







1.索引(index)是帮助MySQL高效获取数据的数据结构(有序)。


2.MySQL为什么选择B+树,而不选二叉树或者红黑树?
首先我们来了解一下二叉树,二叉树在插入数据的时候是顺序插入的,假如我们插入的是一个有序的数组,这时,二叉树其实就是一个链表,如果我们要查的数据刚好是最底层的那个,查询次数依然是n,查询效率依然很差;再来说一下红黑树,红黑树本质也是一个二叉树,我们通常也称红黑树为二叉平衡树,红黑树有效地解决了有序数组顺序插入的问题,但是,当数据量足够大时,红黑树的节点就会变得很多,层级很深,检索效率依然不高。

红黑树上存在的问题就是大数据量的时候,检索效果不理想,这时候我们就想到,能不能在一个节点上存多个数据呢?这样,不就解决了红黑树层级太深的问题了吗?这时候就产生了B树,B树在一个节点上存储多个数据,有效地减少了层级。

那MySQL选择的是B树吗?答案是否定的。相对于B树,InnoDB选择的是B+树。从B树的结构我们可以看出,B树是在每一个节点存储数据的,每个节点都是存放在页(page)中的,而页的大小固定为16K,如果我们在页中只存放索引,而不存放数据,我们就能存放更多的索引,可以把层级做得更少,检索效率更高。显然,相同大数据量的情况下,B树的层级会比B+树更多,索引效果更差。
B+树的特点是所有节点都存在于叶子节点,非叶子节点只做索引,不存储数据,只有叶子节点才存储数据,这样,在同一页中就能存放更多的索引。此时的B+还只是一个单向链表的结构。

但B+树还不是最佳方案,MySQL对B+树进一步优化,增加了双向链表,提高了区间访问的性能。

3.hash索引
hash索引是采用特定的hash算法,将键值换算成hash值,映射到对应的槽位上,然后存储在hash表中。当进行检索时,如果不考虑存在hash碰撞的情况下,hash检索的效率O(1),检索效率高于B+树。
当存在hash碰撞时,hash索引的检索效率要加上链表查询,这时候就不是O(1)了。
hash索引不支持范围查询,只支持等值匹配。
hash索引也不支持排序操作。
4.索引的分类


①如果表存在主键,则主键索引就是聚集索引;
②如果表不存在主键,但存在唯一索引,则第一个唯一索引是聚集索引;
③如果表不存在主键,且不存在唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
5,回表查询

如上图所示,上方的索引是聚集索引,下方是二级索引。聚集索引的叶子节点存放的是行数据(row),而二级索引叶子节点存放的是字段对应的主键id。通过二级索引查询时,二级索引会先查询对应的主键id,然后回到聚集索引,通过id查到对应的行数据,这样的过程我们称为回表查询。这就是为什么主键索引查询通常优于一般索引查询的原因。
6.InnoDB主键索引的B+树高度为多高?
一页大小是固定16K,假设一条数据1K,则一页可以存放16条数据;指针占6个字节,主键我们假设为bigint为8个字节,指针比主键多一个(估算忽略不计),公式为n=(16*1024)/(6+8),n约等于1170,则指针为1171个。当树的高度为2的时候,树最多可以存放可以存放1171*16=18736,当树的高度为3时,树最多可以存放1171*1171*16=21939856条数据。
当然,这一切都是基于假设,你可能会说,我数据如果不止1K呢?我主键的数据类型如果不是bigint呢?这就是为什么你们公司的DB不建议你们使用UUID作为主键索引,而强烈要求你们使用自增id作为主键索引的原因。这个假设是基于规范的假设,影响因素只在数据大小的差异,但三层的B+树几乎可以满足所有的数据要求,因为如果数据量再大点,我们通常就会考虑分库分表的操作了,这是后话了;如果有人非要钻牛角尖,那就再加一层上去呗。
7.索引的语法
7.1、创建索引
create [unique|fulltext] index index_name on table_name (index_col_name,...);
--[unique|fulltext]可加可不加,指定索引类型;
--index_name索引名称;
--table_name表名,其后接字段名,可以是一个字段,也可是多个字段7.2、查看索引
show index from table_name;7.3、删除索引
drop index index_name on table_name;以下为创建索引及查看索引的展示
8.SQL性能分析
8.1.查看SQL的执行频率
show global status like 'Com_______';
--一共有7个下划线‘_’
圈出来的这几个是不是很熟悉,我们一眼就能看出,我们主要执行的select操作,目标是当前数据库。
8.2、慢查询日志
慢查询日志记录所有执行时间超过指定参数(long_query_time,默认10S,且默认没开启)的所有SQL语句的日志。在MySQL的配置文件(/ect/my.cnf)中开启。
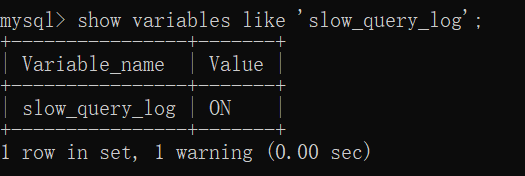
在配置文件中加上
#开启慢查询日志
slow_query_log=1
#设置超时记录时间,执行超过5秒记录
long_query_time=58.3、profile详情
show profiles能够在做SQL优化时帮助我们了解具体耗时,通过have_profiling参数可以查看当前MySQL是否支持profile操作。
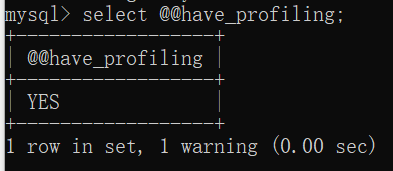
profiling默认是关闭的,接着我们要去打开它。
接着我们看一下如何使用profile;
--查看所有sql的耗时
select profiles;
--查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
--查看指定query_id的SQL语句cpu使用情况
show profile cpu for query query_id;

我们可以清楚看到我执行的三条sql的耗时,user表我给id建了索引,第三条执行效率明显优于第四条,这不是这里要讲的,就此打住,我们看一下第三条各个阶段的耗时情况。
















 2820
2820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









