







1.前言 如果mysql实例连接数满掉了,脑袋里蹦出的第一个想法是先增大max_connection,但有种情况,解决方案却是减少max_connection。
2.冰中火 看看这张图:
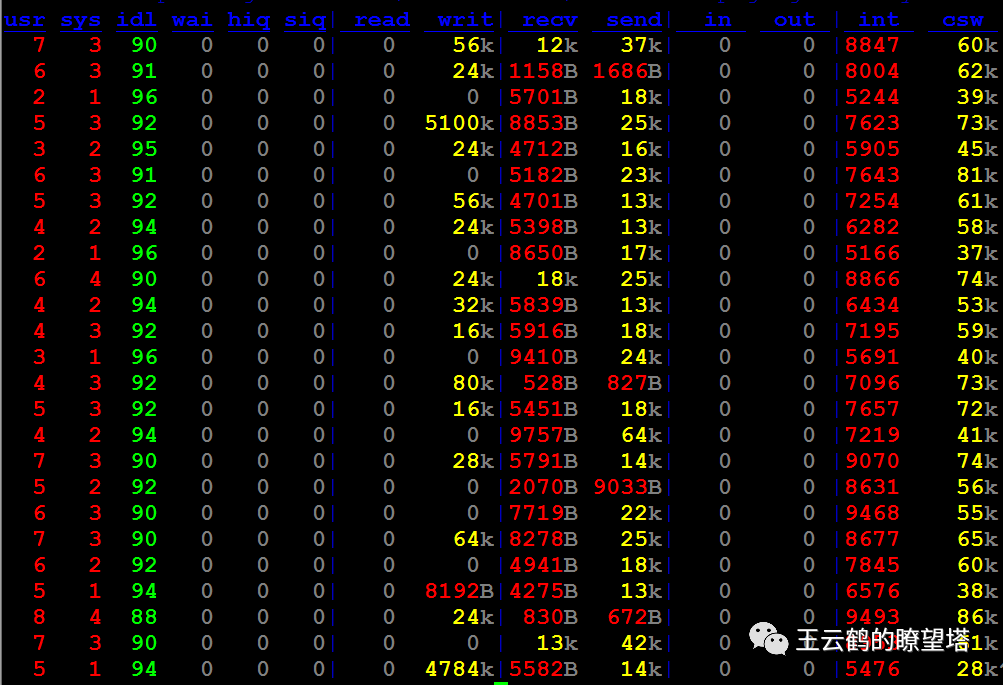 各位看完后一定很愤怒,CPU Util,CPU Load,磁盘IO和网络IO指标都很低,毫无性能压力的服务器指标,有啥好看的(其实是有指标异常的)。
冰块中的火 别急,在毫无波澜的服务器上,mysql实例内部已经翻山倒海了,请看下图:
各位看完后一定很愤怒,CPU Util,CPU Load,磁盘IO和网络IO指标都很低,毫无性能压力的服务器指标,有啥好看的(其实是有指标异常的)。
冰块中的火 别急,在毫无波澜的服务器上,mysql实例内部已经翻山倒海了,请看下图:
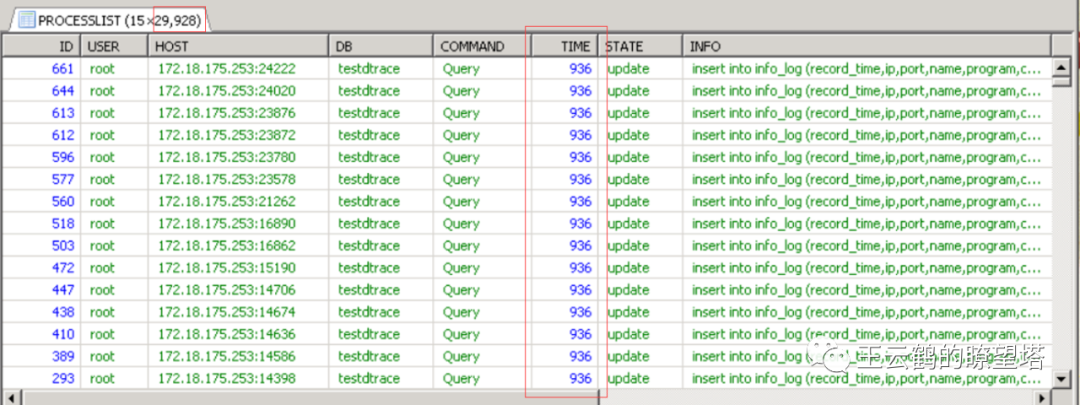 有接近三万的活动连接,所有的连接都是执行非常简单的单条insert语句。但是,这些sql语句,都已经执行了十多分钟还未结束。而且再过不到十分钟,mysql实例将实现自我涅槃(自动重启)。 简直就是在冰块中熊熊燃烧着一团火。
3.故障起因 某日,业务开发突然反馈,应用出现大量无法建立新连接的报错。
连接数爆满 登录上mysql实例发现,最大3万的连接数,已经满的不能再满了。
有接近三万的活动连接,所有的连接都是执行非常简单的单条insert语句。但是,这些sql语句,都已经执行了十多分钟还未结束。而且再过不到十分钟,mysql实例将实现自我涅槃(自动重启)。 简直就是在冰块中熊熊燃烧着一团火。
3.故障起因 某日,业务开发突然反馈,应用出现大量无法建立新连接的报错。
连接数爆满 登录上mysql实例发现,最大3万的连接数,已经满的不能再满了。
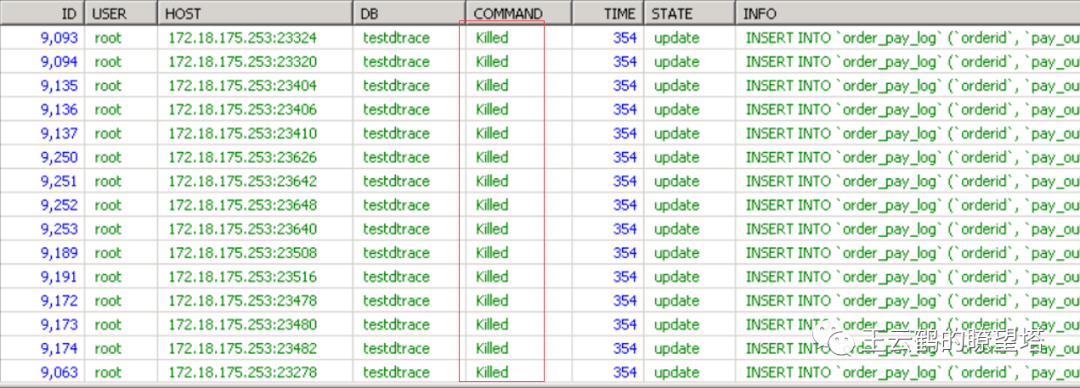 涅槃的实例 20多分钟后,mysql实例突然自动重启了。 整个过程中,服务器性能指标都很正常,所以服务器层面没有任何报警出现。 简单来讲,就是服务器说我很轻松,很happy, mysql实例说AWSL。
4.初步调查 瞬间暴涨到3万个并发连接,一定是应用突然进来了大量访问,开发也确认了,业务量是有所上升。
涅槃的实例 20多分钟后,mysql实例突然自动重启了。 整个过程中,服务器性能指标都很正常,所以服务器层面没有任何报警出现。 简单来讲,就是服务器说我很轻松,很happy, mysql实例说AWSL。
4.初步调查 瞬间暴涨到3万个并发连接,一定是应用突然进来了大量访问,开发也确认了,业务量是有所上升。
各位看完后一定很愤怒,CPU Util,CPU Load,磁盘IO和网络IO指标都很低,毫无性能压力的服务器指标,有啥好看的(其实是有指标异常的)。
冰块中的火 别急,在毫无波澜的服务器上,mysql实例内部已经翻山倒海了,请看下图:
有接近三万的活动连接,所有的连接都是执行非常简单的单条insert语句。但是,这些sql语句,都已经执行了十多分钟还未结束。而且再过不到十分钟,mysql实例将实现自我涅槃(自动重启)。 简直就是在冰块中熊熊燃烧着一团火。
3.故障起因 某日,业务开发突然反馈,应用出现大量无法建立新连接的报错。
连接数爆满 登录上mysql实例发现,最大3万的连接数,已经满的不能再满了。
实例中全部都是活动连接
大量执行简单的单行insert
没有行/表锁阻塞
涅槃的实例 20多分钟后,mysql实例突然自动重启了。 整个过程中,服务器性能指标都很正常,所以服务器层面没有任何报警出现。 简单来讲,就是服务器说我很轻松,很happy, mysql实例说AWSL。
4.初步调查 瞬间暴涨到3万个并发连接,一定是应用突然进来了大量访问,开发也确认了,业务量是有所上升。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2047
2047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









