







 本文介绍了如何使用SQL进行数据计数查询,包括对全表记录的统计以及通过CASE语句筛选特定字段值的计数。示例查询展示了从'dxp_msg_receive'表中统计各类型消息的数量。
本文介绍了如何使用SQL进行数据计数查询,包括对全表记录的统计以及通过CASE语句筛选特定字段值的计数。示例查询展示了从'dxp_msg_receive'表中统计各类型消息的数量。
查询计数sql主要用到select,count。
可以先查询计数某个字段的总数,再筛选出某个值并计数。
总计数sql如下:
select count(*) from "dxp_msg_receive"; #dxp_msg_receive 为某张表。
添加筛选值sql如下:
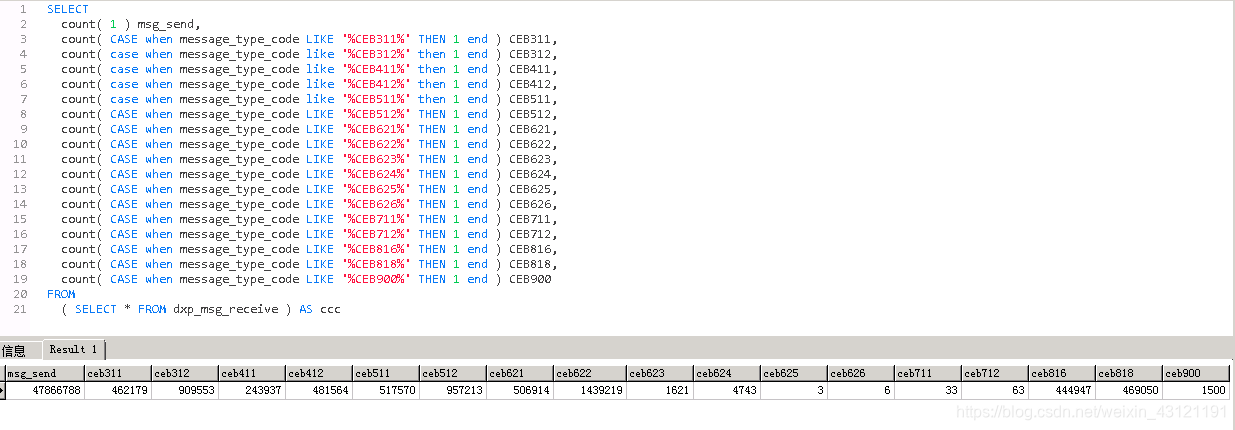
SELECT
count( 1 ) msg_send,
count( CASE when message_type_code LIKE '%CEB311%' then 1 end ) CEB311,
count( case when message_type_code like '%CEB312%' then 1 end ) CEB312,
count( case when message_type_code like '%CEB411%' then 1 end ) CEB411,
count( case when message_type_code like '%CEB412%' then 1 end ) CEB412,
count( case when message_type_code like '%CEB511%' then 1 end ) CEB511,
count( CASE when message_type_code LIKE '%CEB512%' then 1 end ) CEB512,
count( CASE when message_type_code LIKE '%CEB621%' then 1 end ) CEB621,
count( CASE when message_type_code LIKE '%CEB622%' then 1 end ) CEB622,
count( CASE when message_type_code LIKE '%CEB623%' then 1 end ) CEB623,
count( CASE when message_type_code LIKE '%CEB624%' then 1 end ) CEB624,
count( CASE when message_type_code LIKE '%CEB625%' then 1 end ) CEB625,
count( CASE when message_type_code LIKE '%CEB626%' then 1 end ) CEB626,
count( CASE when message_type_code LIKE '%CEB711%' then 1 end ) CEB711,
count( CASE when message_type_code LIKE '%CEB712%' then 1 end ) CEB712,
count( CASE when message_type_code LIKE '%CEB816%' then 1 end ) CEB816,
count( CASE when message_type_code LIKE '%CEB818%' then 1 end ) CEB818,
count( CASE when message_type_code LIKE '%CEB900%' then 1 end ) CEB900
FROM
( SELECT * FROM dxp_msg_receive ) AS ccc
查询结果:

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









