重复值的数目是随着表增长而增长的;用正数表示字段看上去好像有固定数量的可能值)比如-1表示在某一列中的非重复值与总行数相同
most_common_vals:高频值列表
most_common_freqs:高频值出现的频率
histogram_bounds:值列表,用于将列的值划分为大致相等的总体
correlation:统计字段值的物理顺序和逻辑顺序的关联性
most_common_elems:经常在字段值中出现的非空元素值的列表
most_common_elem_freqs:最常见元素值的频率列表
elem_count_histogram:该字段中值的不同非空元素值的统计直方图,跟着不同非空元素的平均值
创个简单点的表看一下
postgres=# create table test1(id int,info text); iCREATE TABLE postgres=# insert into test1 select n,'test' from generate_series(1,100) as n; INSERT 0 100 postgres=# analyze test1; ANALYZE postgres=# select * from pg_stats where tablename = 'test1' and attname = 'id'; -[RECORD1 ]----------+---------------------------------------------------------------------------------------------- schemaname | public tablename | test1 attname | id inherited | f null_frac | 0 avg_width | 4 n_distinct | -1 most_common_vals | most_common_freqs | histogram_bounds| {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100} correlation | 1 most_common_elems | most_common_elem_freqs | elem_count_histogram | 可以看到,n_distinct为-1,说明id列全是非重复值;histogram_bounds为值分布的区间;most_common_vals和most_common_freqs为空,说明没有相对的高频值;correlation为1,代表逻辑顺序和存储的物理顺序相同,因为此处我是顺序存储的。假如为-1,就代表逻辑顺序和物理顺序相反。如下: postgres=# create table test2(id int); CREATE TABLE postgres=# insert into test2 values(generate_series(5,1,-1)); INSERT 0 5 postgres=# analyze test2; ANALYZE postgres=# select correlation from pg_stats where tablename = 'test2'; correlation ------------- -1 (1 row) |
重新建一个表,其中info列将数字转为字符,ret列大约1%结果为true
postgres=# create table test3(id int,info t |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









