





YOLO系列对象检测算法,算是人工智能技术领域的一匹黑马,当开发者宣布不再为YOLO系列检测算法更新时,很多开发者瞬间失去了”精神食粮“。突然,当YOLOV4检测算法发布的时候,让很多开发者喜出望外。

YOLOV4对象检测
YOLOV4对象检测算法综述:
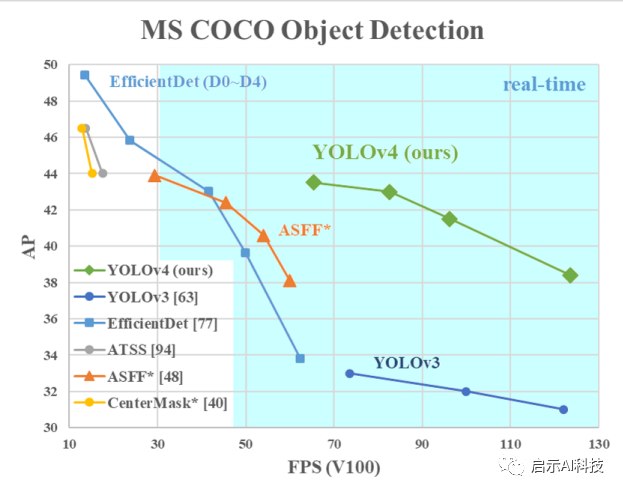
COCO 模型上的检测数据
43.5%mAP+65FPS 精度速度最优平衡,YOLOV4无论是在速度上,还是在精度上,都绝对碾压很多对象检测算法,在论文中,作者也是采用了大量的调优算法来加速YOLOV4的检测模型
加权残差连接(WRC)
跨阶段部分连接(CSP)
跨小批量标准化(CmBN)
自对抗训练(SAT)
Mish激活
马赛克数据增强
CmBN
DropBlock正则化
CIoU Loss
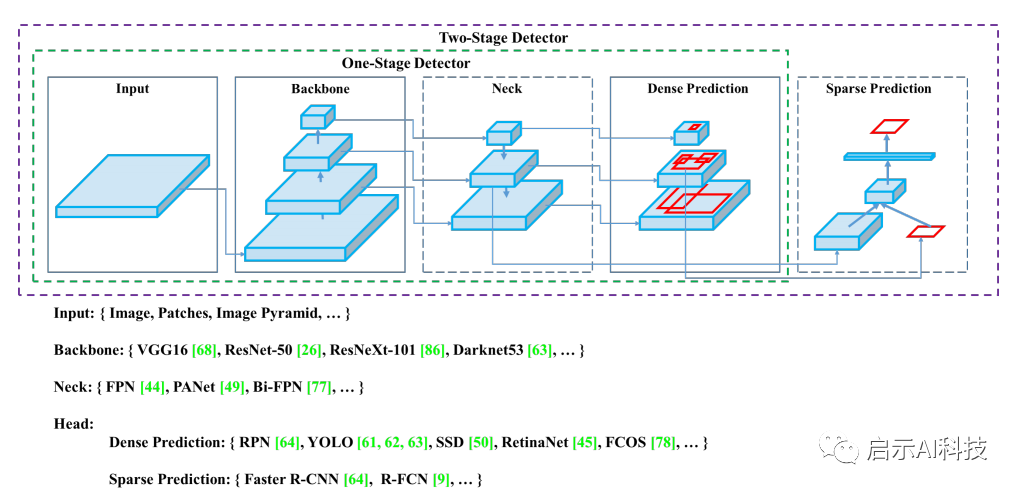
对象检测
模型中的名词
Input:算法的输入,包括整个图像,一个patch,或者是image pyramid
Backbone:可以理解为提取图像特征的部分,可以参考经训练好的网络,例如(VGG16,ResNet-50, ResNeXt-101, Darknet53等)
Neck:特征增强模块,前面的backbone已经提取到了一些相关的浅层特征,由这部分对backbone提取到的浅层特征(low-level feature)进行加工,增强,从而使得模型学到的特征是想要的特征。
Head:检测头。如果想直接得到bbox,那就可以接conv来输出结果,例如Yolo,SSD
因此,一个检测算法可以理解为:
Object Detection = Input+Backbone + Neck + Head
Bag of freebies
什么叫Bag of freebies?在目标检测中是指:用一些比较有用的训练技巧来训练模型,从而使得模型取得更好的准确率但是不增加模型的复杂度,也就不增加推理(inference)是的计算量(cost)。在目标检测中,提到bag of freebies,首先会想到的 就是Data augmentation。
Data augmentation
目的在于增加训练样本的多样性,使得检测模型具有高的鲁棒性。常见的数据增强方式包括两个方面:几何增强以及色彩增强。
几何增强包括:随机翻转(水平翻转较多,垂直翻转较少),随机裁剪(crop),拉伸,以及旋转。
色彩增强包括:对比度增强,亮度增强,以及较为关键的HSV空间增强。
.Bag of specials
什么叫做bag of specials:就是指一些plugin modules(例如特征增强模型,或者一些后处理),这部分增加的计算量(cost)很少,但是能有效地增加物体检测的准确率,我们将这部分称之为Bag of specials
架构选择

架构选择
一个模型的分类效果好不见得其检测效果就好,想要检测效果好需要以下几点:
更大的网络输入分辨率——用于检测小目标
更深的网络层——能够覆盖更大面积的感受野
更多的参数——更好的检测同一图像内不同size的目标
为了增大感受野,作者使用了SPP-block,使用PANet代替FPN进行参数聚合以适用于不同level的目标检测。
YOLOv4的架构:
backbone:CSPResNext50
additional block:SPP-block
path-aggregation neck:PANet
heads:YOLOv3的heads
YOLOV4的改进,作者不仅增加了以上的优化算法,更是改进了其他方面的技术,比如:
一种新的数据增强Mosaic法和Self-AdversarialTraining 自对抗训练法。

Mosaic法和Self-AdversarialTraining
应用遗传算法选择最优超参数。
改进SAM,改进PAN,和交叉小批量标准化(CmBN),使设计适合于有效的训练和检测
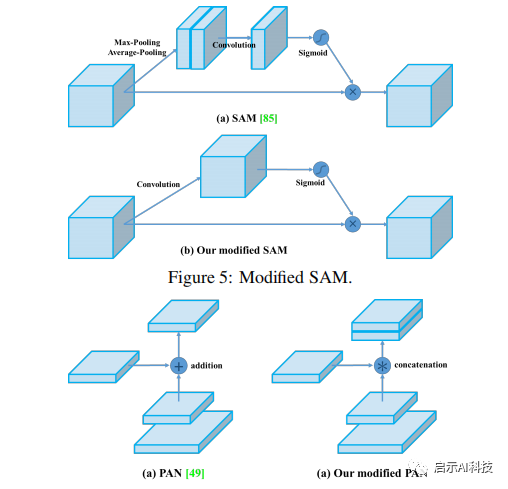
SAM,PAN
更加详细的技术,大家可以参考作者的论文以及GitHub源代码进行分享学习
python+opencv 实现YOLOV4

python+opencv 实现YOLOV4
YOLOV4的实现,除了作者分享的Darknet之外,现在还有了tensorflow、Pytorch、keras等等方法的实现,但是始终没有比较简答的代码实现(毕竟tensorflow、Pytorch、keras技术,不是很好掌握)
opencv4.4版本的发布,宣布支持最新的YOLOV4对象检测算法,同时还优化了大量的工作
本部分代码需要升级一下你的opencv版本到4.4
YOLOV4 图片识别
模型初始化
import numpy as np
import timeimport cv2import oslabelsPath = "yolo-coco/coco.names"
LABELS = Nonewith open(labelsPath,'rt') as f:
LABELS = f.read().rstrip('\n').split("\n")
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),dtype="uint8")
weightsPath = "yolo-coco/yolov4.weights"
configPath = "yolo-coco/yolov4.cfg"
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)1-5行:首先我们导入第三方库
7-10行:我们加载YOLOV4在COCO训练集上的对象名称
12-13行:初始化随机的颜色,这里主要是为后续检测到不同的对象,进行不同颜色的边框画图
15-17:初始化YOLOV4的模型,cv2.dnn.readNetFromDarknet(configPath, weightsPath)函数来加载模型的CFG以及weights参数
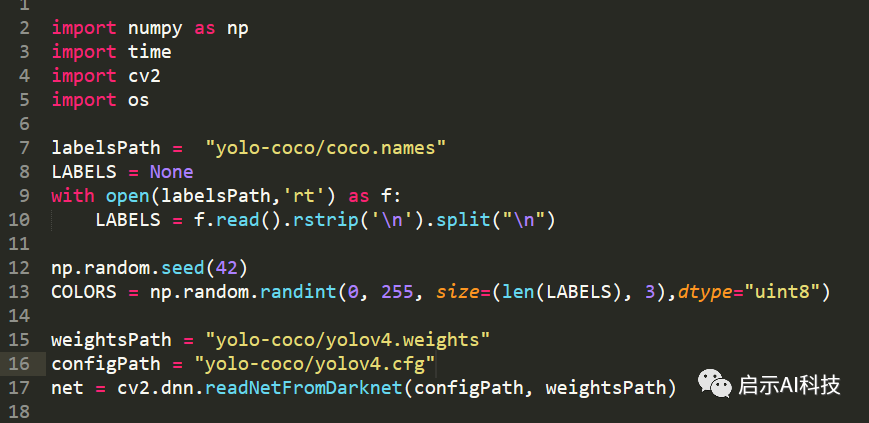
代码截图
加载图片进行神经网络检测
image = cv2.imread("images/3.jpg")
(H, W) = image.shape[:2]
ln = net.getLayerNames()ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),swapRB=True, crop=False)
net.setInput(blob)start = time.time()
layerOutputs = net.forward(ln)end = time.time()
print("[INFO] YOLO took {:.6f} seconds".format(end - start))19-20行:输入图片,获取图片的长度与宽度
22-28行:计算图片的blob值,输入神经网络,进行前向反馈预测图片,只不过net.forward里面是ln, 神经网络的所有out层,这里我们定义了一个time函数,用来计算YOLOV4的检测时间
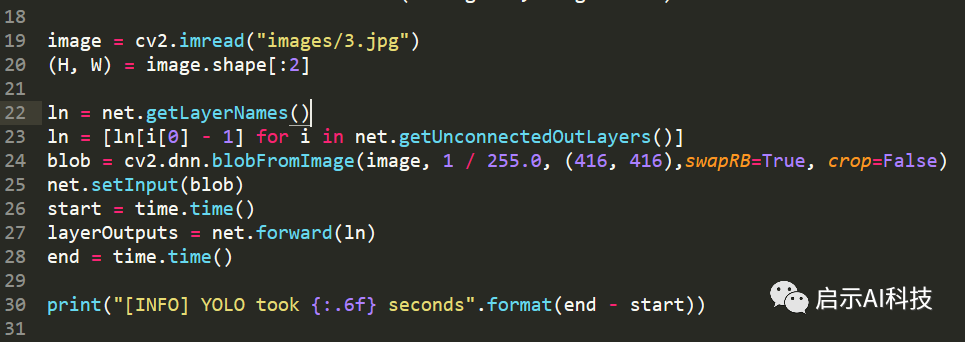
代码截图
遍历检测结果
boxes = []
confidences = []classIDs = []for output in layerOutputs:
for detection in output:
scores = detection[5:]
classID = np.argmax(scores) confidence = scores[classID] if confidence > 0.5:
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
32-34:首先初始化一些参数,主要用来存检测到的结果数据
36-42:遍历所有的检测层,提取检测到的图片对象置信度以及label ID
44-53:我们过滤到置信度小于0.5的对象,提取大于0.5置信度的对象,分别计算每个检测对象的BOX、置信度以及label ID,并保存在如下先前建立的初始化参数list里面
boxes = []
confidences = []
classIDs = []
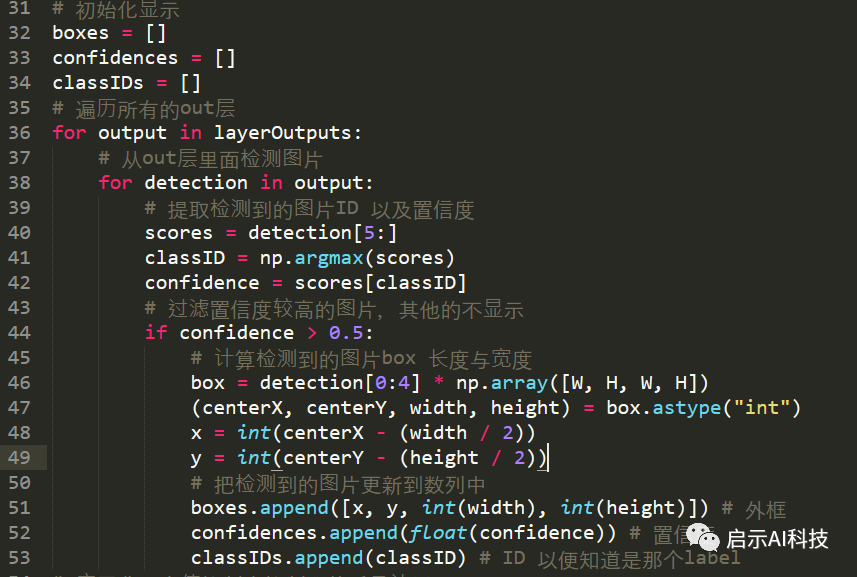
代码截图
通过以上代码便实现了python的YOLOV4对象检测,但是检测的结果并不理想,对于每个对象,Yolo4 会框出 3 个左右的区域,但是我们只需要显示出最合适的区域。非最大值抑制算法,就是搜索出局部最大值,将置信度最大的框保存,其余删除。
非最大值抑制来定义最大的边框
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5,0.4)
if len(idxs) > 0: for i in idxs.flatten(): (x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in COLORS[classIDs[i]]] cv2.rectangle(image, (x, y), (x + w, y + h), color, 2) text = "{}: {:.4f}".format(LABELS[classIDs[i]], confidences[i]) cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
0.5, color, 2)cv2.imshow("Image", image)cv2.waitKey(0)最后,我们使用非最大值抑制算法,把每个对象的最大边框显示出来,以便我们检测模型的结果
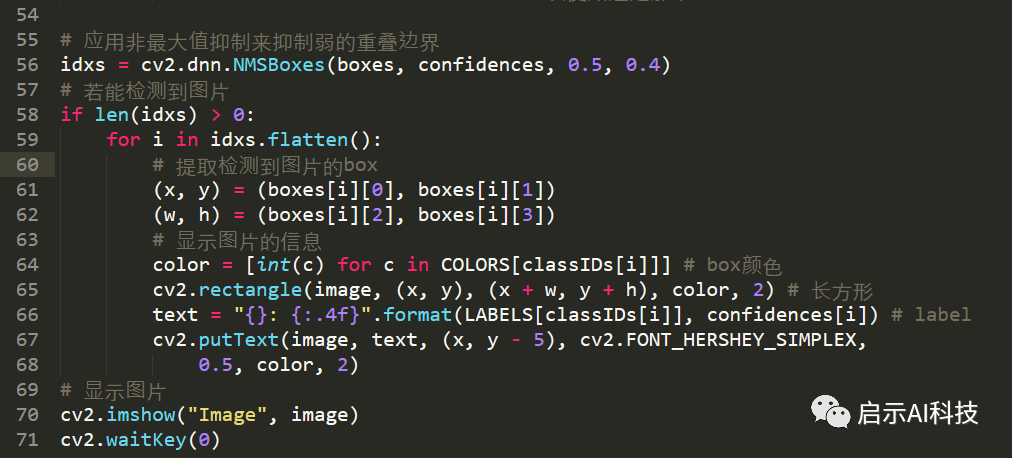
代码截图
以上便是完整的python opencv实现YOLOV4的代码,本部分代码与YOLOV3的实现类似,小伙伴们可以参考小编往期的文章关于YOLOV3的介绍,最后我们运行一下代码,看看实现检测的效果

YOLOV4
YOLOV4的检测,用起来,确实速度有了很大的提示,就如上图一样,检测只用了1.3S左右,速度与精度的结合,美中不足的地方是上图的人的置信度才0.777
下期预告
当然YOLOV4检测算法完全可以使用在视频检测,以及摄像头的实时对象检测,本部分代码我们下期分享















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









