





代码不是看出来的,而是敲出来的,欢迎关注公众号,收藏教程,跟着步骤练习爬虫,成为真正的Spider Man。
在第一篇教程里(不跳步骤新手python爬虫教程(一))我们学习了安装python、运行python、下载IDE: Pycharm(代码编辑器)以及浏览器的网络请求等相关知识内容。
在第二篇教程里(不跳步骤新手python爬虫教程(二))认识了两种网络协议http、https、对请求行与请求头Request URL、Request Headers、Query String等参数、requests模块的相关方法、获取网页原码的三种方式进行了讲解。最后我们以百度首页和百度翻译两个页面调用requests库进行了抓包。
在第三篇教程里(不跳步骤的新手python爬虫系列教程(三))讲解了设置响应超时的timeout参数、retrying模块、携带cookie请求的相关知识点。
在第四篇教程里(不跳步骤的新手python爬虫系列教程(四))学习了数据提取方法json、数据提取方法json、步骤三:json.dumps()的相关方法。下面紧接着开始爬虫第五篇教程的学习。
步骤一:下载xpath helper插件
xpath是一门从html提取数据的语言,是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
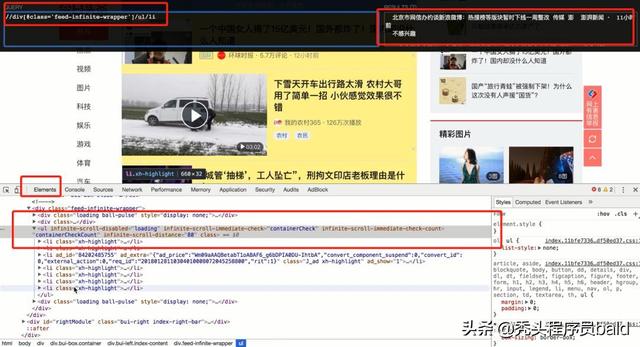
首先我们需要下载chrome浏览器的xpath helper插件:帮助我们从elements中定位数据。当然爬虫是无法爬取到elements的内容。XPath Helper可以支持在网页点击元素生成xpath,整个抓取使用了xpath、正则表达式、消息中间件、多线程调度框架的chrome插件。
xpath helper插件是一款免费的chrome爬虫网页解析工具。可以帮助用户解决在获取xpath路径时无法正常定位等问题。该插件主要能帮助你在各类网站上通过按shift键选择想要查看的页面元素来提取查询其代码,同时你还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中。
1.首先用户点击谷歌浏览器右上角的自定义及控制按钮,在下拉框中选择工具选项,然后点击扩展程序来启动Chrome浏览器的扩展管理器页面。
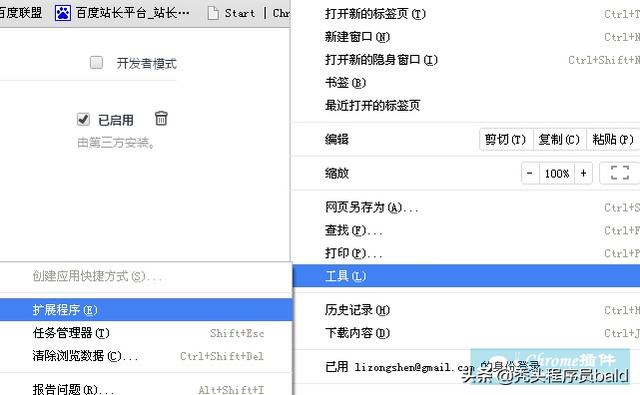
2.在打开的谷歌浏览器的扩展管理器中用户可以看到一些已经安装程序的Chrome插件,或者一个Chrome插件也没有。
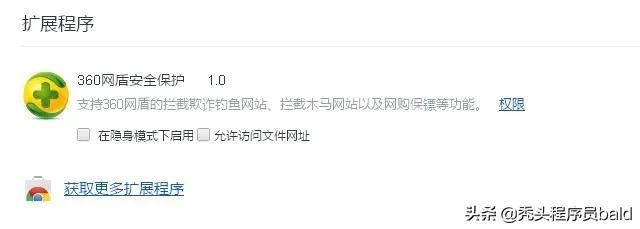
3.找到自己已经下载好的Chrome离线安装文件xxx.crx,然后将其从资源管理器中拖动到Chrome的扩展管理界面中,这时候用户会发现在扩展管理器的中央部分中会多出一个”拖动以安装“的插件按钮。
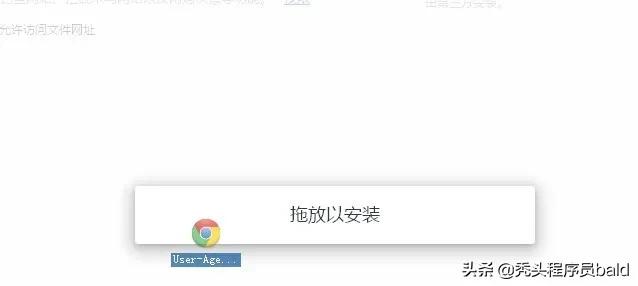
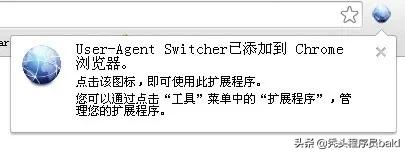
4.松开鼠标就可以把当前正在拖动的插件安装到谷歌浏览器中去,但是谷歌考虑用户的安全隐私,在用户松开鼠标后还会给予用户一个确认安装的提示。

5.用户这时候只需要点击添加按钮就可以把该离线Chrome插件安装到谷歌浏览器中去,安装成功以后该插件会立即显示在浏览器右上角(如果有插件按钮的话),如果没有插件按钮的话,用户还可以通过Chrome扩展管理器找到已经安装的插件。
步骤二:xpath语法
1.“/”选择节点(标签):
- ‘/html/head/meta’:能够选择html head中所有meta标签
2.“//”从任意节点开始选择
- “//li”选择页面上所有li标签
- “/html/head//link”选择head下所有的link标签
3."@"符号的用途
- 选择具体的某个元素:“//div[@class = ‘content’]/ul/li”
- 选择class = ‘content’ 的div下的ul的li
- “/a/@href”获取选择的a的href的值
4.获取文本
- /a/text():获取a的文本
- /a//text():获取a下所有的文本
5.“./a”当前节点下的a标签
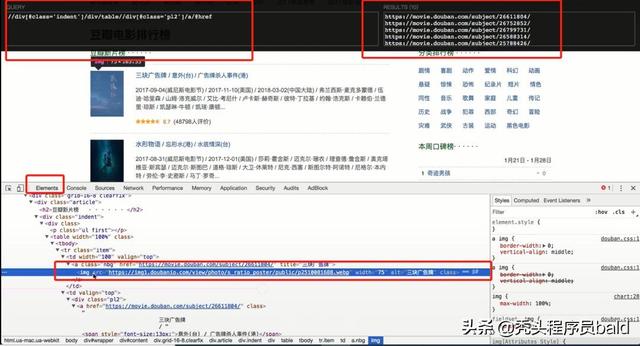
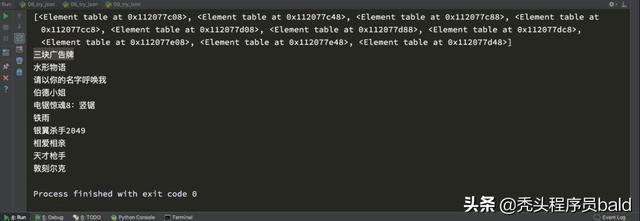
# coding=utf-8from lxml import etreeimport requestsurl = "https://movie.douban.com/chart"headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}response = requests.get(url,headers=headers)html_str = response.content.decode()# print(html_str)#使用etree处理数据html = etree.HTML(html_str)print(html)#1.获取所有的电影的url地址url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")# print(url_list)#2.所有图片的地址img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")# print(img_list)#3.需要吧每部电影组成一个字典,字典中是电影的更重数据,比如标题,url,图片地址,评论数,评分# 思路: #1.分组 #2.每一组提取数据ret1 = html.xpath("//div[@class='indent']/div/table")print(ret1)for table in ret1: item = {} item["title"]=table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip() item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0] item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0] item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0] item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0] print(item)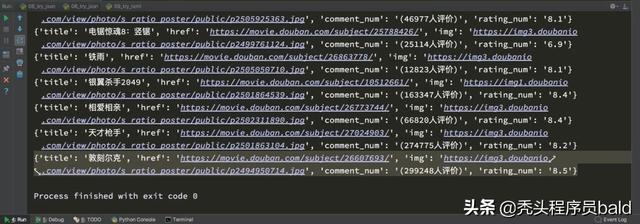
关注公众号【秃头程序员】,不错过不跳步骤的新手python爬虫教程(六)
(原创文章文字图片禁止转载,禁止用于商业用途,转载公众号请后台留言申请。图文部分来自网络,若有侵权,请联系删除)















 3947
3947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









