





# 开篇导包
一、数据聚合 —— df.groupby()详解
DataFrame参数:
- by: 用作分组的条件对象。(mapping, function, label, or list of labels)
- axis: 轴方向。({0 or ‘index’, 1 or ‘columns’}, default 0)
- level: 索引层级,针对多层索引。(int, level name, or sequence of such, default None)
- as_index: 是否把分组后的组标签作为索引。(bool, default True)
- sort: 是否对分组标签进行排序。(bool, default True)
- group_keys: 调用apply时,是否将组键添加到索引以标识片段。(bool, default True)
- squeeze: 是否对返回值进行维度压缩。(bool, default False)
- observed: 是否显示所有分类值。(bool, default False)
- dropna: 是否删除组键里的NA值。(bool, default True)
返回值:
- DataFrameGroupBy
(一)参数详解
1. by参数
# 导入案例数据
输出:
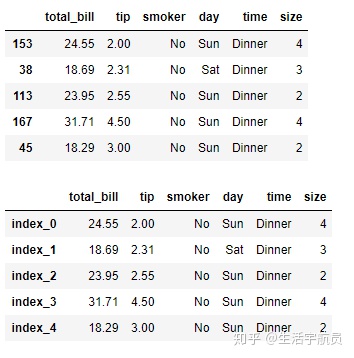
1.1 传入单个label
# 传入单个label
输出:
1.2 传入多个label
# 传入多个label
输出:
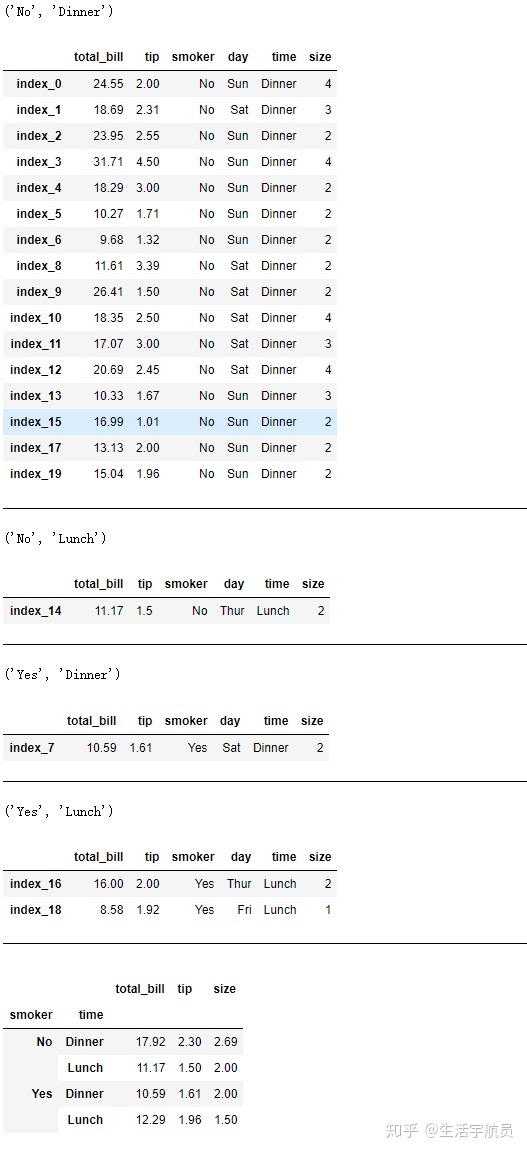
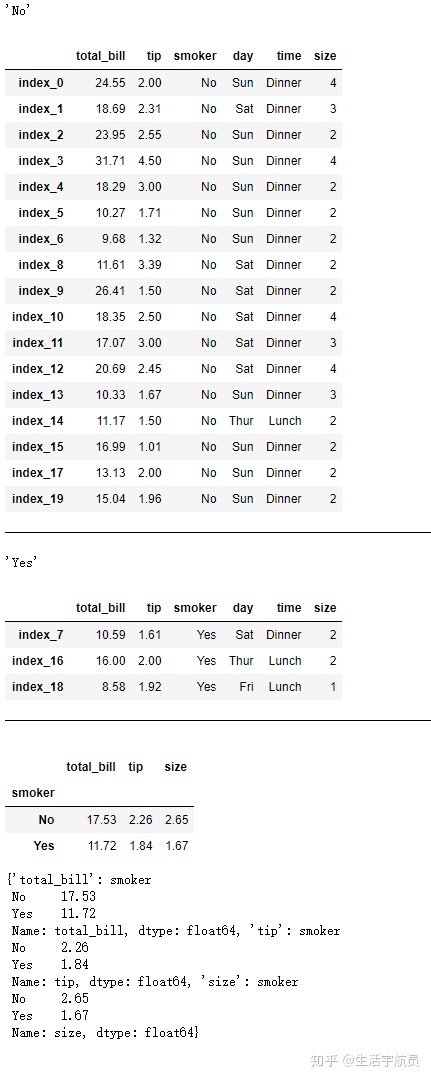
1.3 传入一个映射关系mapping
# 传入一个映射关系mapping
输出:
1.4 传入一个function
grp 输出:
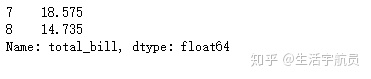
2. axis参数
# 导入案例数据
输出:
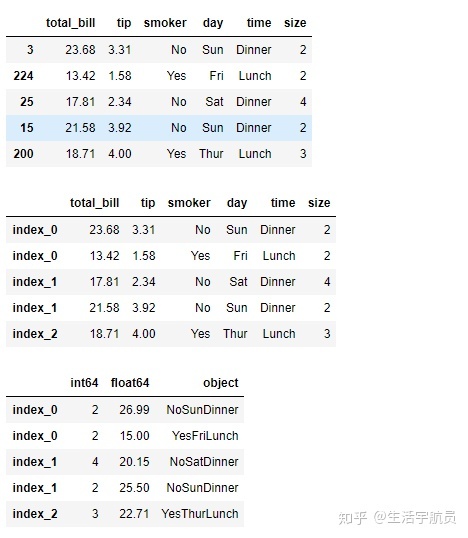
3. level参数
# 导入案例数据
输出:
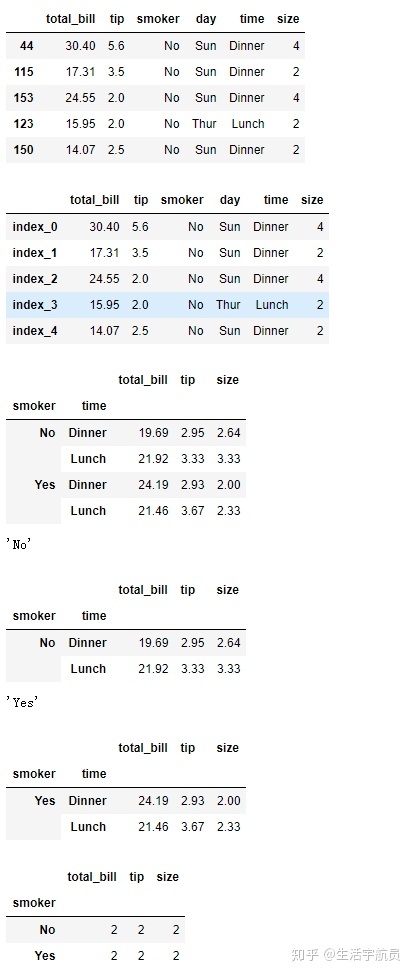
4. as_index参数
# 导入案例数据
输出:
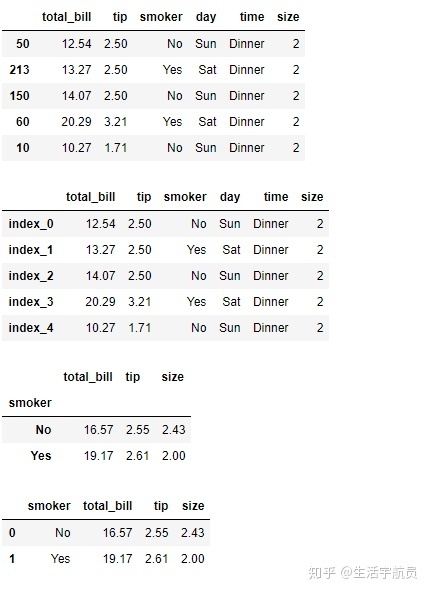
5. sort参数
# 导入案例数据
输出:
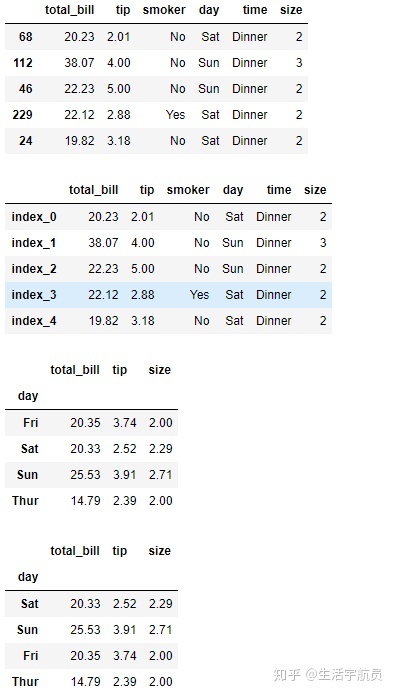
6. group_keys
group_keys 参数在 apply 操作中很方便,它创建了一个与分组标签[group_keys=True]相对应的额外索引列。
# 导入案例数据
输出:
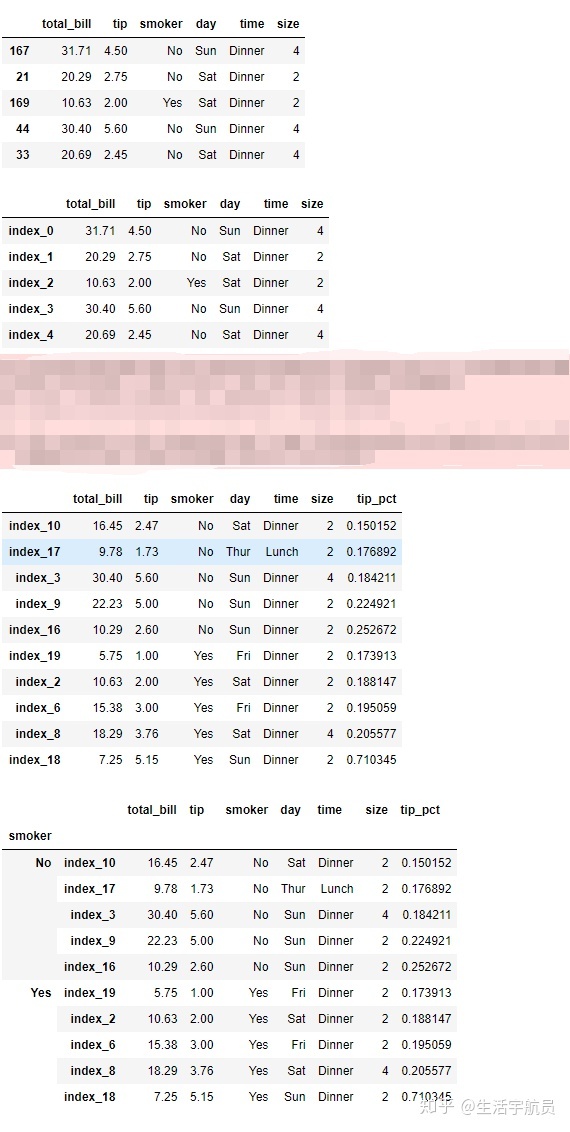
7. squeeze参数(新版本已经移除,可略过)
df1 输出:
8. observed参数(新增,没有搞清楚有啥用处,待补充)
# 导入案例数据
输出:
9. dropna参数
# 导入案例数据
输出:
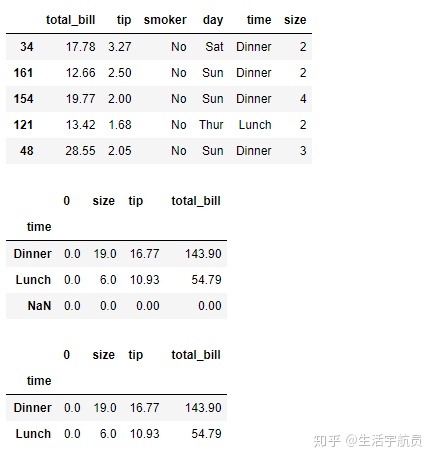
(二)df.groupby() 与 agg方法的联合使用
# 导入案例数据
输出:
# 1
输出:
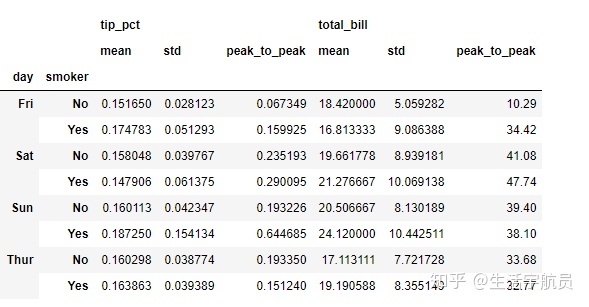
# 2
输出:
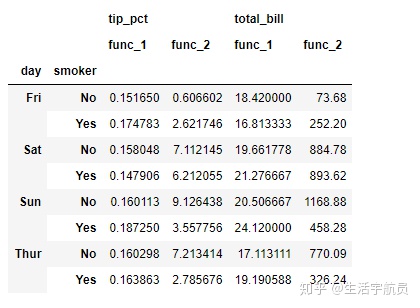
# 3
输出:
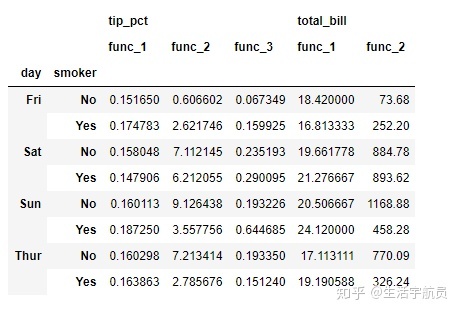
(三)df.groupby() 与 apply方法的联合使用
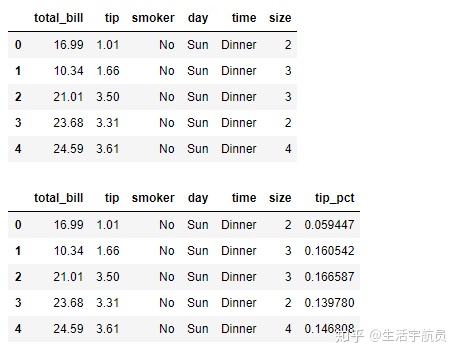
# 导入案例数据
输出:
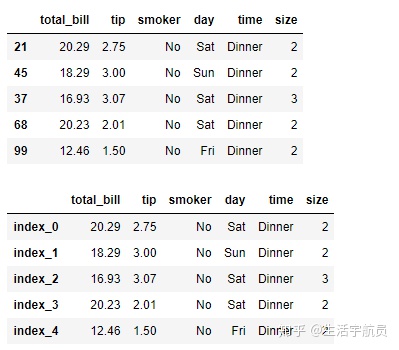
# 1
输出:
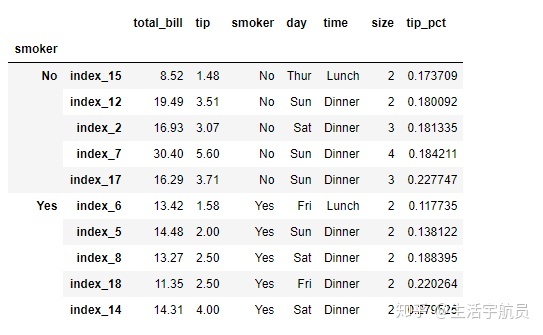
# 如果传入的函数还有其他参数的话,可以把这些参数放在函数后进行传递
输出:
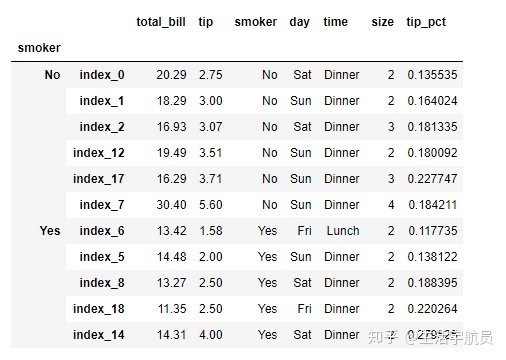
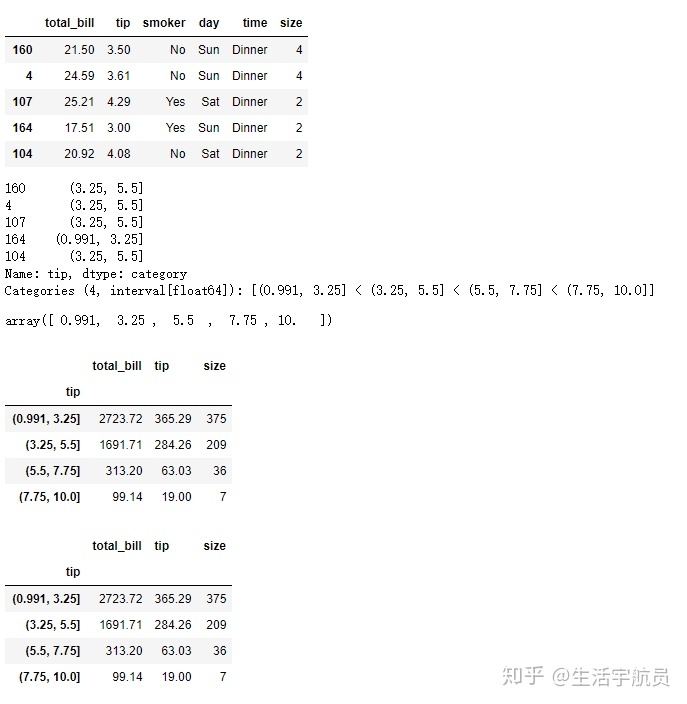
(四)df.groupby() 与 pd.cut()方法的联合使用
# 导入案例数据
输出:
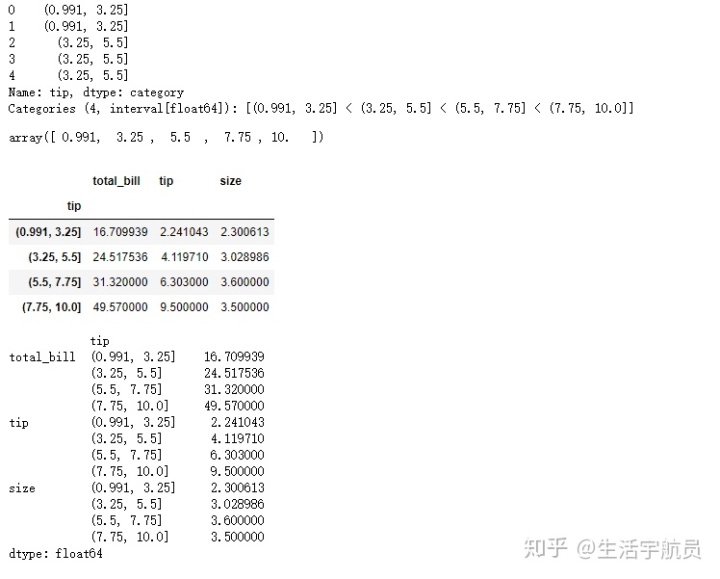
# 分箱
输出:
示例
pass二、数据透视
(一)pd.pivot_table()
pandas参数:
- data: 目标DataFrame
- values: 需要聚合的列名,默认情况下聚合所有数值型的列
- index: 在结果透视表的行上进行分组的列名或者其他分组键 (column, Grouper, array, or list of the previous)
- columns: 在结果透视表的列上进行分组的列名或者其他分组键 (column, Grouper, array, or list of the previous)
- aggfunc: 对数据进行聚合时的函数 (function, list of functions, dict, default numpy.mean)
- fill_value: 用来替换结果表中缺失值的值 (scalar, default None)
- margins: 是否添加行/列小计和总计 (bool, default False)
- dropna: 是否删除所有条目均为NaN的列 (bool, default True)
- margins_name: 小计和总计行/列的名字(str, default ‘All’)
- observed: 是否显示所有分类值 (bool, default False)
返回值:
- DataFrame: An Excel style pivot table.
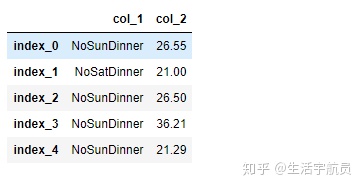
# 导入案例数据
输出:
# index and values
输出:
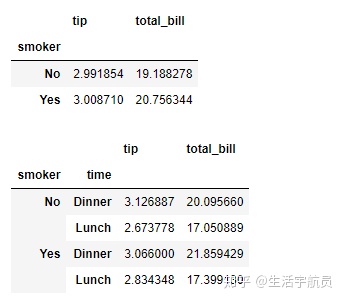
# columns
输出:
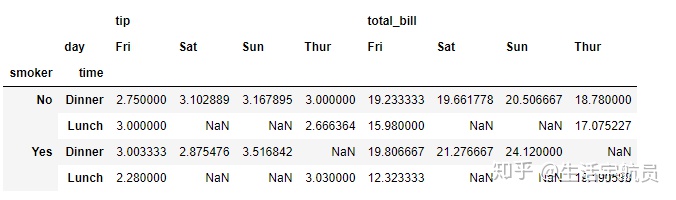
# aggfunc
输出:
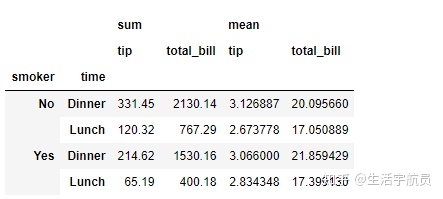
# fill_value
输出:
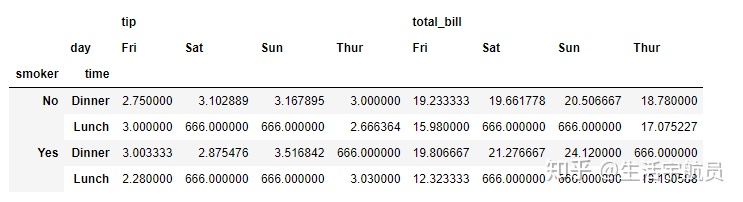
# margins and margin_name
输出:
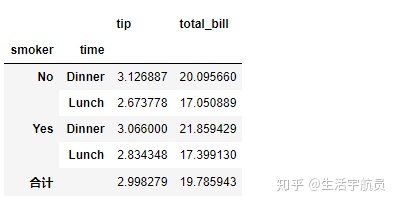
pd.crosstab()
pandas参数:
- index: 在结果透视表的行上进行分组的列 (array-like, Series, or list of arrays/Series)
- columns: 在结果透视表的列上进行分组的列 (array-like, Series, or list of arrays/Series)
- values: 进行聚合的目标列,需要同时传入aggfunc参数 (array-like, optional)
- rownames: 结果透视表中行索引的名称,需要与index参数中的数量保持一致 (sequence, default None)
- colnames: 结果透视表中列索引的名称,需要与columns参数中的数量保持一致 (sequence, default None)
- aggfunc: 聚合函数 (function, optional)
- margins: 是否添加行/列小计和总计 (bool, default False)
- margins_name: 小计和总计行/列的名字(str, default ‘All’)
- dropna: 是否删除所有条目均为NaN的列 (bool, default True)
- normalize: 是否进行标准化 (bool, {‘all’, ‘index’, ‘columns’}, or {0,1}, default False)
- If passed ‘all’ or True, will normalize over all values.
- If passed ‘index’ will normalize over each row.
- If passed ‘columns’ will normalize over each column.
- If margins is True, will also normalize margin values.
返回值:
- DataFrame: Cross tabulation of the data.
# 导入案例数据
输出:
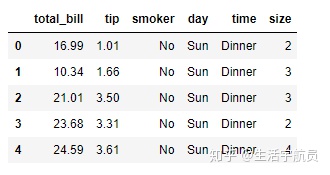
# index、columns、values、aggfunc、rownames、columns、margins、margins_name
输出:
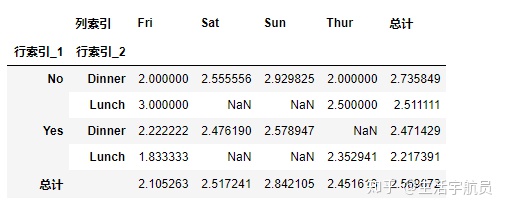
# normalize
输出:
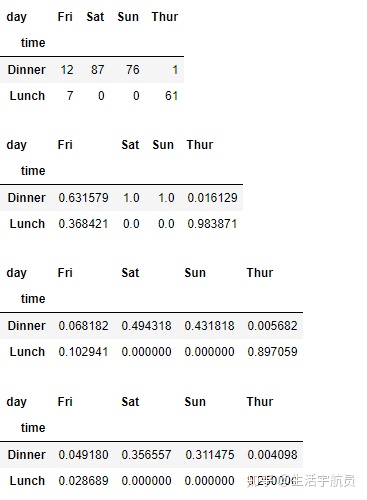















 9097
9097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









